 2020-01-15
2020-01-15 688
688В.П. Носко
Эконометрика для начинающих
Основные понятия, элементарные методы, границы применимости,
интерпретация результатов
Москва
2000
Институт экономики переходного периода
Основан в 1992 г.
Учредители: Академия народного хозяйства
при Правительстве РФ
Директор: Е.Т.Гайдар
Носко Владимир Петрович - кандидат физико-математических наук, старший научный сотрудник механико-математического факультета Московского государственного университета им. М.В.Ломоносова. Автор более 40 научных работ, соавтор учебного пособия “Основные понятия и задачи математической статистики”.
Преподает эконометрику с 1994 года. В настоящее время читает курсы лекций по эконометрике на механико-математическом факультете МГУ, на факультете менеджмента Международного университета (г. Москва) и в Институте экономики переходного периода.
Настоящая работа издана на средства гранта, предоставленного Институту экономики переходного периода Агентством США по международному развитию
Компьютерный дизайн: А. Астахов
ISBN 5-93255-027-9
Лицензия на издательскую деятельность Серия ИД № 02079от 19 июня 2000 г.
103918, Москва, Газетный пер., 5
Тел. (095) 229–6413, FAX (095) 203–8816
E-MAIL – root@iet.ru, WEB Site – http://www.iet.ru
© Институт экономики переходного периода, 2000.
ОГЛАВЛЕНИЕ
Предисловие................................................................................... 6
Часть 1. Оценивание и подбор моделей связи между
переменными без привлечения
вероятностно-статистических методов....................................... 7
1.1. Эконометрика и ее связь с экономической теорией............... 7
1.2. Две переменные: меры изменчивости и связи..................... 10
1.3. Метод наименьших квадратов. Прямолинейный
характер связи между двумя экономическими
факторами............................................................................... 18
1.4. Свойства выборочной ковариации, выборочной
дисперсии и выборочного коэффициента
корреляции.............................................................................. 34
1.5. «Обратная» модель прямолинейной связи........................... 40
1.6. Пропорциональная связь между переменными.................... 43
1.7. Примеры подбора линейных моделей связи между
двумя факторами. Фиктивная линейная связь...................... 49
1.8. Очистка переменных. Частный
коэффициент корреляции...................................................... 60
1.9. Процентное изменение факторов в линейной
модели связи........................................................................... 62
1.10. Нелинейная связь между переменными.............................. 66
1.11. Пример подбора моделей нелинейной связи,
сводящихся к линейной модели............................................ 73
1.12. Линейные модели с несколькими
объясняющими переменными................................................ 80
Часть 2. Статистические выводы при стандартных
предположениях о вероятностной структуре
ошибок в линейной модели наблюдений................................. 85
2.1. Вероятностное моделирование ошибок................................ 85
2.2. Гауссовское (нормальное) распределение ошибок в линейной модели наблюдений 92
2.3. Числовые характеристики случайных величин
и их свойства.......................................................................... 98
2.4. Нормальные линейные модели с несколькими
объясняющими переменными.............................................. 104
2.5. Нормальная множественная регрессия: доверительные
интервалы для коэффициентов........................................... 113
2.6. Доверительные интервалы для коэффициентов:
реальные статистические данные....................................... 118
2.7. Проверка статистических гипотез
о значениях коэффициентов................................................. 126
2.8. Проверка значимости параметров линейной регрессии
и подбор модели с использованием F-критериев............... 136
2.9. Проверка значимости и подбор модели с
использованием коэффициентов детерминации.
Информационные критерии................................................. 147
2.10. Проверка гипотез о значениях коэффициентов:
односторонние критерии..................................................... 158
2.11. Некоторые проблемы, связанные с проверкой
гипотез о значениях коэффициентов.................................. 164
2.12. Использование оцененной модели для
прогнозирования................................................................... 172
Часть 3. Проверка выполнения стандартных предположений
