 2015-06-10
2015-06-10 4176
4176НЕЧЕТКАЯ И ЛИНГВИСТИЧЕСКАЯ ПЕРЕМЕННЫЕ
Определение 1. 8 Нечеткой переменной называется
< a, X, Ca >,
где a - наименование нечеткой переменной; X={x} - область ее определения; Ca = {< ma(x) / x >} - нечеткое множество на X, описывающее ограничения на возможные значения нечеткой переменной a (ее семантику).
Определение 1.9. Лингвистической переменной называется
< b,T,X, G,M >,
где b - наименование лингвистической переменной; T - множество ее значений (терм-множество), представляющих собой наименования нечетких переменных, областью определения каждой из которых является множество X. G – синтаксическая процедура (грамматика), позволяющая оперировать элементами множества T, в частности генерировать новые термы.
M – семантическая процедура, позволяющая превратить каждое новое значение лингвистической переменной, образуемое процедурой G, в нечеткую переменную, т.е. приписать ему нечеткую семантику путем формирования соответствующего нечеткого множества.
Пример 1.7. Рассмотрим пример лингвистической переменной.
Пусть эксперт оценивает толщину выпускаемого изделия с помощью понятий
“малая толщина", "средняя толщина" и "большая толщина";
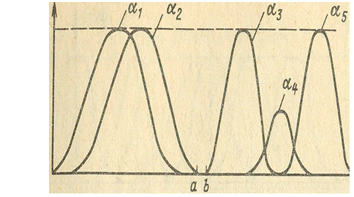
при этом минимальная толщина. изделия равна 10, а.максимальная 80 Формализация такого описания может быть проведена с помощью лингвистической переменной β -толщина изделия; Т = { α1, α2, α3}= [ малая толщина, средняя толщина, большая толщина]; Х= [10,80].
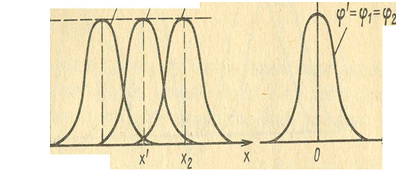
Пусть нечеткие множества С1, С2 И С3 описывают семантику базовых значений переменной β
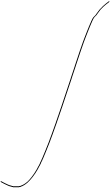
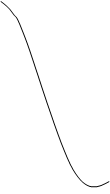
Функции принадлежности, соответствующие данным нечетким множествам, показаны на рис.
Тогда произвольные значения – α’ "малая или средняя толщина" и α " - "небольшая толщина" будут определяться нечеткими множествами С’ и C”
с функциями принадлежности, показанными на рис.
.
Лингвистические переменные, у которых процедура. образования новых значений G зависит от множества базовых значений Т, назовем синтаксически зависимыми лингвистическими переменными
Наряду с рассмотренными выше синтаксически зависимыми лингвистическими переменными существуют переменные, у которых процедура образования новых значений зависит не от множества базовых значений Т, а от области определения Х, Т.е. G = G(x). Например, значение лингвистической переменной "толщина изделия" определено как "близкое к 20 мм" или ''приблизительно к 75 мм". Такие лингвистические переменные назовем синтаксически независимыми.
Построение функций принадлежности на основе экспертных оценок.
При создании нечетких моделей ПР одним из этапов является этап построения функций принадлежности нечетких множеств, описывающих семантику базовых значений лингвистических переменных, используемых в модели. Нечеткие модели ПР содержат множество лингвистических переменных, и множество базовых значений этих переменных конечны. Поэтому для построения функций принадлежности можно воспользоваться методами экспертных оценок.
Рассмотрим основные методы построения функции принадлежности μA(х) элементов x 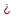 Х к нечеткому множеству.
Х к нечеткому множеству.
Пусть имеется т зкспертов, часть которых на вопрос о принадлежности элемента х Х нечеткому множеству А отвечает положительно. Обозначим их число через п1 Другая часть экспертов (п2 = т – п1) отвечает на этот вопрос отрицательно. Тогда принимается, что
μA(х) = п1/(п1 + п2)
Пример Пусть имеется множество Х = [ 1,2,3,4,5 ] и требуется построить нечеткое множество А, формализующее нечеткое понятие «немного больше двух". Допустим, что результаты опроса шести экспертов показаны в табл.. Тогда получим следующие значения функции принадлежности элементов множества Х нечеткому множеству А:
μA (1) = 0; μA (2) = 0; μA (3) = 1;
μA (4) = 0,7; μA (5) = 0,2..
