 2015-06-05
2015-06-05 985
985Реляционная СУБД должна быть способна полностью управлять базой данных через ее реляционные возможности.
- Информационное правило - вся информация в реляционной БД (включая имена таблиц и столбцов) должна определяться строго как значения в таблицах.
- Гарантированный доступ - любое значение в реляционной БД должно быть гарантированно доступно для использования через комбинацию имени таблицы, значения первичного ключа и имени столбца
- Поддержка пустых значений (null value) - СУБД должна уметь работать с пустыми значениями (неизвестными или неиспользованными значениями), в отличие от значений по умолчанию и независимо для любых доменов.
- Онлайновый реляционный каталог - описание БД и ее содержания должны быть представлены на логическом уровне как таблицы, к которым можно применять запросы, используя язык базы данных.
- Исчерпывающий язык управления данными - по крайней мере, один из поддерживаемых языков должен иметь четко определенный синтаксис и быть всеобъемлющим. Он должен поддерживать описание структуры данных и манипулирование ими, правила целостности, авторизацию и транзакции.
- Правило обновления представлений (views) - все представления, теоретически обновляемые, могут быть обновлены через систему.
- Вставка, обновление и удаление - СУБД поддерживает не только запрос на отбор данных, но и вставку, обновление и удаление
- Физическая независимость данных - на программы-приложения и специальные программы логически не влияют изменения физических методов доступа к данным и структур хранилищ данных.
- Логическая независимость данных - на программы-приложения и специальные программы логически не влияют, в пределах разумного, изменения структур таблиц.
- Независимость целостности - язык БД должен быть способен определять правила целостности. Они должны сохраняться в онлайновом справочнике, и не должно существовать способа их обойти.
- Независимость распределения - на программы-приложения и специальные программы логически не влияет, первый раз используются данные или повторно.
- Неподрывность - невозможность обойти правила целостности, определенные через язык базы данных, использованием языков низкого уровня
Модель данных, или концептуальное описание предметной области - самый абстрактный уровень проектирования баз данных.
С точки зрения теории реляционных БД, основные принципы реляционной модели на концептуальном уровне можно сформулировать следующим образом:
- все данные представляются в виде упорядоченной структуры, определенной в виде строк и столбцов и называемой отношением;
- все значения являются скалярами. Это означает, что для любой строки и столбца любого отношения существует одно и только одно значение;
- все операции выполняются над целым отношением, и результатом их выполнения также является целое отношение. Этот принцип называется замыканием
Элементами описания реляционной модели данных на концептуальном уровне являются сущности, атрибуты, домены и связи
Сущность - некоторый обособленный объект или событие, информацию о котором необходимо сохранять в базе данных, имеющий определенный набор свойств - атрибутов. Сущности могут быть как физические (реально существующие объекты: например, СТУДЕНТ, атрибуты - № зачетной книжки, фамилия, его факультет, специальность, № группы и т.д.), так и абстрактные (например, ЭКЗАМЕН, атрибуты - дисциплина, дата, преподаватель, аудитория и пр.). Для сущностей различают ее тип и экземпляр. Тип характеризуется именем и списком свойств, а экземпляр - конкретными значениями свойств.
Атрибуты сущности бывают:
- Идентифицирующие и описательные. Идентифицирующие атрибуты имеют уникальное значение для сущностей данного типа и являются потенциальными ключами. Они позволяют однозначно распознавать экземпляры сущности. Из потенциальных ключей выбирается один первичный ключ (ПК). В качестве ПК обычно выбирается потенциальный ключ, по которому чаще происходит обращение к экземплярам записи. ПК должен включать в свой состав минимально необходимое для идентификации количество атрибутов. Остальные атрибуты называются описательными.
- Простые и составные. Простой атрибут состоит из одного компонента, его значение неделимо. Составной атрибут является комбинацией нескольких компонентов, возможно, принадлежащих разным типам данных (например, адрес). Решение о том, использовать составной атрибут или разбивать его на компоненты, зависит от особенностей процессов его использования и может быть связано с обеспечением высокой скорости работы с большими базами данных.
- Однозначные и многозначные - могут иметь соответственно одно или много значений для каждого экземпляра сущности.
- Основные и производные. Значение основного атрибута не зависит от других атрибутов. Значение производного атрибута вычисляется на основе значений других атрибутов (например, возраст человека вычисляется на основе даты его рождения и текущей даты
Спецификация атрибута состоит из его названия, указания типа данных и описания ограничений целостности - множества значений (или домена), которые может принимать данный атрибут.
Домен - это набор всех допустимых значений, которые может содержать атрибут. Понятие "домен" часто путают с понятием "тип данных". Необходимо различать эти два понятия. Тип данных - это физическая концепция, а домен - логическая. Например, "целое число" - это тип данных, а "возраст" - это домен.