об ошибках в линейной модели наблюдений. Коррекция
статистических выводов при нарушении стандартных
предположений об ошибках.................................................... 180
3.1. Проверка адекватности подобранной модели
имеющимся статистическим данным:
графические методы............................................................. 180
3.2. Проверка адекватности подобранной модели имеющимся
статистическим данным: формальные статистические
процедуры............................................................................. 194
3.3. Неадекватность подобранной модели:
примеры и последствия........................................................ 204
3.4. Коррекция статистических выводов при наличии
гетероскедастичности (неоднородности
дисперсий ошибок)............................................................... 214
3.5. Коррекция статистических выводов при
автокоррелированности ошибок......................................... 223
3.6. Коррекция статистических выводов при наличии
сезонности. Фиктивные переменные................................... 235
Заключение................................................................................. 247
Список литературы................................................................... 248
Алфавитный указатель............................................................. 249
ПРЕДИСЛОВИЕ
Предлагаемое учебное пособие имеет своей целью обеспечить базу для изучения вводного полугодового курса эконометрики, когда в распоряжении преподавателя имеется всего порядка 12 лекций и некоторое количество часов практических занятий. При этом от читателя не требуется никаких предварительных знаний из теории вероятностей и математической статистики. Что касается математического анализа и линейной алгебры, то желательно, чтобы читатель имел хотя бы некоторое представление о производной и интеграле, а также о матрицах и операциях над ними. Соответственно, акценты в изложении смещаются в сторону разъяснения базовых понятий и основных процедур статистического анализа данных с привлечением большого количества иллюстративных примеров. В этом отношении данное учебное пособие близко по духу к имеющейся в русском переводе книге К. Доугерти «Введение в эконометрику» (1997), которая предназначена для изучения годового курса эконометрики и которую можно рекомендовать для последующего изучения вопросов, не охваченных в рамках настоящего пособия.
С целью постепенного введения студентов в круг понятий и методов эконометрики, в первой части пособия вообще не используются понятия теории вероятностей и математической статистики. И только когда дальнейшее игнорирование этих понятий в процессе анализа данных становится попросту невозможным, дается необходимый минимум сведений из этих дисциплин. Вторая часть пособия посвящена построению и статистическому анализу линейных регрессионных моделей при классических предположениях о модели наблюдений. В третьей части рассматриваются графические и формальные статистические методы выявления ряда нарушений классических предположений и методы коррекции статистических выводов при обнаружении таких нарушений.
Пособие написано на основании курса лекций, который читался автором на протяжении ряда лет в Международном университете (г. Москва), и лекций для аспирантов Института экономических проблем переходного периода.
ЧАСТЬ 1. ОЦЕНИВАНИЕ И ПОДБОР МОДЕЛЕЙ СВЯЗИ МЕЖДУ ПЕРЕМЕННЫМИ БЕЗ
ПРИВЛЕЧЕНИЯ ВЕРОЯТНОСТНО-СТАТИСТИЧЕСКИХ МЕТОДОВ
ЭКОНОМЕТРИКА И ЕЕ СВЯЗЬ С ЭКОНОМИЧЕСКОЙ ТЕОРИЕЙ
Эконометрика (Econometrics ) - совокупность методов анализа связей между различными экономическими показателями (факторами) на основании реальных статистических данных с использованием аппарата теории вероятностей и математической статистики. При помощи этих методов можно выявлять новые, ранее не известные связи, уточнять или отвергать гипотезы о существовании определенных связей между экономическими показателями, предлагаемые экономической теорией.
Пусть, например, мы имеем данные о размерах располагаемого дохода (disposable personal income) DPI и расходов на личное потребление (personal consumption) C для  семейных хозяйств, так что
семейных хозяйств, так что  и
и  , соответственно, представляют располагаемый доход и расходы на личное потребление
, соответственно, представляют располагаемый доход и расходы на личное потребление  -го семейного хозяйства.
-го семейного хозяйства.
Простейшей моделью связи между  и
и 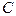 является линейная модель связи
является линейная модель связи

