 2014-02-02
2014-02-02 447
447В предыдущем пункте предполагалось, что следующий символ в последовательности не зависит от предыдущего символа. Однако если такая зависимость существует, тогда вероятности, связанные с блоками символов, меняются. Например, рассмотрим снова алфавит X из двух символов и предположим, что к нему применимы следующие переходные вероятности:

Таким образом, вероятность того, что за символом А последует символ А, равна 0,9; вероятность того, что за символом В последует символ А, равна 0,1 и т. д. Несложно доказать непротиворечивость матрицы переходов при вероятностях появления отдельных символов А и В, равных 0,8 и 0,2 соответственно.
Теперь разработаем код для алфавита Y, составленного из комбинаций этих символов по два. Мы получим:
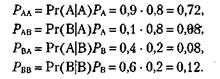
На уже рассмотренном рисунке (нижний граф)показан код Хаффмана для данного случая, а в средней части таблицы — полученная в результате статистика. Обратите внимание на то, что энтропия Y меньше, чем в случае, когда следующие друг за другом символы независимы (1,292 против 1,444). Поскольку вероятности для отдельных символов остались теми же самыми (Ра = 0,8, Рв = 0,2), то чем это объясняется? Ответ состоит в том, что вероятности переходов добавляют информацию. Когда становится известен первый символ последовательности, мы получаем больше информации о том, какой символ появится следующим. Поэтому неопределенность уменьшается, и суммарная энтропия также снижается. Другими словами, в последовательностях появляется избыточность. Так, например, существует значительная избыточность в предложениях на английском языке.
Для случая зависимых символов средняя длина кода равна 1,44, что дает эффективность 1,292/1,44 = 0,897. В нижней части таблицы показано, что произойдет, если проигнорировать переходные вероятности и предположить, что следующие друг за другом символы независимы даже в том случае, если они зависимы. В этом случае используются те же коды, что и для независимых символов (АА = 0, АВ =11, ВА= 100, ВВ =101). Однако теперь для второй по частоте комбинации ВВ используется самое длинное кодовое слово 101, поэтому средняя длина кодового слова оказывается равной 1,48, что больше средней длины, получавшейся при использовании оптимального кода Хаффмана.
Из этого обсуждения можно сделать вывод, что большей эффективности в сжатии данных можно достичь, кодируя данные большими блоками, а также учитывая зависимости данных.








