 2015-06-24
2015-06-24 548
548Общая структура репозитария Хранилища Данных — это отражение главной цели его построения, а именно, максимально полно и быстро удовлетворить потребности пользователей в той или иной информации. В зависимости от потребностей пользователей в информации можно выделить следующие основные типы данных.
Персональная информация — это информация, используемая пользователями со строго определенными обязанностями и информационными потребностями. Обычно требует большой предварительной обработки, т.е. имеет высокий уровень агрегации (под агрегацией мы понимаем не только суммирование, но и другие преобразования данных, производимые с помощью аддитивных и неаддитивных операций).
Информация по бизнес-темам — информация, относящаяся к определенной тематике (например, финансовая деятельность организации). Для организаций, имеющих близкие функциональные и организационные структуры, ее можно определить как информацию для подразделения (например, для финансовой службы), имеющую более широкий спектр как в предметных областях, так и во времени, но в то же время напрямую используемую реже, чем персонализированную информацию. Данные обычно хранятся в смешанных структурах: многомерные базы данных и реляционные таблицы.
Текущие детальные данные — самая подробная информация, доступная в Хранилище Данных. Обычными пользователями используется только в случае необходимости существенного уточнения информации. Такая информация обычно является полем деятельности аналитиков по поиску знаний (или поиску скрытых зависимостей в больших объемах информации); хранится в реляционных структурах.
Прошлые детальные данные — это тот же самый низкий уровень агрегирования, что и у текущих детальных данных. Выделяется в особый тип по следующей причине. С одной стороны, детальные данные часто требуют больших ресурсов для хранения, а с другой — детальные данные с возрастом (например, несколько лет) необходимы в очень редких случаях. Решением в данном случае является использование более дешевых и емких способов хранения, например, машинных лент или роботизированных библиотек.
Построение ИС на основе СУБД ORACLE 8i
Общая архитектура Хранилища Данных, реализованного средствами Oracle 8 i, представлена на рис. 2. Компоненты центральной части схемы отвечают за эффективное хранение данных, администрирование, проектирование структуры Хранилища и управление метаданными. Важнейшая задача, представленная на рисунке слева, — интеграция и согласование информации из различных источников путем ее извлечения, преобразования, очистки и загрузки в Хранилище Данных. Наконец, для нормальной работы конечных пользователей необходимо предоставить им аналитическую информацию в удобной и доступной форме — это обеспечивают компоненты правой части схемы. Существует целый спектр задач, связанных с организацией доступа к данным Хранилища, — от построения стандартных и нерегламентированных отчетов до сложного анализа типа «что-если», прогнозирования и алгоритмов «извлечения знаний» (Data Mining).
В качестве механизма хранения в реляционных Хранилищах и Витринах Данных используется сервер Oracle 8 i, в многомерных Витринах — Express Server. Центральное инструментальное средство — Oracle Warehouse Builder — построение на базе современной архитектуры Common Warehouse Metadata и позволяет спроектировать структуру целевого Хранилища, создать процедуры извлечения, согласования и загрузки данных из различных источников и сгенерировать метаданные. Для задач «извлечения знаний» используется Darwin Data Mining Suite.
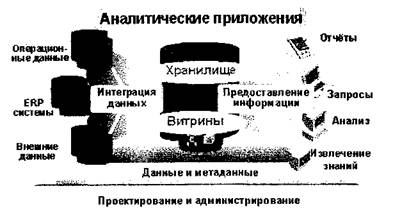
Рис. 2. Архитектура Хранилища Данных
Oracle Pure Integrate предоставляет мощные средства автоматической очистки данных, включающие алгоритмы нечеткой логики, синтаксический разбор имен и адресов, вероятностные модели и т.д.
Для решения аналитических задач высокого уровня, связанных со сложными расчетами, прогнозированием, моделированием сценариев «что-если» и т.д., применяется особая технология. Она реализована в виде семейства OLAP -продуктов Oracle Express. Express Server включает в себя мощный механизм аналитических вычислений, включающий в себя более сотни встроенных функций — математических, статистических, функций анализа временных рядов, финансовых и других. Все они могут быть использованы для быстрого построения новых расчетных показателей. Имеется и более продвинутая аналитика — алгоритмы прогнозирования, элементы регрессионного и частотного анализа, моделирование сценариев «что-если». В любой отчет встроен Селектор — графический инструмент нерегламентированных запросов, позволяющий конечному пользователю формулировать критерии отбора типа «Продажи каких продуктов из 20 имеющих наибольшую долю в общих продажах на 5 и более процентов ниже планируемых?» и получать соответствующие подмножества данных.