где  - некоторая постоянная величина, 0 < < 1, характеризующая в данном круге семейных хозяйств их склонность к потреблению, связанную с традициями и привычками, а
- некоторая постоянная величина, 0 < < 1, характеризующая в данном круге семейных хозяйств их склонность к потреблению, связанную с традициями и привычками, а  -“ автономное потребление “.
-“ автономное потребление “.
Однако, если разместить на плоскости в прямоугольной системе координат точки  с абсциссами и ординатами (такое расположение точек называется диаграммой рассеяния - scatterplot), то, как правило, эти точки вовсе не будут лежать на одной прямой вида
с абсциссами и ординатами (такое расположение точек называется диаграммой рассеяния - scatterplot), то, как правило, эти точки вовсе не будут лежать на одной прямой вида  соответствующей линейной модели связи. Вместо этого, они будут образовывать облако рассеяния, вытянутое в некотором направлении (см. Рис.1.1). В таком случае соотношение между
соответствующей линейной модели связи. Вместо этого, они будут образовывать облако рассеяния, вытянутое в некотором направлении (см. Рис.1.1). В таком случае соотношение между  и принимает форму
и принимает форму

(модель наблюдений), где слагаемое

представляет отклонение реально наблюдаемых расходов на потребление от значения  предсказываемого гипотетической линейной моделью связи для - го семейного хозяйства. Эти отклонения отражают совокупное влияние на конкретные значения множества дополнительных факторов, не учитываемых принятой моделью связи.
предсказываемого гипотетической линейной моделью связи для - го семейного хозяйства. Эти отклонения отражают совокупное влияние на конкретные значения множества дополнительных факторов, не учитываемых принятой моделью связи.
Рис. 1.1

Диаграмма рассеяния на рис.1.1 соответствует данным о годовом располагаемом доходе и годовых расходах на личное потребление (в 1999 г., в условных единицах) 20 семей. Эти данные представлены в таблице 1.1.
Табл. 1.1
| i | DPI | C | I | DPI | C | |
| 1 | 2508 | 2406 | 11 | 2435 | 2311 | |
| 2 | 2572 | 2464 | 12 | 2354 | 2278 | |
| 3 | 2408 | 2336 | 13 | 2404 | 2240 | |
| 4 | 2522 | 2281 | 14 | 2381 | 2183 | |
| 5 | 2700 | 2641 | 15 | 2581 | 2408 | |
| 6 | 2531 | 2385 | 16 | 2529 | 2379 | |
| 7 | 2390 | 2297 | 17 | 2562 | 2378 | |
| 8 | 2595 | 2416 | 18 | 2624 | 2554 | |
| 9 | 2524 | 2460 | 19 | 2407 | 2232 | |
| 10 | 2685 | 2549 | 20 | 2448 | 2356 |
Предложив для описания имеющихся статистических данных модель, учитывающую указанные отклонения от теоретической модели линейной связи между и (модель наблюдений ), мы неизбежно сталкиваемся с вопросом о том, каковы значения и  в этой модели. И с этого момента попадаем в поле деятельности эконометрики, предлагающей различные методы оценивания параметров экономических моделей по имеющимся статистическим данным, а также методы использования оцененной модели для целей экономического прогнозирования и проведения рациональной экономической политики. Кроме того, методы эконометрики дают возможность подбора подходящей модели, адекватной имеющимся данным, в ситуации, когда в распоряжении исследователя нет ясной экономической теории, описывающей поведение интересующих его отдельных экономических показателей и связи между различными показателями.
в этой модели. И с этого момента попадаем в поле деятельности эконометрики, предлагающей различные методы оценивания параметров экономических моделей по имеющимся статистическим данным, а также методы использования оцененной модели для целей экономического прогнозирования и проведения рациональной экономической политики. Кроме того, методы эконометрики дают возможность подбора подходящей модели, адекватной имеющимся данным, в ситуации, когда в распоряжении исследователя нет ясной экономической теории, описывающей поведение интересующих его отдельных экономических показателей и связи между различными показателями.
1.2. ДВЕ ПЕРЕМЕННЫЕ: МЕРЫ
ИЗМЕНЧИВОСТИ И СВЯЗИ
В приводимой ниже таблице 1.2 указаны уровни безработицы (в %) среди белого и цветного населения США в период с марта 1968 г. по июль 1969 г. (месячные данные). В первом столбце расположены номера последовательных наблюдений ( для марта 1968 г.,
для марта 1968 г.,  =17 для июля 1969 г.), во втором столбце - значения
=17 для июля 1969 г.), во втором столбце - значения  уровня безработицы среди белого населения в -ом месяце, а в третьем - значения
уровня безработицы среди белого населения в -ом месяце, а в третьем - значения  уровня безработицы среди цветного населения в -ом месяце.
уровня безработицы среди цветного населения в -ом месяце.
Табл. 1.2
| i | BEL | ZVET | i | BEL | ZVET |
| 1 | 3.2 | 6.9 | 10 | 3.0 | 6.5 |
| 2 | 3.1 | 6.7 | 11 | 3.0 | 6.0 |
| 3 | 3.2 | 6.5 | 12 | 2.9 | 5.7 |
| 4 | 3.3 | 7.1 | 13 | 3.1 | 6.0 |
| 5 | 3.3 | 6.8 | 14 | 3.1 | 6.9 |
| 6 | 3.2 | 6.4 | 15 | 3.1 | 6.5 |
| 7 | 3.2 | 6.6 | 16 | 3.0 | 7.0 |
| 8 | 3.1 | 7.3 | 17 | 3.2 | 6.4 |
| 9 | 3.0 | 6.5 |
Рассмотрим, прежде всего, графики изменения уровней безработицы в обеих группах в течение указанного периода времени (Рис. 1.2).
Первое впечатление от просмотра этих графиков - уровень безработицы среди цветного населения существенно выше и изменяется со временем со значительными колебаниями; уровень безработицы среди белого населения изменяется плавно и в довольно узком диапазоне.
Рис. 1.2

