 2015-04-30
2015-04-30 2024
2024После создания структуры хранилища данных оно представляет с собой
«пустое» ХД Deductor Warehouse 6 с настроенным семантическим слоем.
В таком виде оно готово к загрузке данных из внешних структурированных источников. Для этого необходимо написать соответствующий сценарий в Deductor Studio.
Сценарий загрузки должен выполнять следующие функции.
– Импорт данных в Deductor Studio из базы данных, учетной системы или предопределенных файлов.
– Опциональная предобработка данных, например, очистка или преобразование формата.
– Загрузка данных в измерения и процессы хранилища Deductor Warehouse.
В нашем демонстрационном примере исходными данными для ХД служат 4 текстовых файла: groups.txt (товарные группы), produces.txt (товары), stores.txt (отделы), sales.txt (продажи по дням). Поэтому сценарий загрузки должен быть настроен на использование в качестве источников данных на эти файлы (рис. 3.13).
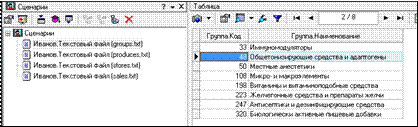
Рисунок 3.13 – Результат сценария загрузки из четырех узлов
При создании сценария необходимо строго придерживаться следующих правил.
1. Первыми загружаются все измерения, имеющие атрибуты. Только после загрузки всех измерений загружаются данные в процесс(ы).
2. Среди измерений также имеется правило на порядок загрузки: загружать измерения нужно, начиная с самого верхнего уровня иерархии и спускаться по иерархии ниже. Это крайне важно, в противном случае иерархия не будет создана.
3. Допускается не загружать отдельно измерения, не имеющие атрибутов и не состоящие в иерархии измерений. Значения таких измерений можно при использовании специальной опции создавать во время загрузки в процесс.
1) Последовательно импортируем все четыре текстовых файла в Deductor в следующей последовательности: groups.txt, produces.txt, stores.txt, sales.txt.
При подключении файла sales.txt необходимо исправить следующие ошибки:
– разделители целой и дробной части – точка;
– тип поля Сумма – вещественный;
– тип поля Количество – целый.
Внимательно установите в файлах groups.txt, produces.txt, stores.txt, sales.txt. типы данных у полей Группа.Код, Товар.Код, Отдел.Код, Час.Код – они должны быть целыми.
В результате получим сценарий, состоящий из четырех узлов импорта.
2) После импорта можно приступим к загрузке данных в ХД (рис. 3.14).
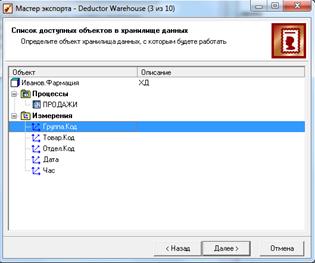
Рисунок 3.14 – Мастер экспорта данных в ХД
Первыми следуют таблицы измерений, и только в конце – таблица процесса sales.txt. Менять порядок веток сценария можно при помощи кнопок CTRL+↑ и CTRL+↓.
Представим последовательность загрузки данных в измерение снова на примере первого измерения Группа.Код. Встав для этого на первом узле, вызовем Мастер экспорта. Из списка типа приемников выберем Deductor Warehouse.
3) На следующей вкладке из списка доступных хранилищ укажем нужное нам ХД под названием Иванов.Фармация. Далее требуется указать, в какое именно измерение будет загружаться информация.
Это – Группа.Код.
4) Последнее, что осталось, – это установить соответствие элементов объекта в хранилище данных с полями входного источника данных (т.е. таблицы groups.txt). В случае, когда имена полей и метки в семантическом слое хранилища данных совпадают, делать ничего не нужно (либо выбрать в Поле из источника данных нужное поле).
Нажатие кнопки Пуск на следующем шаге загрузить в измерение данные. При этом «старые» данные, если они были, будут обновлены (рис. 3.15).
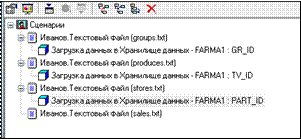
Рисунок 3.15 – Результирующий сценарий соответствия элементов
5) Проделав аналогичные действия еще для двух измерений –
Отдел.Код, Товар.Код, получим следующий сценарий.
