 2014-02-09
2014-02-09 2481
2481Экспериментальные данные обычно представляют собой результаты подсчета (измерения) некоторых характеристик (признаков) объектов (число ответов на данный вопрос, количество баллов в результате данного теста, оценки контрольной работы, время усвоения материала и т.д.), выбранных из большой совокупности объектов. Наблюдаемые в выборке значения x 1, x 2, …, xn случайной величины X (результаты измерений) называют вариантами. Если в выборке объема n элемент xi встречается ni раз, то число ni называется частотой элемента xi. Очевидно, что 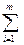 ni = n.
ni = n.
Выборка может быть записана в виде вариационного ряда или в виде статистического ряда.
■ Вариационный ряд выборки x 1, x 2, x 3,..., xn - способ ее записи (ранжирование), при котором элементы (варианты) упорядочиваются по величине, т.е. записываются в виде последовательности x 1', x 2', x 3',..., xn ', где x 1'£ x 2'£ x 3£... £ xn '.
■ Статистический ряд выборки – последовательность пар (xi,ni). Обычно статистический ряд записывается в виде таблицы, первая строка которой содержит элементы xi, а вторая - их частоты ni.
Пример 3.3. Записать в виде вариационного и статистического ряда выборку 5, 3, 7, 10, 5, 5, 2, 10, 7, 2, 7, 7, 4, 2, 4.
Решение. Объем выборки n = 15. Упорядочив элементы выборки по величине, получим вариационный ряд: 2, 2, 2, 3, 4, 4, 5, 5, 5, 7, 7, 7, 7, 10, 10. Статистический ряд в виде таблицы показан на рис. 3.4.
| xi | ||||||
| ni |
Рис. 3.4
При большом объеме выборки ее элементы объединяют в группы (разряды), представляя результаты измерений (наблюдений) в виде сгруппированного статистического ряда. Для этого интервал, содержащий все элементы выборки, разбивается на k частичных непересекающихся интервалов. Число интервалов группировки k находят по формуле Стерджеса: k = 1+3,32·lg n. Вычисления значительно упрощаются, если частичные интервалы имеют одинаковую ширину h = w / k. Нижняя граница первого интервала [ a 1; a 2) определяется по формуле a 1 = xmin – 0,5 h, верхняя граница первого интервала a 2 = a 1 + h. Нижняя граница второго интервала [ a 2; a 3) совпадает с верхней границей первого, верхняя граница второго интервала a 3 = a 2 + h и т.д. После того как частичные интервалы выбраны, определяют частоты - количество ni элементов выборки, попавших в i -й интервал (элемент, совпадающий с верхней границей интервала, относится к последующему интервалу).
Пример 3.4. В таблице 3.1 приведены экспериментальные данные, представляющие собой результаты тестирования (ТЕСТ №1), полученные группой школьников 2-х классов (50 человек). Представьте данную выборку в виде сгруппированного статистического ряда.
Решение. Объем выборки n = 50, размах выборки w = xmax – xmin = = 178 – 128 = 50. Число интервалов группировки k возьмем равным 7 (k» 1+3,32·lg50» 6,64). Тогда ширина интервалов h = w / k = 50/7» 7,14 (балла). Исходные данные определены с точностью 1 балл, поэтому округлим (обычно это делается в сторону увеличения) найденное значение h с учетом требуемой точности: возьмем h = 8 баллов. Найдем границы интервалов. Нижняя граница первого интервала [ a 1; a 2) a 1 = xmin – 0,5 h = 128 – 0,5·8 = 124, значит, верхняя граница первого интервала a 2 = a 1 + h = 124+8 = 132. Нижняя граница каждого следующего интервала совпадает с верхней границей предыдущего.
Результаты группировки сведены в таблицу 3.2.