Для того, чтобы использовать обозначения, соответствующие общепринятой практике, мы обозначим через  последовательно наблюдаемые уровни безработицы среди цветного населения, а через
последовательно наблюдаемые уровни безработицы среди цветного населения, а через  - соответствующие им уровни безработицы среди белого населения США, так что мы можем говорить о наблюдаемых значениях двух переменных: переменной
- соответствующие им уровни безработицы среди белого населения США, так что мы можем говорить о наблюдаемых значениях двух переменных: переменной  - уровня безработицы среди цветного населения, и переменной
- уровня безработицы среди цветного населения, и переменной 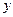 - уровня безработицы среди белого населения.
- уровня безработицы среди белого населения.
Наиболее простыми показателями, характеризующими последовательности  и , являются их средние значения (means)
и , являются их средние значения (means)


а также дисперсии (точнее, выборочные дисперсии - sample variances)


характеризующие степень разброса значений () вокруг своего среднего  (
( , соответственно), или вариабельность (изменчивость) этих переменных на множестве наблюдений. Отсюда обозначение Var (variance). Впрочем, более естественным было бы измерение степени разброса значений переменных в тех же единицах, в которых измеряется и сама переменная. Эту задачу решает показатель, называемый стандартным отклонением (standard deviance - Std.Dev.) переменной
, соответственно), или вариабельность (изменчивость) этих переменных на множестве наблюдений. Отсюда обозначение Var (variance). Впрочем, более естественным было бы измерение степени разброса значений переменных в тех же единицах, в которых измеряется и сама переменная. Эту задачу решает показатель, называемый стандартным отклонением (standard deviance - Std.Dev.) переменной  (переменной ), определяемый соотношением
(переменной ), определяемый соотношением

