 2015-05-26
2015-05-26 1420
1420Обмен данными с медленнодействующими периферийными устройствами, например, с посимвольным принтером, организуется по прерываниям, инициирующим передачу каждого слова или байта. Если подпрограмма обслуживания запроса длится около 50 мкс, а скорость передачи не превышает 100 символов/с, то на ввод-вывод расходуется не более 0.5% времени процессора.
Существуют устройства, ориентированные на передачу отдельных слов или байтов, но требующие более высокой скорости обмена. К таким устройствам можно отнести измерительную и управляющую аппаратуру, и аппаратуру связи с другими ЭВМ (сетевые средства). Рассмотрим простейший случай, когда коды, поступающие из измерительной аппаратуры, просто накапливаются в оперативной памяти, без всякого анализа и обработки. Скорость работы измерительной установки может достигать нескольких тысяч измерений в секунду и более.
Программа обработки прерываний для процессора 8086, обслуживающая этот процесс, будет состоять из следующих команд.
Сохранить указательный регистр процессора в стеке.
Сохранить регистр - аккумулятор в стеке.
Поместить в указательный регистр адрес ячейки памяти.
Прочитать данные из порта в аккумулятор.
Сохранить содержимое аккумулятора в памяти.
Увеличить адрес в указательном регистре.
Сохранить адрес в памяти.
Восстановить из стека содержимое аккумулятора.
Восстановить указательный регистр.
Время выполнения такой программы составит приблизительно 50 мкс. Добавим сюда аппаратные издержки механизма прерываний - около 40 мкс. В результате получается, что для пересылки в память одной порции данных затрачивается 90 мкс. Если скорость поступления регистрируемых событий высока, значительная доля процессорного времени (в приведенном примере около 45%, а с учетом постоянно повторяющегося сохранения - восстановления указательного регистра и аккумулятора около 70%) будет расходоваться на непроизводительную работу - организацию переходов на подпрограмму обработки прерываний и обратно. С учетом возможных системных издержек эта цифра может существенно возрасти. В таких условиях сама идея прерываний теряет смысл, т.к. фактически у центрального процессора не остается времени на выполнение основной программы. Более эффективным может оказаться программно - управляемый обмен, если в конкретной ситуации можно смириться с его недостатками - обслуживанием только одного устройства и невозможностью организовать параллельное выполнение основной программы.
Аналогичные проблемы возникают при передаче между основной и внешней памятью ЭВМ больших блоков данных. В этом случае производительности (или пропускной способности) процессора в режиме прерываний также недостаточно. Многие устройства внешней памяти (в частности, накопители на магнитных дисках) имеют блочную структуру, т.е. их программная модель представляет собой последовательность логических блоков размером 128 4096 байт. При выполнении операций записи или считывания на таких устройствах необходимо локализовать требуемые данные (дать устройству команду на поиск требуемого блока) и затем произвести пересылку между контроллером устройства и оперативной памятью целого блока.
Пусть при пересылке блока из устройства в память отдельные байты, составляющие блок, считываются из порта внешнего устройства и последовательно размещаются в выделенной для этого области памяти. Никакой проверки и обработки байтов не производится. Не производится также никаких проверок во внешнем устройстве. Пусть один из регистров процессора содержит счетчик байтов, подлежащих пересылке, другой содержит указатель на выделенную область памяти. Тогда программа пересылки байтов данных под управлением процессора должна состоять из следующих шагов.
1. Прочитать байт из порта периферийного устройства в регистр процессора.
2. Переслать прочитанный байт из регистра процессора в память.
3. Увеличить указатель данных, чтобы он указывал на следующую ячейку памяти.
4. Уменьшить на 1 счетчик пересланных байтов.
5. Если счетчик не равен нулю, перейти к шагу 1
Фрагмент программы, реализующий эти действия в ЭВМ с процессором 8086 при тактовой частоте 4 МГц, будет состоять из пяти команд, и время выполнения этого фрагмента (соответственно, время пересылки одного байта) составит около 15 мкс. Таким образом, скорость обмена данными составит приблизительно 65 Кбайт/с. Вместе с тем, время доступа к оперативной памяти составляет всего 0.1 - 2 мкс и, следовательно, скорость передачи ограничивается только процессором.
Обратим внимание на то, что описанные действия по пересылке блока информации и описанные выше действия по пересылке отдельных слов похожи друг на друга и довольно просты. Они легко могут быть реализованы аппаратно. А если заставить выполнять эти простые действия не сам центральный процессор, а некоторую внешнюю по отношению к процессору схему и организовать канал передачи данных между внешними устройствами и памятью напрямую, минуя процессор? Пусть эта схема сама увеличивает адреса, уменьшает счетчики, формирует управляющие сигналы шины, в общем, является задатчиком на шине. Такой метод обмена данными получил название прямого доступа к памяти (ПДП). Аппаратные средства реализации канала ПДП называются контроллером прямого доступа к памяти. Контроллер может быть реализован в виде отдельного устройства, доступного всем периферийным устройствам (централизованная система ПДП). Возможно также, что каждое внешнее устройство, нуждающееся в реализации ПДП, может иметь в своем контроллере свои средства организации ПДП. Второй случай приводит к узкоспециализированным средствам ПДП, однако позволяет учитывать специфические потребности каждого устройства.
