 2015-05-13
2015-05-13 838
838Пусть имеется n наблюдений, каждому из которых соответствует запись в таблице. Все записи принадлежат какому-либо классу. Необходимо определить класс для новой записи.
На первом шаге алгоритма следует задать число k – количество ближайших соседей. Если принять k = 1, то алгоритм потеряет обобщающую способность (то есть способность выдавать правильный результат для данных, не встречавшихся ранее в алгоритме) так как новой записи будет присвоен класс самой близкой к ней. Если установить слишком большое значение, то многие локальные особенности не будут выявлены.
На втором шаге находятся k записей с минимальным расстоянием до вектора признаков нового объекта (поиск соседей).
Для упорядоченных значений атрибутов находится Евклидово расстояние: 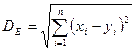 , где n – количество атрибутов.
, где n – количество атрибутов.
Для строковых переменных, которые не могут быть упорядочены, может быть применена функция отличия, которая задается следующим образом: 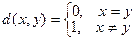
Часто перед расчетом расстояния необходима нормализация.
При нахождении расстояния иногда учитывают значимость атрибутов. Она определяется экспертом или аналитиком субъективно, полагаясь на собственный опыт. В таком случае при нахождении расстояния каждый i -ый квадрат разности в сумме умножается на коэффициент Zi. Например, если атрибут A в три раза важнее атрибута B (ZA = 3, ZB =1).
Подобный прием называют растяжением осей (stretching the axes), что позволяет снизить ошибку классификации.
Следует отметить, что если для записи B ближайшем соседом является А, то это не означает, что В – ближайший сосед А.
На следующем шаге, когда найдены записи, наиболее похожие на новую, необходимо решить, как они влияют на класс новой записи. Для этого используется функция сочетания (combination function). Одним из основных вариантов такой функции является простое невзвешенное голосование (simple unweighted voting).








