 2015-07-03
2015-07-03 1625
1625Рассмотрим простой метод в котором объектный код генерируется для каждого фрагмента программы, как только распознан синтаксис этого фрагмента.
Каждому правилу грамматики и каждой альтернативе в правиле соответствует подпрограмма, генерирующая объектный код.
В более сложных компиляторах подобные семантические подпрограммы могут генерировать некоторую промежуточную форму представления программы, пригодную для последующего анализа с целью генерации более эффективного объектного кода.
Следует заметить, что методы генерации кода не связаны непосредственно с каким-либо конкретным методом грамматического разбора. Поэтому для обсуждения программы генерации кода мы будем руководствоваться грамматикой описанной в самом начале.
Очевидно, что генерируемый код зависит от того, на каком компьютере будет выполняться программа. Мы будем рассматривать генерацию кода для ПК с процессором Intel 80286.
Для рабочих данных будем использовать список и стек.
Переменная LISTCOUNT используется в качестве счетчика элементов списка. Используются также спецификаторы лексем.
Выражение S (id) являются именем соответствующего идентификатора или указателем на него в таблице символов. Для лексемы int выражение S (int) является значением соответствующего целого числа. Большинство семантических подпрограмм генерируют объектный код на языке машинных команд но мы будем записывать фрагменты генерируемого кода используя язык ассемблера.
После генерации каждого фрагмента кода указатель LOCCTR должен указывать на первую свободную ячейку компилируемой программы.
Проиллюстрируем процесс генерации объектного кода для предложения READ (VALUE). Оно имеет следующее дерево грамматического разбора.
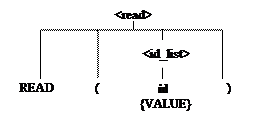
Независимо от используемого метода грамматического разбора на каждом шаге распознается самая левая подстрока входного текста, которая может быть интерпретирована в соответствии с каким либо из правил грамматики.
В методе рекурсивного спуска распознование происходит в тот момент, когда соответствующая процедура заканчивает свою работу с признаком успешного завершения.
Т.о. всегда будет сначала распознан идентификатор VALUE в качестве нетерминального символа <id_list>, а потом предложение в целом будет распознано в качестве нетерминального символа <read>.
Результирующий объектный код будет иметь вид:
LEA AX, VALUE
PUSH AX
MOV AX, 1
PUSH AX
CALL XREAD
Здесь мы сначала заносим в стек адреса переменных, которым должно быть присвоено значение в результате осуществления операции чтения.
Потом в стек заносим количество переменных и вызываем внешнюю процедуру XREAD.
Использование процедур позволяет избежать повторной генерации больших фрагментов программы.
В процедуре все передаваемые ей параметры извлекаются из стека.
Приведем набор подпрограмм, которые будут использоваться для генерации объектного кода.
<id_list>::= id
добавить S(id) в список
увеличить LISTCOUNT на 1
<id_list>::= <id_list>, id
добавить S(id) в список
увеличить LISTCOUNT на 1
<read>::= READ(<id_list>)
for каждого элемента списка do begin
извлечь из списка последний элемент в S(ITEM)
сгенерировать [ LEA AX, S(ITEM) ]
сгенерировать [ PUSH AX ]
end
сгенерировать [ MOV AX, LISTCOUNT ]
сгенерировать [ PUSH AX ]
LISTCOUNT:=0
сгенерировать [ CALL XREAD ]
внешние ссылки для XREAD
Первые две подпрограммы соответствуют двум альтернативам для нетерминального символа <id_list>. В любом случае спецификатор лексем S(id) для очередного идентификатора, включается в список, используемый программами генерации кода.
После того как нетерминальный символ <id_list> будет разобран, список будет содержать спецификаторы лексем для всех идентификаторов, содержащихся в <id_list>.
Когда будет распознано предложение <read>, эти спецификаторы лексем будут удалены из списка и использованы для генерации объектный кода операции READ.
В процессе генерации дерева грамматического разбора вначале распознается <id_list>, а уже потом <read>. На каждом шаге вызывается соответствующая подпрограмма генерации объектного кода.
Обратите внимание на то, что для вызова библиотечных процедур «список» используется как стек, но в других случаях он будет использоваться действительно как очередь.
Рассмотрим теперь процесс генерации объектного кода для присваивания:
VARIANCE:= SUMSQ DIV 100 – MEAN * MEAN
Еще раз нарисуем дерево грамматического разбора.
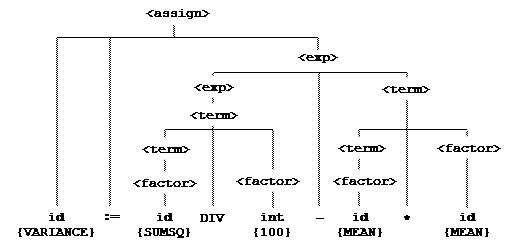 |
Основная работа при разборе этого предложения состоит в анализе нетерминального символа <exp> в правой части оператора присваивания.
