2015-07-21
2015-07-21 2551
2551Лексический анализ (ЛА) - это первый этап процесса трансляции. Основная задача лексического анализа – разбить входной текст, состоящий из последовательности символов алфавита, на минимально значимые части языка, называемые лексемами. Лексемами естественных языков являются слова. В языках программирования встречаются лексемы различных типов (рис.3.1), состав которых определяется синтаксисом конкретного языка программирования.
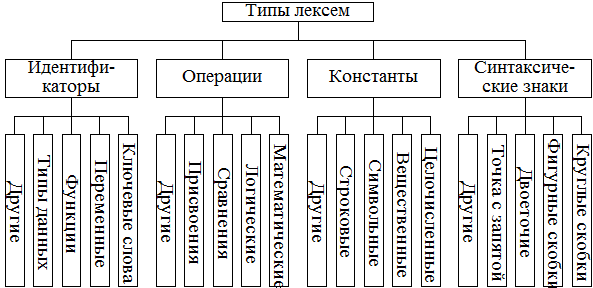 |
Рис.3.1 Типы лексем языков программирования
Все символы входной последовательности можно разделить на символы, принадлежащие каким-либо лексемам, и символы, разделяющие лексемы (терминальные символы). В некоторых случаях между лексемами может и не быть разделителей (например: между числами и знаками операций). В некоторых языках символы разделители могут блокироваться специальными символами (например: в Си в строке "ааа\"ббб" – вторая кавычка не заканчивает строку, потому что блокируется ‘\’).
Таким образом, лексический анализатор (сканер) - это транслятор, входом которого служит цепочка символов, представляющих исходную программу, а выходом - последовательность лексем. При этом каждой лексеме сопоставляется пара (тип_лексемы, указатель_на_информацию_о_ней). Выбор конструкций, которые будут выделяться как отдельные лексемы, зависит от языка программирования и от точки зрения разработчиков транслятора.
Теоретически лексический анализатор не является обязательной частью транслятора, так как все его функции могут выполняться синтаксическим анализатором. На практике существует ряд причин, по которым лексический анализатор включают в состав почти всех компиляторов как самостоятельный элемент:
- замена в программе идентификаторов, констант, знаков операций, ограничителей и служебных слов лексемами делает представление программы более удобным для дальнейшей обработки;
- лексический анализ уменьшает длину программы, устраняя из ее исходного представления несущественные пробелы и комментарии;
- для решения задач лексического анализа возможно применять простую и эффективную технику анализа, в то время как для синтаксического разбора используются достаточно сложные алгоритмы;
- при изменении версии входного языка достаточно будет перестроить относительно простой лексический анализатор, не затрагивая сложный по конструкции синтаксический анализатор.
Функционирование сканера и синтаксического анализатора тесно взаимосвязано, поскольку результаты работы сканера представляют собой исходные данные для синтаксического разбора; кроме того, в некоторых языках смысл лексемы зависит от ее контекста, поэтому невозможно провести лексический анализ в отрыве от синтаксического.
Существует два метода организации взаимодействия лексического и синтаксического анализаторов – последовательный и параллельный.
При реализации последовательного варианта взаимодействия (рис. 3.2., а) сканер просматривает весь текст исходной программы один раз от начала до конца и преобразует его в таблицы лексем, где выделенные лексемы заменяются соответствующими кодами.
В случае параллельного взаимодействия (рис. 3.2., б) синтаксический анализатор после разбора очередной конструкции языка обращается к сканеру за следующей лексемой. При этом сканер может получать дополнительную информацию от лексического анализатора о типе лексемы, которая ожидается. С точки зрения обработки значений лексем, сканер может либо просто выдавать значение каждой лексемы, и в этом случае построение таблиц лексем переносится на более поздние фазы, либо он может самостоятельно строить таблицы лексем. В этом случае в качестве значения лексемы выдается индекс (указатель) в соответствующей таблице. В процессе разбора при возникновении ошибки может происходить «откат назад», чтобы проанализировать синтаксическую конструкцию (оператор языка программирования) на другой основе.
 |
а) Последовательное взаимодействие
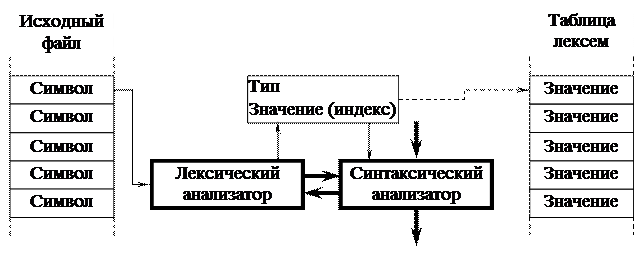
б) Параллельное взаимодействие
Рис. 3.2. Варианты схемы взаимодействия сканера и синтаксического анализатора
Последовательный метод взаимодействия лексического и синтаксического анализаторов более прост и эффективен, но подходит не для всех языков. Возможность его применения определяется синтаксическими правилами языка, то есть грамматикой. В некоторых языках (например, Fortran) ключевые слова могут использоваться как обычные идентификаторы – в этом случае работа сканера не может идти независимо от синтаксического анализатора. Большинство распространенных в настоящее время языков (например, С и Pascal) позволяют применить последовательный вариант реализации.