Необходимо отметить, что данная схема определения функций принадлежности самая простая, но и самая грубая.
| m | x | ||||
| n1 | |||||
| n2 |
Более гибкой является процедура построения функция принадлежности на основе количественного парного сравнения степеней принадлежности [29, 30].
Эта процедура допускает использование всего одного эксперта для построения функции принадлежности. Результатом опроса эксперта является матрица М = ||m i,j ||, i,j = 1, п, где п число точек, в которых сравниваются значения функции. Число mij показывает, во сколько раз, по мнению эксперта, μA(хi) больше μA(хj), при этом количество вопросов к эксперту составляет не п2, а лишь (п2 - п)/2, так как по определению" mii = 1 и тп = l/mij. Понятия, которыми оперируют эксперт, и интерпретация этих понятий значениями mij приведены в табл. 2.
| Смысл | mij |
| ) примерно равна μA(хj) | |
| μA(хi) немного больше μA(хj | |
| μA(хi) больше μA(хj | |
| μA(хi) заметно больше μA(хj | |
| μA(хi) намного больше μA(хj | |
| Значения, промежуточные по степени между перечисленными | 2,4,6,8 |
Вычисление значений функции принадлежности μA в точках x2,,x2,…,xn производится следующим образом
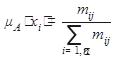
Другими словами, для определения величин μA(хi) необходимо зафиксировать произвольно выбранный столбец j матрицы М и вычислить отношение значений элементов тij к сумме значений всех элементов столбца j. При правильно проведенном экспертом опросе выбор столбцапрактически не влияет на правильность определения функции принадлежности.
Пример Пусть для описания расстояния между двумя точками применяется лингвистическая переменная β- "расстояние" с множеством базовых значений Т = I малое, среднее, большое 1. Пусть базовое множество Х = /1, 3, 6, 8/.
Терм "малое" характеризуется нечеткой переменной (малое, Х, С>. Требуется построить функцию принадлежности μС нечеткого множества С, описывающего терм "малое",
Т.е. определить значения μС(х), x Х. Опросом экспертов получена следующая матрица парных сравнений:
| 1 | 3 | 6 | 8 | |
| 1 | 1 | 5 | 6 | 7 |
| 3 | 1/5 | 1 | 4 | 6 |
| 6 | 1/6 | 1/4 | 1 | 4 |
| 8 | 1/7 | 1/6 | 1/4 | 1 |
Зафиксируем первый столбец матрицы М:
М1 = [1,1/5,1/6,1/7 ],
По формуле (1.1) получаем
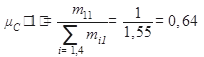
Аналогично вычисляются значения μС(3)=0,16, μС(6)= 0,11, μС(8)=0,08
Таким образом
С= |<0,64/1, <0,16/3>, <0,11/6>, <0,09/8>|
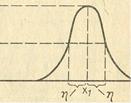
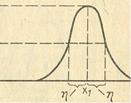
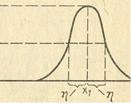
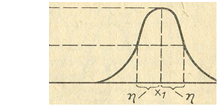
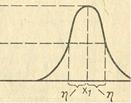
При использовании лингвистической переменной, задаваемой на непрерывном носителе (интервале действительных чисел), возникает задача хранения функций принадлежности (т.е. семантика значений лингвистической переменной) в памяти ЭВМ. Одним из возможных способов решения данной задачи является представление функции принадлежности в виде стандартной π -функции
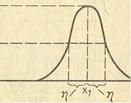
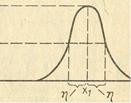
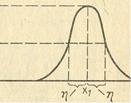
μA(х) = π(x,η,x1)
которая имеет следующий вид:
π(x,η,x1)= {: S(x,x1 - η, x1 - η/2, x1) при x=<x1
1 - S(x,x1 - η, x1 - η/2, x1) при x>x1
 |

 1
1

 0.5
0.5
η - η 
 x1
x1
 0 при x<=, ξ,
0 при x<=, ξ,
2(x1 –x)2/ (x – ξ)2 при ξ <=x<=, τ
S(x, ξ, τ, x1 )= 1 – 2(x1 – x)2/ (x- ξ)2 при τ<=x<=x1
1 x>=x1
Таким образом, любая функция принадлежности может быть представлена в памяти ЭВМ двумя параметрами: Х1 - величиной, при которой значение функции равно 1; η - величиной, при которой значение функции равно 0,5 (рис. 1.12).