Идентификатор SUMSQ распознается сначала как <factor>, а потом как <term>.
Далее распознается целое число 100 как <factor>; затем фрагмент SUMSQ DIV 100 распознается как <term> и т. д.
Порядок распознавания фрагментов этого предложения совпадает с порядком, в котором должны выполняться соответствующие вычисления.
Предположим, что мы хотим сгенерировать код, соответствующий правилу:
<term>1::= <term>2 * <factor>
Индексы здесь используются для различия двух вхождений нетерминального символа <term>.
Наши подпрограммы генерации кода выполняют все арифметические операции с использованием регистра AX, и мы заведомо должны сгенерировать в объектном коде операцию MUL.
Результат этого умножения <term>1 после операции MUL сохраниться в регистре AX.
Если либо <term>2 , либо <factor> уже находятся в регистре AX (после выполнения предыдущих вычислений), то генерация инструкции MUL – это почти все что нам нужно.
Иначе мы должны сгенерировать также инструкцию MOV для загрузки в AX одного из сомножителей. В этом случае нам также надо предварительно сохранить значение регистра AX, если оно понадобиться в будущем.
Очевидно, необходимо отслеживать значение, помещенное в регистр AX, после каждого фрагмента (генерируемого объектного кода). Это можно осуществить за счет расширения понятия спецификатора лексемы на нетерминальные узлы дерева грамматического разбора.
В нашем примере спецификатору узла S (<term>) будет присвоено значение rAX, указывающее на то, что результат этих вычислений содержится в регистре AX. Переменная REGAX используется для указания на самый высокий уровень узла дерева грамматического разбора, значение которого помещено в регистр AX в сгенерированном до данного момента объектном коде (т.е. указатель на узел, спецификатор которого равен rAX).
В каждый момент существует ровно один такой узел.
Если же в регистре AX нет значения, соответствующего некоторому узлу, то спецификатор этого узла аналогичен спецификатору лексемы: это либо указатель на переменную (в таблице символов), содержащую соответствующее значение, либо указатель на целую константу.
Запишем подпрограммы необходимые для генерации кода, оператора присвоения.
<assign>::= id:= <exp>
GETAX (<exp>)
сгенерировать [ MOV S(id), AX ]
REGAX:= NULL
<exp>::= <term>
S(<exp>):= S(<term>)
if S(<exp>)=rAX then
REGAX:= <exp>
<exp>1::= <exp>2 + <term>
if S(<exp>2)=rAX then
сгенерировать [ ADD AX, S(<term>) ]
else
if S(<term>)=rAX then
сгенерировать [ ADD AX, S(<exp>2) ]
else begin
GETAX(<exp>2)
сгенерировать [ ADD AX, S(<term>)]
end
S(<exp>1):= rAX
REGAX:= <exp>1
<exp>1::= <exp>2 - <term>
if S(<exp>2)=rAX then
сгенерировать [ SUB AX, S(<term>)]
else begin
GETAX(<exp>2)
сгенерировать [ SUB AX, S(<term>)]
end
S(<exp>1):= rAX
REGAX:= <exp>1
<term>::= <factor>
S(<term>):= S(<factor>)
if S(<term>)=rAX then
REGAX:= <term>
<term>1::= <term>2 * <factor>
if S(<term>2)=rAX then
сгенерировать [ MUL S(<factor>) ]
else
if S(<factor>)=rAX then
сгенерировать [ MUL S(<term>2) ]
else begin
GETAX(<term>2)
сгенерировать [ MUL S(<factor>) ]
end
сгенерировать [ CALL CHECK ]
S(<term>1):= rAX
REGAX:= <term>1
<term>1::= <term>2 div <factor>
if S(<term>2)=rAX then
сгенерировать [ DIV AX, S(<factor>) ]
else begin
сгенерировать [ DIV AX, S(<factor>) ]
GETAX(<term>2)
end
S(<term>1):= rAX
REGAX:= <term>1
<factor>::= id
S (<factor>):= S(id)
<factor>::= int
S(<factor>):= S(int)
<factor>::= (<exp>)
S(<factor>):= S(<exp>)
procedure GETAX(NODE)
begin
if REGAX=NULL then
сгенерировать [ MOV AX, S(NODE) ]
else
if S(NODE)<>rAX then begin
породить новую рабочую переменную Тi
сгенерировать [ MOV Тi,AX ]
(ссылки вперед на Тi)
S(REGAX):= Тi
сгенерировать [ MOV AX, S(NODE) ]
end
S(NODE):= rAX
REGAX:= NODE
end {GETAX}
Рассмотрим правило <term>1::= <term>2 DIV <factor>
Если спецификатор узла какого-либо из операторов равен rAX, то соответствующее значение уже содержится в регистре AX и программа генерирует только конструкцию MUL.
