 2014-10-30
2014-10-30 1940
1940В соответствии со стандартом GSM каждый радиоканал используется для организации 8 цифровых каналов с временным разделением. Следовательно, если это будут стандартные ИКМ каналы, то потребуется скорость передачи в 512 кбит/с. Такую скорость передачи пользовательской информации по одному радиоканалу практически обеспечить невозможно. Выходом из создавшегося положения, с одной стороны, может служить увеличение плотности передаваемой информации, а с другой, - применение более сложных способов кодирования речевых сигналов, требующих передачи меньшего объема информации.
Плотность передачи информации является параметром,
характеризующим эффективность использования полосы частот системами с модуляцией цифровыми сигналами
= R/BW, где
R - скорость цифрового потока в бит/с;
BW - полоса занимаемая сигналом, в Гц.
При предъявлении высоких требований к скорости и качеству передачи информации, как правило, используется фазовая манипуляция. В GSM выбрана гауссовская манипуляция с минимальным сдвигом (GMSK), где индекс манипуляции - 0,3.
Снижение требуемой скорости цифрового потока каждого из каналов за счет использования более сложных способов кодирования должно осуществляться без значительного ухудшения качества. Наиболее низкая скорость передачи информации (1 - 5 кбит/с) требуется при использовании вокодеров. Однако при этом и очень низкое качество передачи речи. При декодировании получается “синтетический” речевой сигнал, что не дает возможности распознать кто говорит. Высокое качество передачи речи при незначительном снижении требований к скорости передачи информации можно получить при использовании различных модификаций импульсно-кодовой модуляции, но более сложной аппаратной реализации. Для того чтобы иметь высокое качество передачи речи при более низких требованиях к скорости передачи информации, в CSM используется способ кодирования, объединяющий вокодеры и дифференциальную ИКМ, который получил название дифференциального кодирования.
Вокодерное преобразование основано на использовании особенностей речевых органов человека. По сути дела голосовые связки человека генерируют частоту, которая далее модулируется горлом и ртом, как фильтром. Зная в каждый момент времени частоту и параметры “фильтра”, можно восстановить исходный сигнал. Учитывая инерционность голосовых органов человека, можно считать что за небольшой промежуток времени (10 - 30 мс) они не изменяют своего состояния, т.е. остаются постоянными частота и параметры “фильтра”. Следовательно, если брать отрезки речевого сигнала по 20 мс, определять частоту основного тона и параметры “фильтра” речеобразующего тракта, то по ним легко можно восстановить исходный сигнал. Так например, при кодировании с линейным предсказанием определяется и передается следующая информация:
- параметры модели речеобразующего тракта;
- характер возбуждения (гласный или звонкий согласный звук в
сопоставлении с глухими звуками);
- период основного тона;
Естественно в фиксированные промежутки времени голосовые органы человека не остаются в фиксированном положении, и возбуждения носят более комплексный характер, чем передаваемые характер возбуждения и период основного тона. Это приводит к значительному ухудшению качества.
Дифференциальная импульсно-кодовая модуляция учитывает корреляцию дискретных отсчетов АИМ сигнала. При этом кодируются не сами дискретные отсчеты, а разность амплитуд поступившего и предыдущего дискретных отсчетов. Поскольку диапазон изменения амплитуд разности дискретных отсчетов меньше диапазона изменения амплитуд самих дискретных отсчетов, для их кодирования требуется меньшее число разрядов.
Таким образом, дифференциальное кодирование подразумевает деление речевого сигнала на отрезки в 20 мс с последующим их кодированием. В общем виде структурная схема кодера, используемого в CSM, представлена на рис. 2.1. В начале формируются сегменты речевого сигнала в 20 мс.
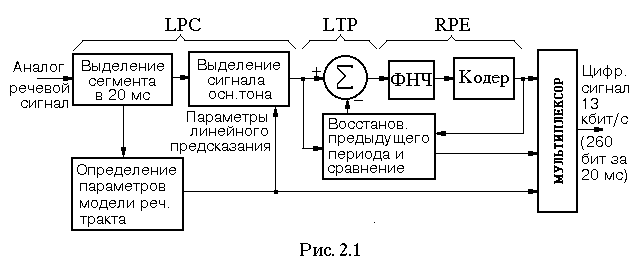
Далее определяется сигнал основного тона и параметры линейного предсказания. Учитывая корреляцию периодов сигнала основного тона, формируется разностный сигнал как разность поступившего и предшествующего периодов. После выделения спектра основного сигнала с помощью фильтра низких частот (ФНЧ) производится его кодирование. В результате кодирования получаем 260 бит, характеризующих сегмент речевого сигнала в 20 мс. Следовательно, требуемая скорость передачи информации составит 13 кбит/с. Данный кодер получил название кодера с регулярным импульсным возбуждением / долговременным предсказанием и линейным предикативным кодированием с предсказанием (RPE / LTP - LPC - кодер).