При использовании введенной выше синтаксически независимой лингвистической переменной возникает задача определения ее семантики, Т.е. построения функций принадлежности, соответствующих. ее произвольным значениям. Рассмотрим подход к определению семантики синтаксически независимой лингвистической переменной, представленный в [27].
Пусть а1 =<x1,Х; C1> и а2 =<х2, X; С2> - два соседних базовых значения синтаксически независимой лингвистической переменной β: а' = <х', Х; С'> - произвольное значение, для которого выполняется условие x1<=x1 <=x2
Обозначим через <φ1,φ2 и φ1 следующие функции:
φ1(τ)=μ(x1 +τ);
φ2(τ)=μ(x2 +τ);
φ1(τ)=μ(x1 +τ);
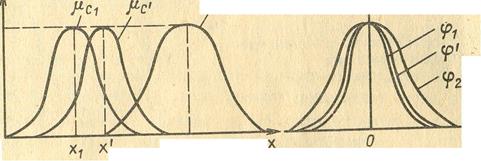
Можно предположить, что если значения α1 и α2 таковы, что φ1 = φ2, то и значение а' такое, что φ1 = φ1= φ2.
Далее, если для α1 и α2 такое условие не выполняется, то чем ближе значение x1 к x1 по сравнению с x2, тем менее значение функции φ1 отличается от φ1 и тем более от значения φ2 и наоборот.
При заданной функции принадлежностей с помощью стандартных π-функций задача определения произвольного значения а' = <х', Х; С'> -синтаксически независимой лингвистической переменной сводится к определению функции π(x, λ 1,x1) по заданным функциям π(x, λ 1,x1) и π(x, λ 2,x2) то есть к определения параметра λ 1 по λ 1 и λ 2.
Положим, что отношение отклонений λ 1 от λ 1 и λ 2 пропорционально отношению отклонений. x1 от x1 и x2
Тогда
(λ 1 – λ 1)/ (λ 1 – λ 2) = (x1 – x1)/ (x1 – x2)
Обозначив
η =(x2 – x1)/ (x2 – x1) получим λ 1 = η λ 1 +(1- η) λ 2
Очевидно, что λ 1 = λ 1 при x1 = x1 (значение η =1) и λ 1 = λ 2 при x1 = x2 (значение η =0)
Пример. Пусть базовыми значениями лингвистической переменной «толщина» являются высказывания «приблизительно 20мм» и «приблизительно 50мм» то есть
а1 = <20, Х; С1'> и а2 = <50, Х2 С2>
Вычислим произвольные значения, определяемые выражениями
а'= «приблизительно 25мм) и а» = «приблизительно 40мм»
μС1(х)= π (x,5,20) μС2(х)= π(x,11,50)
Тогда η а1= -5/6,η а2 = 1/6, λ1 = 6, λ11 = 10.
Функции принадлежности примут вид
μС1(х)= π (x,6,25) μС2(х)= π(x,10,40)
. Тогда произвольные значения – α’ "малая или средняя толщина" и α " - "небольшая толщина" будут определяться нечеткими множествами С’ и C”
с функциями принадлежности, показанными на рис. 1.9 и.10.
.
Лингвистические переменные, у которых процедура. образования новых значений G зависит от множества базовых значений Т, назовем синтаксически зависимыми лингвистическими переменными
Наряду с рассмотренными выше синтаксически зависимыми лингвистическими переменными существуют переменные, у которых процедура образования новых значений зависит не от множества базовых значений Т, а от области определения Х, Т.е. G = G(x). Например, значение лингвистической переменной "толщина изделия" определено как
"близкое к 20 мм" или ''приблизительно к 75 мм". Такие лингвистические переменные назовем синтаксически независимыми.