Загрузка измерений на этом заканчивается, несмотря на то что еще остались два измерения Дата и Час. Но они без атрибутов и не участвуют в иерархии, поэтому их значения можно загрузить на этапе экспорта в процесс.
6) Теперь, когда все измерения загружены (т.е. определены все координаты в многомерном пространстве), можно загружать данные в процесс Продажи (рис. 3.16). В отличие от загрузки измерений в Мастере экспорта появляются два специфических шага.
На одном из них нужно задать параметры контроля непротиворечивости данных в хранилище – указать измерения, по которым следует удалять данные из хранилища.
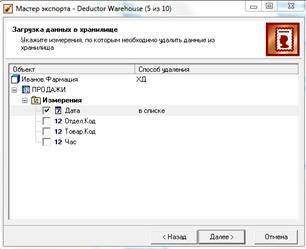
Рисунок 3.16 – Задание параметров контроля непротиворечивости
Здесь указываем выполняемое действие в ситуации, когда в процесс загружается информация, которая совпадает по значениям из нескольких измерений. Вариантов может быть два:
– удалить «старые» данные и загрузить «новые»;
– запретить удаление и оставить то, что уже было загружено ранее. Подобный способ загрузки удобен тем, что позволяет избежать коллизий, например, когда в хранилище имеются некорректные данные за какой-то период. В таком случае лучше все данные за этот период удалить, а после загрузить новые корректные сведения.
7) На последней странице настроек лучше оставить настройки по умолчанию (рис. 3.17).
Загрузка с поднятой опцией Обновить кубы «пересчитает» все кубы, построенные в хранилище на основе данного процесса.
Включенный флажок Отключить ограничения и индексы полезен в случае экспорта в процесс больших объемов данных (например, при первичной загрузке). Тогда во время выполнения этого действия каждый раз при добавлении строки данных будет тратиться время на дополнительные процедуры, связанные с перестройкой индексов и проверкой ограничений. С ростом числа записей выигрыш от отключения этих процедур может составлять ощутимую величину (в 3–5 и более раз).
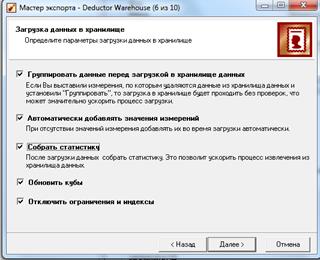
Рисунок 3.17 – Настройки по умолчанию
Флажок Автоматически добавлять значения измерений как раз и позволяет «на лету» добавлять новые значения в существующие измерения. Однако пользоваться данный опцией нужно с осторожностью. В случае бездумного ее применения можно очень быстро «замусорить» хранилище данных, т.к. любое, даже неверное значение измерения будет занесено как реально существующее.
Активный флажок Группировать данные перед загрузкой в хранилище полезен в следующей ситуации: вы до конца не уверены, что совокупность измерений процесса обеспечит уникальность точки в многомерном пространстве и, одновременно, такой уровень детализации вас устраивает. В нашем примере, если в таблице продаж встретятся две записи с одинаковыми значениями измерений (таблица 3.6), то при отсутствии установленного флажка Группировать данные… в хранилище попадет только вторая запись (т.е. последняя встретившаяся). Получится, что одна запись фактически потеряется, а, по-хорошему, нужно просуммировать значения полей Количество и Сумма.
Таблица 3.6. Две записи с одинаковыми значениями измерений

В Мастере экспорта можно задать и любой другой вариант агрегации данных (рис. 3.18). В случае, когда есть уверенность в том, что совокупность измерений процесса обеспечивает уникальность точки в многомерном пространстве, группировку можно не производить – это сэкономит время загрузки.

Рисунок 3.18 – Задание варианта агрегации
8) Окончательный сценарий загрузки в хранилище Иванов. Фармация
следующий (рис. 3.19).
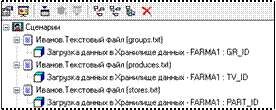
Рисунок 3.19 – Получение окончательного сценария загрузки в хранилище
Полученный результат сохранить в файле L3_1.ded.