Адрес операнда для инструкции MUL содержится в идентификаторе узла другого операнда (значение которого не находится в регистре AX).
В противном случае вызывается процедура GETAX. Эта процедура генерирует инструкцию MOV для загрузки значения, связанного со значением <term>2, в регистре AX.
Если REGAX не равно NULL то перед загрузкой содержимое регистра AX сохраняется в некоторой рабочей переменной.
Рабочие переменные образуются в процессе генерации объектного кода (с именами Т1,Т2,…) по мере необходимости.
Для рабочих переменных будет отведено место в конце объектной программы.
На узел дерева грамматического разбора, связанный со значением, содержащимся в регистре AX, указывает переменная REGAX.
Спецификатор этого узла модифицируется, чтобы указывать на рабочую переменную для хранения этого значения.
После того, как все необходимые инструкции сгенерированы, программа генерации кода устанавливает спецификатор S(<term>1) и переменную REGAX таким образом, чтобы было видно, что значение, соответствующее <term>1, находится в регистре AX.
На этом процедура для операции «*» завершается.
Подпрограмма для операции «+» аналогична, а подпрограммы для «DIV» и «-» отличаются только тем, что для этих операций необходимо, чтобы в регистре АХ был загружен именно первый операнд.
Программа генерации кода для операции присваивания <assign> состоит в загрузке присваемой величины в регистр АХ (с использованием GETAX) и генерации инструкции MOV.
Обратите внимание, что переменная REGAX потом обнуляется, поскольку код, соответствующий оператору, полностью сгенерирован и все промежуточные результаты больше не нужны.
Некоторые правила не требуют генерации каких-либо машинных инструкций. Программы генерации кодов для этих правил должны соответствующим образом установить спецификатор для узла самого верхнего уровня, чтобы он указывал на ячейку, содержащую соответствующее значение.
В результате разбора оператора присвоения будет сгенерирован следующий код.
MOV AX, SUMSQ; VARIANCE:= SUMSQ DIV 100 - MEAN * MEAN
DIV AX, 100
MOV T1, AX
MOV AX, MEAN
MUL MEAN
CALL CHECK
MOV T2, AX
MOV AX, T1
SUB AX, T2
MOV VARIANCE, AX
Запишем другие подпрограммы генерации объектного кода для нашей грамматики.
< prog >::= PROGRAM <prog_name> VAR <dec_list> BEGIN <stmt_list> END.
сгенерировать [RET]
for каждой используемой переменной Ti do
сгенерировать [ Ti DW? ]
вставить [ JMP EXADDR ] в байты … объектной программы
{переход на первое выполняемое предложение}
сформировать ссылки вперед на переменные Ti
сгенерировать запись-модификатор для внешних ссылок
сгенерировать [ CSEG ENDS ]
сгенерировать [ END (<prog_name>) ]
< prog_name >::= id
сгенерировать [ CSEG SEGMENT ]
сгенерировать [ ASSUME CS:CSEG, DS:CSEG ]
сгенерировать [ EXTRN XREAD, XWRITE ]
сгенерировать [ S(id): PUSH CS ]
сгенерировать [ POP DS ]
увеличить LOCCTR на 3
{место для команды перехода на первое выполняемое предложение}
< dec_list >::= {любые альтернативы}
сохранить LOCCTR в качестве EXADDR
<dec >::= <id_list>: <type>
for каждого элемента списка do begin
исключить S(NAME) из списка
занести LOCCTR в таблицу символов в качестве адреса NAME
сгенерировать [ S(NAME) DW? ]
end
LISTCOUNT:= 0
< type >::= INTEGER
{не нужны никакие действия по генерации кода}
< stmt_list> ::= {любые альтернативы}
{не нужны никакие действия по генерации кода}
< stmt >::= {любые альтернативы}
{не нужны никакие действия по генерации кода}
< write >::= WRITE (<id_list>)
for каждого элемента списка do begin
извлечь из списка последний элемент и помесить его в S(ITEM)
сгенерировать [ MOV AX, S(ITEM) ]
сгенерировать [ PUSH AX ]
end
сгенерировать [ MOV AX, LISTCOUNT ]
сгенерировать [ PUSH AX]
LISTCOUNT:= 0
сгенерировать [ CALL XWRITE ]
внешние ссылки для XWRITE
< for >::= FOR <index_exp> DO <body>
взять из стека JAMPADDR {адрес команды выхода из цикла}
взять из стека S(INDEX) {индексная переменная}
взять из стека LOOPADDR {адрес начала цикла}
сгенерировать [ MOV AX, S(INDEX) ]
сгенерировать [ INC AX ]
сгенерировать [ JMP LOOPADDR ]
вставить [ JMP LOCCTR ] в ячейку с адресом JUMPADDR
< index-exp >::= id:= <exp>1 TO <exp>2
GETAX(<exp>1)
поместить в стек LOCCTR {адрес начала цикла}
поместить в стек S(id) {индексная переменная}
сгенерировать [ MOV S(id), AX ]
сгенерировать [ CMP AX, S(<exp>2) ]
сгенерировать [ JNG LOCCTR+3 ]
помесить в стек LOCCTR {адрес команды выхода из цикла}
увеличить LOCCTR на 3 байта {место для команды перехода}
REGAX:= NULL
< body >::= {любые альтернативы}
{не нужны никакие действия по генерации кода}
Подпрограмма для <prog_name> генерирует заголовок объектной программы, аналогичной результату работы директив ассемблера SEGMENT, ASSUME и EXTRN.Она также генерирует команды обеспечивающие равенство регистра DS регистру CS и сохранение места для команды перехода на первую выполняемую инструкцию компилируемой программы.