( соответственно).
соответственно).
Вычисления по указанным формулам приводят к значениям =  ,
,  =
=  ;
;  ,
,  =
=  . Иными словами, уровень безработицы среди цветного населения, в среднем, более, чем в два раза превышает уровень безработицы среди белого населения. Стандартные отклонения, соответственно, относятся приблизительно как 4:1, что указывает на гораздо более сильную изменчивость (“вариабельность”) уровня безработицы среди цветного населения. Размахи колебаний уровней равны, соответственно, 7.3 - 5.7 = 1.6 и 3.3 - 3.1 = 0.2.
. Иными словами, уровень безработицы среди цветного населения, в среднем, более, чем в два раза превышает уровень безработицы среди белого населения. Стандартные отклонения, соответственно, относятся приблизительно как 4:1, что указывает на гораздо более сильную изменчивость (“вариабельность”) уровня безработицы среди цветного населения. Размахи колебаний уровней равны, соответственно, 7.3 - 5.7 = 1.6 и 3.3 - 3.1 = 0.2.
Удобным графическим средством анализа данных является диаграмма рассеяния (scatterplot), на которой в прямоугольной системе координат располагаются точки  , i = 1, 2,..., n, где n - количество наблюдаемых пар значений переменных и . В нашем примере n = 17, и диаграмма рассеяния имеет вид
, i = 1, 2,..., n, где n - количество наблюдаемых пар значений переменных и . В нашем примере n = 17, и диаграмма рассеяния имеет вид
Рис. 1.3

Вытянутость облака точек на диаграмме рассеяния вдоль наклонной прямой позволяет сделать предположение о том, что существует некоторая объективная тенденция линейной связи между значениями переменных и , выражаемой соотношением

где — уровень безработицы среди цветного, а — среди белого населения. В то же время, указанное соотношение выражает всего лишь тенденцию: реально наблюдаемые значения  отличаются от значений
отличаются от значений  на величину
на величину
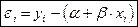
так что
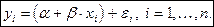
Последнее соотношение определяет линейную модель наблюдений, тогда как соотношение

определяет линейную модель связи между рассматриваемыми переменными.
Заметим, однако, что видимая степень проявления вытянутости облака точек на диаграмме рассеяния (при наличии линейной связи между переменными) существенно зависит от выбора единиц измерения переменных  и . Поэтому, во-первых, желательно при построении диаграммы выбирать масштабы и интервалы изменения переменных таким образом, чтобы диаграмма имела вид квадрата и чтобы на диаграмме имелись точки, достаточно близко расположенные к каждой из четырех границ квадрата. Во-вторых, желательно иметь какие-то числовые характеристики, которые отражали бы действительное наличие вытянутости облака точек вдоль наклонной прямой и не зависели от шкал, в которых представлены значения переменных.
и . Поэтому, во-первых, желательно при построении диаграммы выбирать масштабы и интервалы изменения переменных таким образом, чтобы диаграмма имела вид квадрата и чтобы на диаграмме имелись точки, достаточно близко расположенные к каждой из четырех границ квадрата. Во-вторых, желательно иметь какие-то числовые характеристики, которые отражали бы действительное наличие вытянутости облака точек вдоль наклонной прямой и не зависели от шкал, в которых представлены значения переменных.
Одна из характеристик такого рода связана с разбиением диаграммы рассеяния горизонтальной и вертикальной прямыми на 4 прямоугольника.
Разбивающие диаграмму прямые (секущие) проводятся через точку  так что если точка
так что если точка  лежит правее вертикальной секущей, то отклонение
лежит правее вертикальной секущей, то отклонение  имеет знак плюс, а если левее, то знак минус. Аналогично, если точка
имеет знак плюс, а если левее, то знак минус. Аналогично, если точка  лежит выше горизонтальной секущей, то отклонение
лежит выше горизонтальной секущей, то отклонение  имеет знак плюс, а если она расположена ниже этой секущей, то знак минус (см. Рис. 1.4).
имеет знак плюс, а если она расположена ниже этой секущей, то знак минус (см. Рис. 1.4).
Рис. 1.4