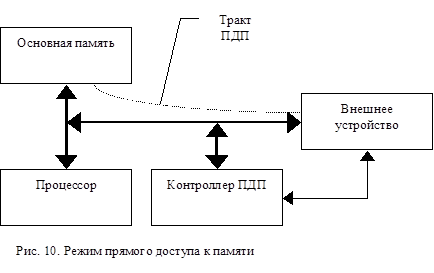 |
В идеальном случае ПДП совершенно не должен влиять на действия процессора, но для этого потребуется дополнительный, сложный и дорогой тракт доступа к оперативной памяти. Такие средства имеются в дорогих больших ЭВМ, и далее мы рассмотрим их при описании схемы ЭВМ с каналами. Для мини- и микроЭВМ такие средства неприемлемы из-за их высокой стоимости. Поэтому в них используется более простой (но, конечно, менее производительный) прием временного разделения (мультиплексирования) общей системной шины между процессором и контроллером ПДП. В обычных условиях системной шиной “распоряжается” центральный процессор, он является задатчиком при большинстве операций на шине. При подготовке операции обмена с использованием ПДП процессор программирует контроллер ПДП, т.е. “указывает” ему сколько нужно переслать данных и по какому адресу эти данные необходимо поместить. Когда режим ПДП инициируется, задатчиком становится контроллер ПДП. Он “распоряжается” шиной, управляя передачей данных непосредственно между основной и внешней памятью, а действия процессора приостанавливаются, и он отключается от системной шины (рис. 10).
Возможны две разновидности ПДП. В режиме идентификации состояния процессора (или “прозрачном” ПДП) контроллер ПДП занимает шину тогда, когда процессор выполняет внутренние действия по преобразованию данных и не обращается к шине. Процессор (или дополнительная схема) идентифицирует такие промежутки времени для контроллера ПДП специальным сигналом, означающим доступность шины. Производительность процессора в таком режиме не уменьшается, (процессор “не замечает” что происходит ПДП, ПДП “прозрачный”), но контроллер ПДП оказывается жестко “привязанным” к схеме процессора, а сами передачи носят нерегулярный характер, что ведет к уменьшению скорости передачи данных.
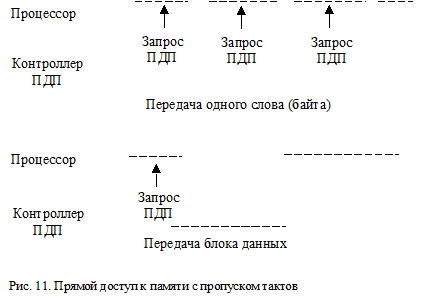 В режиме с пропуском тактов (точнее с “займом” тактов) контроллер ПДП при необходимости сигналом запроса ПДП DMA REQ (Direct Memory Access REQuire) или HOLD заставляет процессор отключиться от системной шины на несколько тактов. После восприятия запроса ПДП процессор завершает выполнение текущего цикла доступа к памяти, приостанавливает свои действия и информирует об этом контроллер ПДП сигналом разрешения прямого доступа к памяти HLDA (HoLD Acnowlege). Задатчиком на системной шине становится контроллер ПДП, он передает между памятью и портом внешнего устройства один элемент данных - байт или слово. Внутренние операции процессора могут совмещаться с передачами ПДП. За одно инциирование ПДП может передаваться и блок данных, например, сектор диска. Таким образом, передачи ПДП осуществляются путем пропуска тактов в выполняемой программе. Иллюстрация данной разновидности ПДП приведена на рис. 11. В отличие запросов на прерывание сигналы запроса на ПДП всегда имеют наивысший приоритет, и эти запросы не могут быть запрещены. При выполнении передачи ПДП содержимое внутренних регистров процессора не модифицируется, поэтому его не нужно запоминать в памяти, а затем восстанавливать как при обработке прерываний. Выполнение программы возобновляется сразу после снятия запроса ПДП. Тем не менее в условиях интенсивных передач ПДП эффективная производительность процессора уменьшается.