Связи - на концептуальном уровне представляют собой простые ассоциации между сущностями. Например, утверждение "Покупатели приобретают продукты" указывает, что между сущностями "Покупатели" и "Продукты" существует связь, и такие сущности называются участниками этой связи.
Существует несколько типов связей между двумя сущностями: это связи " один к одному ", " один ко многим " и " многие ко многим ".
Каждая связь в реляционной модели характеризуется именем, обязательностью, типом и степенью. Различают факультативные и обязательные связи. Если сущность одного типа оказывается по необходимости связанной с сущностью другого типа, то между этими типами объектов существует обязательная связь (обозначается двойной линией). Иначе связь является факультативной.
Степень связи определяется количеством сущностей, которые охвачены данной связью. Пример бинарной связи - связь между отделом и сотрудниками, которые в нем работают.
Диаграмма "сущности-связи" (Entity-Relationship diagrams, или E/R diagram) служит для описания схемы базы на концептуальном уровне проектирования. Метод был предложен в 1976 г. Питером Пин Шань Ченом (Peter Pin Shan Chen) [2]. На диаграммах "сущности-связи" сущности изображаются в виде прямоугольников, атрибуты - в виде эллипсов, а связи - в виде ромбов (см. рис. 2.4).
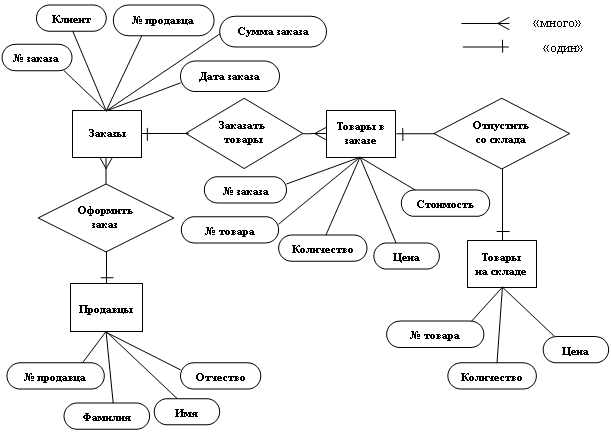
Рис. 2.4. Диаграмма "сущности-связи"
В дальнейшем многими авторами были разработаны свои варианты подобных моделей (нотация Мартина, нотация IDEF1X, нотация Баркера и др.).
Проектирование схемы БД должно решать задачи минимизации дублирования данных, упрощения и ускорения процедур их обработки и обновления. При неправильно спроектированной схеме БД могут возникнуть аномалии модификации данных. Для решения подобных проблем проводится нормализация отношений
Однако в технологии работы с хранилищами данных может использоваться обратный прием - денормализация отношений с целью увеличения скорости выполнения запросов к очень большим объемам архивных данных.
В рамках реляционной модели данных Э.Ф. Коддом были разработаны принципы нормализации отношений и предложен механизм, позволяющий любое отношение преобразовать к третьей нормальной форме.
Нормализация - это формальный метод анализа отношений на основе их первичного ключа и существующих связей. Ее задача - это замена одной схемы (или совокупности отношений) БД другой схемой, в которой отношения имеют более простую и регулярную структуру.
При работе с реляционной моделью для создания отношений приемлемого качества достаточно выполнения требований первой нормальной формы.
Первая нормальная форма (1НФ) связана с понятиями простого и сложного атрибутов. Простой атрибут - это атрибут, значения которого атомарны (т.е. неделимы). Сложный атрибут может иметь значение, представляющее собой объединение нескольких значений одного или разных доменов. В первой нормальной форме устраняются повторяющиеся атрибуты или группы атрибутов, т.е. производится выявление неявных сущностей, "замаскированных" под атрибуты.
Отношение приведено к 1НФ, если все его атрибуты - простые, т.е. значение атрибута не должно быть множеством или повторяющейся группой.
Для приведения таблиц к 1НФ необходимо разбить сложные атрибуты на простые, а многозначные атрибуты вынести в отдельные отношения.
Вторая нормальная форма (2НФ) применяется к отношениям с составными ключами (состоящими из двух и более атрибутов) и связана с понятиями функциональной зависимости.
Если в любой момент времени каждому значению атрибута A соответствует единственное значение атрибута B, то B функционально зависит от A (A  B). Атрибут (группа атрибутов) A называется детерминантом.
B). Атрибут (группа атрибутов) A называется детерминантом.
Во второй нормальной форме устраняются атрибуты, зависящие только от части уникального ключа. Эта часть уникального ключа определяет отдельную сущность.