Пусть  — количество таких точек среди
— количество таких точек среди  , для которых
, для которых  и
и  (верхний правый прямоугольник);
(верхний правый прямоугольник);  — количество точек, для которых и
— количество точек, для которых и  (нижний правый прямоугольник);
(нижний правый прямоугольник);  — количество точек, для которых
— количество точек, для которых  и
и  (верхний левый прямоугольник);
(верхний левый прямоугольник);  - количество точек, для которых и (нижний левый прямоугольник). В нашем примере,
- количество точек, для которых и (нижний левый прямоугольник). В нашем примере,  ,
,  ,
,  (точки, соответствующие наблюдениям с номерами 6 и 17, имеют совпадающие координаты),
(точки, соответствующие наблюдениям с номерами 6 и 17, имеют совпадающие координаты),  (точки, соответствующие наблюдениям с номерами 9 и 10, имеют совпадающие координаты), так что количество точек с совпадающими знаками отклонений
(точки, соответствующие наблюдениям с номерами 9 и 10, имеют совпадающие координаты), так что количество точек с совпадающими знаками отклонений  и
и  равно
равно  , а количество точек, у которых знаки отклонений различны, равно
, а количество точек, у которых знаки отклонений различны, равно  .
.
Количество точек с совпадающими знаками отклонений от средних значений составляет 10/17=0.59, т. е. около 59% общего числа точек, и это служит некоторым указанием на наличие вытянутости облака точек в направлении прямой, имеющей положительный угловой коэффициент. Если бы большинство составляли точки с противоположными знаками отклонений от средних значений, то это служило бы объективным указанием на наличие вытянутости облака точек в направлении прямой, имеющей отрицательный угловой коэффициент. Последняя ситуация часто наблюдается при рассмотрении зависимости спроса на товар от его цены.
Более распространенным является определение степени выраженности линейной связи между произвольными переменными  и , принимающими значения
и , принимающими значения  и
и  ,
,  , посредством (выборочного) коэффициента корреляции (sample correlation coefficient)
, посредством (выборочного) коэффициента корреляции (sample correlation coefficient)

Величина  стоящая в числителе, определяется соотношением
стоящая в числителе, определяется соотношением

и называется (выборочной) ковариацией переменных и , так что, формально,


Если указанная тенденция выражена на диаграмме рассеяния довольно ясно, то значения  по абсолютной величине близки к единице (т. е. значения
по абсолютной величине близки к единице (т. е. значения  близки к +1 или к –1). Если же наличие линейной тенденции связи обнаруживается на диаграмме рассеяния с трудом, то тогда значения близки к нулю. Как мы увидим позднее, значения уже не зависят от выбора шкал измерения переменных и (если, конечно, эти шкалы линейны).
близки к +1 или к –1). Если же наличие линейной тенденции связи обнаруживается на диаграмме рассеяния с трудом, то тогда значения близки к нулю. Как мы увидим позднее, значения уже не зависят от выбора шкал измерения переменных и (если, конечно, эти шкалы линейны).
В нашем примере  ,
,  ,
,  , откуда находим
, откуда находим

т. е. получаем значение , расположенное приблизительно посередине между 0 и 1.
Замечание
Мы определили Var и Cov, деля соответствующие суммы квадратов на n- 1. Это имеет свое объяснение, которое пока выходит за рамки нашего обсуждения. Вместе с тем, в разных руководствах по эконометрике Var и Cov определяются по-разному. Деление на n - 1 используется, например, в книгах Доугерти (1997), Айвазяна и Мхитаряна (1998), тогда как в книге Магнуса, Катышева и Пересецкого (1997) соответствующие суммы квадратов делятся не на n - 1, а на n. К счастью, и Cov и Var будут играть у нас лишь вспомогательную роль, а величина более существенного для нас коэффициента корреляции rxy не зависит от того, каким из двух способов мы будем определять Var и Cov, лишь бы только при определении обеих этих характеристик использовался один и тот же способ.