В режиме с пропуском тактов (точнее с “займом” тактов) контроллер ПДП при необходимости сигналом запроса ПДП DMA REQ (Direct Memory Access REQuire) или HOLD заставляет процессор отключиться от системной шины на несколько тактов. После восприятия запроса ПДП процессор завершает выполнение текущего цикла доступа к памяти, приостанавливает свои действия и информирует об этом контроллер ПДП сигналом разрешения прямого доступа к памяти HLDA (HoLD Acnowlege). Задатчиком на системной шине становится контроллер ПДП, он передает между памятью и портом внешнего устройства один элемент данных - байт или слово. Внутренние операции процессора могут совмещаться с передачами ПДП. За одно инциирование ПДП может передаваться и блок данных, например, сектор диска. Таким образом, передачи ПДП осуществляются путем пропуска тактов в выполняемой программе. Иллюстрация данной разновидности ПДП приведена на рис. 11. В отличие запросов на прерывание сигналы запроса на ПДП всегда имеют наивысший приоритет, и эти запросы не могут быть запрещены. При выполнении передачи ПДП содержимое внутренних регистров процессора не модифицируется, поэтому его не нужно запоминать в памяти, а затем восстанавливать как при обработке прерываний. Выполнение программы возобновляется сразу после снятия запроса ПДП. Тем не менее в условиях интенсивных передач ПДП эффективная производительность процессора уменьшается.
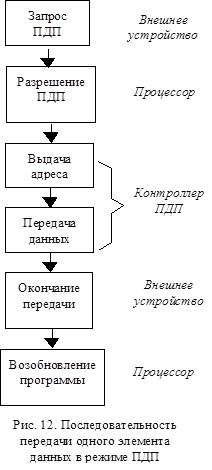
Аппаратная реализация каналов ПДП определяется особенностями ЭВМ и устройств внешней памяти, но можно сформулировать и общие принципы работы большинства каналов ПДП. На рис.12 показаны основные этапы передачи одного элемента данных в режиме ПДП, называемой также циклом ПДП. Перед началом обмена данными производится программирование контроллера ПДП, в него помещаются адреса памяти и информация о количестве передаваемых данных. Последовательность передачи инициируется сигналом от внешнего устройства, например, накопителя на гибком диске. Контроллер ПДП транслирует этот сигнал в запрос для процессора. Процессор реагирует сигналом подтверждения (разрешения), и отключается от системной шины (но может продолжать внутренние операции). Для осуществления передачи контроллер ПДП выдает на системную шину адрес ячейки памяти, к которой производится обращение для записи или считывания. После этого на шине данных производится собственно передача данных, для чего контроллер ПДП генерирует необходимые управляющие сигналы для памяти и портов ввода - вывода. Затем устройство внешней памяти снимает запрос ПДП, что приводит к снятию соответствующего запроса в процессор, и он возобновляет прерванную работу. Если в ЭВМ имеется несколько устройств, которые могут формировать запросы ПДП, описанная последовательность должна включать в себя этап выборки устройства, инициировавшего запрос ПДП, и блокировки остальных устройств. Если в ЭВМ используется централизованная система ПДП, эту блокировку производит общесистемный контроллер ПДП, если устройство производит ПДП самостоятельно, для блокировки других устройств используется сигнал “занято” на шине управления, который уже упоминался выше.
При передаче блока данных последовательность действий при передаче (рис. 12) необходимо дополнить модификацией адреса основной памяти и проверки окончания передачи блока. Для этого в контроллер ПДП загружается адрес основной памяти и число передаваемых байт или слов. После каждой передачи в контроллере ПДП производится увеличение адреса, выдаваемого на шину адреса, и уменьшение счетчика байт или слов. Передача блока завершается, когда счетчик достигает нуля.
Подведем некоторые итоги. Несмотря на многообразие задач, решаемых ЭВМ, процессы, происходящие на системной шине, ограничены небольшим числом основных действий. К таким действиям можно отнести операции записи, чтения, прерывания и прямого доступа в память (рис. 13).
 |
Операция чтения позволяет процессору получить необходимую для выполнения программы информацию: из памяти – код очередной команды или данные, из порта внешнего устройства – информацию о состоянии устройства или очередную порцию данных.
В процессе операции записи процессор передает в память результат вычислений, а в порт внешнего устройства - управляющие слова или очередную порцию данных (заметим, что при этих операциях задатчиком на шине является процессор и направление передачи определяется относительно процессора: чтение - в процессор, запись - из процессора).
С помощью операции прерывания внешнее устройство оповещает процессор о своей готовности к передаче очередной порции данных. Эта операция позволяет внешнему устройству выполнять активную роль и создает предпосылки для обработки внешних событий, регистрируемых ЭВМ.
Операция прямого доступа в память служит для массовой передачи данных в память или из нее под управлением не процессора, как обычно, а контроллера прямого доступа к памяти. Использование прямого доступа к памяти требует наличия общесистемного контроллера ПДП, либо существенного усложнения аппаратуры внешних устройств. Однако он может существенно повысить скорость обмена информацией (по сравнению с режимом прерываний в десятки и сотни раз).
С помощью перечисленных операций реализуется все многообразие действий, выполняемых ЭВМ. Редактирование текста, трансляция программ, вычисления, управление автоматизированной установкой - все это раскладывается на простейшие операции, прежде всего чтения и записи, а также в случае необходимости прерываний и прямого доступа. Быстродействие ЭВМ, в конечном счете, определяется скоростью выполнения этих элементарных операций. Организационные и схемотехнические решения, закладываемые разработчиками системной шины и способов обмена данными, во многом определяют всю дальнейшую судьбу ЭВМ.

