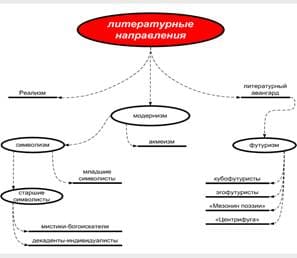
2014-02-02
2014-02-02 549
549Рассмотрим случайную переменную с множеством возможных значений (х1 х2,..., xN), принимаемых с вероятностями (P1, Р2,..., Pn), где Р, означает вероятность результата xi. Определим нижнюю границу средней длины кода. Мы знаем, что мерой информации для хi является log(1/Р). Поэтому в идеальном случае мы сможем представить значение xi - кодовым словом длины Li = log(l/Pi) бит. Однако в большинстве случаев log(l/Pi) не является целым числом, и лучшее, что мы можем сделать, — это выбрать ближайшее целое число Li такое что
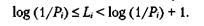
Умножая на Рi и суммируя по всем кодовым словам, получаем:
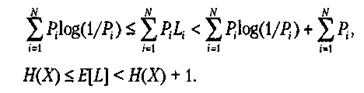
Таким образом, оптимальный код позволяет получить среднюю длину кода, не более чем на 1 бит превосходящую энтропию оригинального набора символов. Таким образом, энтропия случайной переменной X может интерпретироваться как минимальное среднее число битов, необходимых для отображения одного значения X.
Можно показать, что код Хаффмана удовлетворяет данному неравенству. Пример приводится в таблице. Средняя длина кода составляет 2,184, а энтропия равна 2,167. Обратите внимание на то, что не все отдельные кодовые слова удовлетворяют неравенству. Однако в среднем это неравенство выполняется.