 2015-04-01
2015-04-01 634
634Как и все методы инкрементной кластеризации, данный метод использует древесную структуру данных CF – tree (Clustering Feature tree). Собственно, каждый кластер представляется некоторым вектором CF (Clustering Feature), являющимся тройкой:
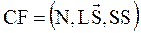 , (50)
, (50)
где N – количество точек в кластере, 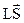 – линейная сумма этих точек (векторов), SS – сумма квадратов этих точек (векторов). Соответственно объединение кластеров представляется опять же вектором CF, полученным простой линейной суммой векторов CF объединяемых кластеров.
– линейная сумма этих точек (векторов), SS – сумма квадратов этих точек (векторов). Соответственно объединение кластеров представляется опять же вектором CF, полученным простой линейной суммой векторов CF объединяемых кластеров.
CF – tree – это дерево, характеризующееся двумя параметрами: коэффициентом ветвления B и пороговым значением T. B является значением максимально возможно числа потомков для узла. T определяется как минимальное общее внутреннее сходство кластера.
Объекты в такое дерево поступают последовательно и проходят по направлению от корневой вершины к листьям, пока не находят наиболее близкий лист. По достижении уровня листьев, объект добавляется в наиболее близкий лист, если при этом не происходит нарушения порогового значения T. Или же добавляется как лист, если есть для него еще место у родителя в соответствии с B.
Если эти условия не выполняются, то необходимо разделить листья, то есть разбить их родителя на два узла и распределить листья по ним. Разделение происходит разнесением листьев из наиболее удаленной пары по разным родителям и распределении остальных листьев по принципу близости первым двум.
После добавления объекта в качестве листа, необходимо обновить узлы на пути к данному листу. Если после разделения листьев, их количество потомков на уровне родителей перестало удовлетворять B, то всех потомков уровня родителей листьев необходимо разделить по аналогии с листьями и далее, вплоть до корневой вершины, если необходимо.