В качестве примера таблицы лексем рассмотрим некоторый фрагмент кода на языке Си и соответствующую ему таблицу лексем, представленную в таблице 3.1:
…
for(int i=0; i<N; i++) ss *= 0.5;
…
Таблица 3.1
| Лексема | Тип лексемы | Код лексемы |
| for | Ключевое слово | Х1 |
| ( | Открывающая скобка (ограничитель) | ( |
| int | Ключевое слово | Х2 |
| i | Идентификатор | i: 1 |
| = | Знак операции присваивания | = |
| Целая константа | ||
| ; | Точка с запятой (ограничитель) | ; |
| i | Идентификатор | i: 1 |
| < | Знак операции сравнения | < |
| N | Идентификатор | N: 2 |
| ; | Точка с запятой (ограничитель) | ; |
| i | Идентификатор | i: 1 |
| ++ | Знак операции инкремента | ++ |
| ) | Закрывающая скобка (ограничитель) | ) |
| ss | Идентификатор | ss: 3 |
| *= | Знак операции умножения с присваиванием | *= |
| 0.5 | Вещественная константа | 0.5 |
| ; | Точка с запятой (ограничитель) | ; |
В качестве кодов лексем использованы условные значения (конкретные коды определяются реализацией компилятора). Кодовые значения лексем помещаются в итоговую таблицу лексем. Для идентификаторов строится еще одна таблица – таблица идентификаторов (или несколько таблиц). Таблица лексем связывается с таблицей идентификаторов с помощью ссылок на индексы строк или указанием конкретных адресов идентификаторов. Таблица идентификаторов является важным элементом процесса трансляции, и способ ее организации существенно влияет на эффективность этого процесса, поскольку транслятор неоднократно обращается к таблице идентификаторов в ходе своей работы. Существуют различные методы организации таблиц идентификаторов, некоторые из них рассматриваются в п. 3. 2.
Анализ ключевых слов представляет отдельную проблему. Здесь возможны два основных способа. Первый способ: очередная лексема диагностируется на совпадение с каким-либо ключевым словом по мере поступления литер на вход сканера, а в случае неуспеха делается попытка выделить лексему из какого-либо другого класса; в этом случае все ключевые слова непосредственно встраиваются в программу-сканер. Второй способ: после выборки лексемы идентификатора происходит обращение к таблице ключевых слов на предмет сравнения; в данном случае лексический анализатор содержит только разбор идентификаторов.
Обобщенный алгоритм работы простейшего лексического анализатора в компиляторе можно описать следующим образом:
(1) из входного потока выбирается очередной символ (символ может быть также проигнорирован либо признан ошибочным); в зависимости от текущего символа запускается тот или иной сканер (сканеров может быть несколько, каждый из которых соответствует определенному типу лексем);
(2) запущенный сканер просматривает входной поток символов программы на исходном языке, выделяя символы, входящие в требуемую лексему, до обнаружения очередного символа, который может ограничить лексему, либо до обнаружения ошибочного символа;
(3) при успешном распознавании информация о выделенной лексеме заносится в таблицу лексем и таблицу идентификаторов, сканер возвращается к первому шагу алгоритма и продолжает рассматривать входной поток символов с того места, на котором остановился сканер;
(4) при неуспешном распознавании выдается сообщение об ошибке, а дальнейшие действия зависят от реализации сканера – либо его выполнение прекращается, либо делается попытка распознать следующею лексему (идет возврат к первому шагу алгоритма).
Язык лексем, с которыми работает сканер, можно описать с помощью регулярных грамматик.
Например,
идентификатор (I): I ® a|b|...|z|Ia|Ib|...|Iz|I0|I1|...|I9
целое без знака (N): N® 0|1|...|9|N0|N1|...|N9
...
Для регулярных грамматик существует простой и эффективный алгоритм анализа того, принадлежит ли заданная цепочка языку, порождаемому этой грамматикой (п. 3.3).