После того как вся программа распознана, генерируется команда завершения программы RET и резервируется память для рабочих переменных (Ti). Затем все ссылки на эти переменные фиксируются в объектном коде с использованием процедуры обработки ссылок вперед, осуществляемой однопросмотровым ассемблером. Компилятор генерирует также модифицирующие записи, необходимые для описания внешних ссылок на библиотечные подпрограммы.
Затем генерируется код, соответствующий командам ассемблера ENDS и END с указанием точки входа а программу.
Генерация кода для предложения <for> состоит из нескольких шагов. После того как распознан нетерминальный символ <index_exp>, генерируется код для инициализации индексной переменной цикла и инструкции проверки конца цикла. Часть информации также записывается в стек для дальнейшего использования.
Далее независимо генерируется коды для каждого предложения составляющего тело цикла.
После того, как вся конструкция <for> распознана, генерируется код увеличивающий индексную переменную и осуществляющий возврат на начало цикла для проверки условий его завершения.
Здесь программа генерации кода использует информацию, записанную в стек.
Использование стека позволяет обрабатывать и вложенные циклы <for>.
Вы можете проследить процесс генерации кода для всей программы, используя дерево грамматического разбора всей программы (которое мы с вами ранее построили) в качестве управляющей информации.
Результат должен получиться такой.
Символьное представление объектного кода, сгенерированного для программы STATS
| CSEG | SEGMENT | ||
| ORG | 100 H | ||
| ASSUME | CS:CSEG, DS:CSEG | ||
| EXTRN | XREAD, XWRITE | ||
| STATS: | PUSH | CS | |
| POP | DS | ||
| JMP | EXADDR | ||
| SUM | DW | ? | |
| SUMSQ I VALUE MEAN VARIANCE | DW DW DW DW DW | ? ? ? ? ? | |
| EXADDR: | MOV MOV | AX, 0; SUM:= 0 SUM, AX | |
| MOV MOV | AX, 0; SUMSQ:= 0 SUMSQ, AX | ||
| L1: L2: | MOV MOV CMP JNG JMP MOV | AX, 1; FOR I:=1 TO 100 I, AX AX, 100 L2 L3 I, AX | |
| LEA PUSH MOV PUSH CALL | AX, VALUE; READ (VALUE) AX AX, 1 AX XREAD | ||
| MOV ADD MOV | AX, SUM; SUM:= SUM + VALUE AX, VALUE SUM, AX | ||
| MOV MUL CALL ADD MOV MOV INC JMP | AX, VALUE; SUMSQ:=SUMSQ+VALUE*VALUE VALUE CHECK AX, SUMSQ SUMSQ, AX AX, I; конец цикла FOR AX L1 | ||
| L3: | MOV DIV MOV | AX, SUM; MEAN:= SUM DIV 100 AX, 100 MEAN, AX | |
| MOV DIV MOV MOV MUL CALL MOV MOV SUB MOV | AX, SUMSQ; VARIANCE:=SUMSQ DIV 100 - AX, 100; MEAN * MEAN T1, AX AX, MEAN MEAN CHECK T2, AX AX, T1 AX, T2 VARIANCE, AX | ||
| T1 T2 CSEG | MOV PUSH MOV PUSH MOV PUSH CALL RET DW DW ENDS END | AX, VARIANCE; WRITE(MEAN,VARIANCE) AX AX, MEAN AX AX, 2 AX XWRITE ?; используемые рабочие ?; переменные ; конец сегмента STATS; точка входа |

