 2015-02-24
2015-02-24 760
760Как было отмечено выше, если никаких дополнительных сведений о массиве, в котором хранятся данные, нет то ускорить поиск нельзя. Если же заранее известна некоторая информация о данный, среди которых ведется поиск, например,
массив данных отсортирован, удается существенно сократить время работы, применяя другие методы поиска.
Одним из методов поиска, более эффективным, чем линейный, является бинарный (двоичный) поиск, называемый также методом половинного деления. При его использовании на каждом шаге область поиска сокращается вдвое. Рассмотрим применение этого метода для решения конкретной задачи.
Задача
Даны целое число x и массив a[1..n], отсортированный в порядке убывания, то есть для любого k: 1 ≤ k < n: a[k-1] ≤ a[k]. Найти такое i, что a[i] = x, или сообщить, что элемента x в массиве нет.
Идея бинарного метода состоит в том, чтобы проверить, является ли x средним элементом массива. Если да, то ответ получен. Если нет, то возможны два случая:
· x меньше среднего элемента, следовательно, в силу упорядоченности массива a, можно исключить из рассмотрения все элементы массива, расположенные в нем правее среднего (так как они больше среднего элемента, который, в свою очередь, больше x), и применить этот метод к левой половине массива.
· x больше среднего элемента, следовательно, рассуждая аналогично, можно исключить из рассмотрения левую половину массива и применить этот метод к его правой части.
Средний элемент и в том, и в другом случае в дальнейшем не рассматривается. Таким образом, на каждом шаге отсекается та часть массива, где заведомо не может быть обнаружен элемент x.
Рассмотрим пример
Пусть x = 6, а массив а состоит из 10 элементов:
3 5 6 8 12 15 17 18 20 25.
1 -й шаг: найдем номер среднего элемента:
m = 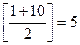 .Так как 6 < a [ 5 ], далее можем рассматривать только элементы, индексы которых меньше 5. Об остальных элементах можно сразу сказать, что они
.Так как 6 < a [ 5 ], далее можем рассматривать только элементы, индексы которых меньше 5. Об остальных элементах можно сразу сказать, что они
больше x вследствие упорядоченности массива, и среди них искомого элемента нет:
 3 5 6 8 12 15 17 18 20 25;
3 5 6 8 12 15 17 18 20 25;
2- й шаг: рассматриваем лишь первые 4 элемента массива;
находим индекс среднего элемента этой части:
m = 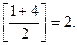
6 > a [ 2 ], следовательно, первый и второй элементы из рассмотрения исключаем:
3 
 5 6 8 12 15 17 18 20 25;
5 6 8 12 15 17 18 20 25;
3 -й шаг: рассматриваем 2 элемента; значение
m = 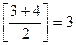 ;
;

 3 5 6 8 12 15 17 18 20 25;
3 5 6 8 12 15 17 18 20 25;
а [ 3 ]= 6! Элемент найден, его номер - 3.
Примечание: Вообще говоря выбор значения m можно осуществлять случайным образом, корректность алгоритма от способа выбора m не зависит. Но на эффективность алгоритма выбор m влияет, так как мы хотим на каждом шаге исключить из дальнейшего рассмотрения как можно больше элементов. Оптимальным будет выбор среднего элемента, потому что при этом в любом случае будет исключаться половина массива.
В общем случае значение m = 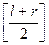 , где l - индекс первого, а r - индекс последнего элемента рассматриваемой части массива.
, где l - индекс первого, а r - индекс последнего элемента рассматриваемой части массива.
program n8;const n=10;var x,l,r,m,i:integer; f:boolean; a:array[1..n] of integer;begin writeln('Введите исходный массив:'); for i:=1 to n do read(a[i]); writeln('Введите x'); readln(x); l:=1; r:=n; f:=false;
while (l<=r)and not f do
begin
m:=(l+r) div 2;
if a[m]=x then f:=true else if a[m]<x then l:=m+1 else r:=m-1;
end;
writeln('a[',m,']=',x,'=x');
end.
Программа этой же сортировки с использованием барьера.
program n9;const n=10;var x,l,r,m,i:integer; f:boolean; a:array[1..n] of integer;
begin
writeln('Введите исходный массив:');
for i:=1 to n do read(a[i]);
writeln('Введите x');
readln(x);
l:=1;
r:=n;
f:=false;
while (l<=r)and not f do
begin
m:=(l+r) div 2;
if a[m]=x then f:=true else if a[m]<x then l:=m+1 else r:=m-1;
end;
writeln('a[',m,']=',x,'=x');
end.








