 2014-02-24
2014-02-24 1239
1239Голосовой аппарат человека представляет собой акустическую систему, состоящую из ротового и носового каналов, возбуждаемую квазипериодическими импульсными колебаниями голосовых связок и турбулентным шумом. Турбулентный шум образуется путем проталкивания воздуха через сужения в определенных областях голосового тракта. Голосовой аппарат, возбуждаемый указанными источниками, действует как линейный фильтр с изменяющимися во времени параметрами, на выходе которого формируется речевой сигнал. На коротких интервалах времени речевой сигнал можно аппроксимировать сверткой возбуждающего сигнала с импульсной характеристикой голосового тракта. На рис.1. изображена упрощенная модель формирования речевого сигнала. В соответствии с этой моделью вокализованные (звонкие) звуки формируются с помощью генератора импульсной последовательности, а фрикативные (шумовые) - с помощью генератора случайных чисел.
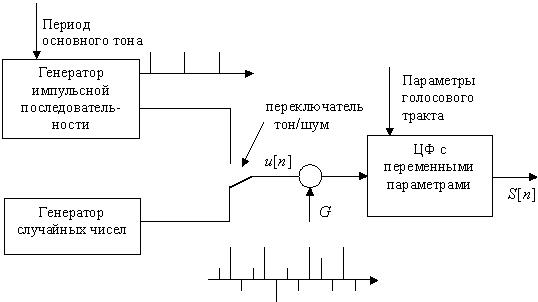
Рис.1. Цифровая модель формирования речевого сигнала.
Период следования импульсов на выходе генератора импульсной последовательности соответствует основному периоду возбуждения голосовыми связками. Генератор случайных чисел формирует шумовой сигнал с равномерной спектральной плотностью. Цифровой фильтр (ЦФ) с переменными параметрами аппроксимирует передаточные свойства голосового тракта. На временном интервале порядка 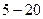 мс форма голосового тракта не меняется, поэтому характеристики ЦФ на данном интервале остаются постоянными. Амплитуда входного сигнала
мс форма голосового тракта не меняется, поэтому характеристики ЦФ на данном интервале остаются постоянными. Амплитуда входного сигнала 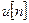 цифрового фильтра определяется коэффициентом усиления
цифрового фильтра определяется коэффициентом усиления 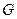 .
.
Вокализованные звуки представляют собой квазипериодические сигналы, гармоническая структура которых хорошо видна на графике кратковременного спектра. Фрикативные звуки имеют случайный характер и занимают более широкий частотный диапазон. Энергия вокализованных звуков речи намного больше, чем энергия фрикативных звуков. Структура кратковременного спектра вокализованных участков речи характеризуется наличием медленно меняющейся и быстро меняющейся составляющих. Быстро меняющаяся или пульсирующая составляющая обусловлена квазипериодическими колебаниями голосовых связок. Медленно меняющаяся составляющая связана с собственными (резонансными) частотами голосового тракта – формантами. В среднем насчитывается 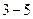 формант. Первые три форманты оказывают существенное влияние на синтез и восприятие вокализованных участков речи. Их частоты находятся ниже
формант. Первые три форманты оказывают существенное влияние на синтез и восприятие вокализованных участков речи. Их частоты находятся ниже 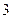 кГц. Форманты с более высокими частотами оказывают влияние на синтез и представление фрикативных звуков.
кГц. Форманты с более высокими частотами оказывают влияние на синтез и представление фрикативных звуков.
Рассмотренная цифровая модель формирования речевого сигнала характеризуется следующими параметрами: наличием классификатора вокализованных и невокализованных звуков (переключатель тон/шум), периодом основного тона, коэффициентом усиления , параметрами (коэффициентами) ЦФ.
На рассмотренной модели базируются многочисленные способы представления речевых сигналов: от простейшей периодической дискретизации речевого сигнала до оценок параметров модели, представленной на рис.1.
Выбор того или иного способа представления речевого сигнала определяется решаемой задачей, которые разделяются на три класса:
1. К первому классу относят задачи, связанные с анализом речи. Анализ речи является неотъемлемой частью систем распознавания речевых сигналов, а также систем идентификации дикторов по голосу.
2. Ко второму классу относят задачи, связанные с синтезом речи по тексту. Задачи такого типа возникают в многочисленных информационно-справочных системах.
3. В задачах, относящихся к третьему классу, выполняется анализ системы сжатия речевых сигналов с целью передачи речи по компьютерным сетям или по традиционным линиям связи.
Одним из перспективных направлений применения обработки речевых сигналов являются системы распознавания речи в сети Internet. В этом случае пользователь сети, используя телефон, может соединиться с программой распознавания речи, находящейся на сервере и транслирующей диалог в команды Web-сервера. Это позволяет получить доступ к распределенным информационным ресурсам сети по телефону. Данная технология, использующая методы цифровой обработки сигналов, базируется на использовании специального языка программирования Web-серверов VoxML (Voice Markup Language).
В дальнейшем рассмотрим основные способы цифрового представления и обработки речевых сигналов, применяемые как в задачах анализа речевых сигналов, так и в задачах синтеза.

