 2015-05-18
2015-05-18 501
501Лабораторная работа №3
Цель: Освоить методы построения линейного уравнения парной регрессии с помощью ЭВМ, научиться получать и анализировать основные характеристики регрессионного уравнения.
Рассмотрим методику построения регрессионного уравнения на примере.
ПРИМЕР. Торговая организация желает выяснить, как влияет количество вложенных в рекламную акцию денег – Х (тыс.руб.) на количество проданного товара Y (тыс.шт.). для этого проводились наблюдения в разных городах региона и были получены следующие данные.
| Х | ||||||||||||
| Y |
Введем эту таблицу в ячейку А1-М2 электронной книги Excel. Просмотрим предварительно, как лежит точки не графике и какое уравнение регрессии лучше выбрать. Для этого строим график. На вкладке Вставка выбрав тип диаграммы «Точечная», выделив ячейки с В1 по М2 (т.е. Диапазон – значения ячеепк В2-М2, Значения Х – В2-М2).
Как видно из графика, точки хорошо укладываются на прямую линию, поэтому будем находить уравнение линейной регрессии виде y=ax+b.
Для нахождения коэффициентов a и b уравнения регрессии служат функции НАКЛОН и ОТРЕЗОК, категории «Статистические». Вводим в А5 подпись «а=» а в соседнюю ячейку В5 вводим функцию НАКЛОН, ставим курсор в поле «Известные_значения_у» задаем ссылку на ячейки В2-М2, обводя их мышью, то же самое по полю х, присваиваем соответствующие значения. Результат 1,9223921. Найдем теперь коэффициент b. Вводим в А6 подпись «b=», а в В6 функцию ОТРЕЗОК с теми же параметрами, что и функции НАКЛОН. Результат 12,78151. следовательно, уравнение линейной регрессии есть у=1,92х+12,78.
Построим график уравнения регрессии. Для этого в третью строчку таблицы введем значения функции в заданных точках Х (первая строка) – у(х1). Для получения этих значений используются функция ТЕНДЕНЦИЯ категории «Статистические». Вводим в А3 подпись «Y(X) и, поместив курсор в В3, вызываем функцию ТЕНДЕНЦИЯ. В полях «Известные_значения_у» и «Известные_значения_х» даем ссылку на В2-М2 и В1-М1. в поле «Новые_значения_х» вводим также ссылку на В1-М1. в поле «Конст» вводим 1, если уравнение регрессии имеет вид y=ax+b, и 0, если у=ах. В нашем случае вводим единицу. Функция ТЕНДЕНЦИЯ является массивом, поэтому для вывода всех ее значений выделяем область В3-М3 и нажимаем F2 и Ctrl+Shift+Enter. Результат – значения уравнения регрессии в заданных точках.
Строим график. Ставим курсор в любую свободную клетку, выделяем значения по х и у(х), далее выбираем категорию «Точеная», вид графика – линия без точек (в нижнем правом углу). Результат – прямая линия регрессии.
Посмотрим, как различаются графики опытных данных и уравнения регрессии. Для этого ставим курсор в любую свободную ячейку, выделяем вызываем вторую и третью строки В2-М3 и выбираем категорию «График», вид графика – ломанная линия с точками (должны получить, «Диапазон» - это ссылки на вторую и третью строки В2-М3). Завершим график в поле «Подписи оси Х» (найти поле можно через контекстное меню Выбрать данные) введем ссылку на В1-М1, нажимаем «Готово». Результат – две линии (Синяя – исходные, красная – уравнение регрессии). Видно, что линии мало различаются между собой.
Для вычисления коэффициента корреляции rxy служит функция ПИРСОН. Размещаем график так, чтобы они располагались выше 25 строки, и в А25 делаем подпись «Корреляция», в В25 вызываем функцию PEARSON, в полях которой «Массив 1» и «Массив 2» вводим ссылку на исходные данные В1-М1 и В2-М2. результат 0,993821. коэффициент детерминации Rxy – это квадрат коэффициента корреляции rxy. В А26 делаем подпись «Детерминация», а в В26 – формулу «=В25*В25». Результат 0,987681.
Однако, в Excel существует одна функция, которая рассчитывает все основные характеристики линейной регрессии. Это функция ЛИНЕЙН. Ставим курсор в В28 и вызываем функцию ЛИНЕЙН, категории «Статистические». В полях «Известные_значения_у» и «Известные_значения_х» даем ссылку на В2-М2 и В1-М1. поле «Константа» имеет тот же смысл, что и функции ТЕНДЕНЦИЯ, у нас она равна 1. поле «Статистика» должно содержать 1, если нужно вывести полную статистику о регрессии. В нашем случае ставим туда единицу. Функция возвращает массив размеров 2 столбца и 5 строк. После ввода выделяем мышью ячейку В27-С32 и нажимаем F2 и Ctrl+Shift+Enter. Результат – таблица значений, числа в которой имеют следующий смысл:
| Коэффициент а | Коэффициент b |
| Стандартная ошибка mo | Стандартная ошибка mh |
| Коэффициент детерминации Rxy | Среднеквадратическое отклонение у |
| F – статистика | Степени свободы n-2 |
| Регрессионная сумма квадратов Sn2 | Остаточная сумма квадратов Sn2 |
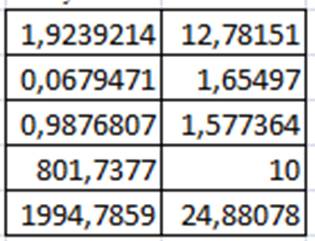
Анализ результата:
· В первой строчке – коэффициенты уравнения регрессии, сравните их с рассчитанными функциями НАКЛОН и ОТРЕЗОК.
· Вторая строчка – стандартные ошибки коэффициентов. Если одна из них по модулю больше, чем сам коэффициент, то коэффициент считается нулевым.
· Коэффициент детерминации характеризует качество связи между факторами. Полученное значение 0,987681 говорит об очень хорошей связи факторов.
· F – статистика проверяет гипотезу о адекватности регрессионной модели. Данное число нужно сравнить с критическим значением, для его получения вводим в Е33 подпись «F-критическое», а в F33 функцию FРАСПОБР, аргументами которой вводим соответственно «0,05» (уровень значимости), «1» (число факторов Х) и «10» (степени свободы). Видно, что F-статистика больше, чем F-критическое, значит, регрессионная модель адекватна.
· В последней строке приведены регрессионная сумма квадратов 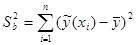 и остаточные суммы квадратов . Важно, чтобы регрессионная сумма (объясненная регрессией) была намного больше остаточной (не объясненная регрессией, вызванная случайными факторами). В нашем случае это условие выполняется, что говорит о хорошей регрессии.
и остаточные суммы квадратов . Важно, чтобы регрессионная сумма (объясненная регрессией) была намного больше остаточной (не объясненная регрессией, вызванная случайными факторами). В нашем случае это условие выполняется, что говорит о хорошей регрессии.








