 2015-07-21
2015-07-21 3040
3040Поскольку в реальных исходных текстах программ количество идентификаторов достаточно велико, то даже логарифмическую зависимость времени поиска заданного идентификатора от общего числа идентификаторов нельзя признать удовлетворительной. Сделать поиск информации в таблице идентификаторов более эффективным позволяет использование методов хеширования, которые практически всегда применяются в той или иной степени при построении таблиц идентификаторов в реальных компиляторах.
Сущность метода заключается в том, что индекс элемента в таблице идентификаторов получают путем "хеширования" идентификатора, а именно - применением к нему хеш-функции.
Хеш-функцией H называется некоторое отображение множества входных элементов R на множество целых неотрицательных чисел Z:
H(r)=n, где rÎR, nÎZ.
В нашем случае областью определения R хеш-функции H является множество всех возможных имен идентификаторов, а областью значений – некоторое подмножество М из множества целых неотрицательных чисел Z: MÌZ, состоящее из всех возможных значений, вырабатываемых функцией H, то есть "rÎR: H(r)ÎM.
Термин «хеш-функция» (hash function) происходит от английского hash – перемалывать, смешивать.
Процесс отображения области определения хеш-функции на множество ее значений называется хешированием.
В русскоязычной литературе метод хеширования часто называют методом преобразования ключей или просто «расстановкой», а хеш-функцию, соответственно, - функцией расстановки.
Хеш-адресация заключается в использовании значения, возвращаемого хеш-функцией, в качестве индекса (адреса) элемента в некотором массиве данных (в нашем случае – таблицы идентификаторов).
Очевидно, что размер массива данных должен соответствовать области значений используемой хеш-функции, откуда следует, что область значений хеш-функции не должна превышать размер доступного адресного пространства компьютера.
Таким образом, метод организации таблиц идентификаторов с использованием хеширования заключается в размещении каждого идентификатора в той строке таблицы, индекс которой получен путем вычисления хеш-функции для данного идентификатора.
В общем случае для размещения или поиска идентификатора в таблице необходимо вычислить его хеш-функцию и обратиться по полученному индексу к соответствующей строке таблицы.
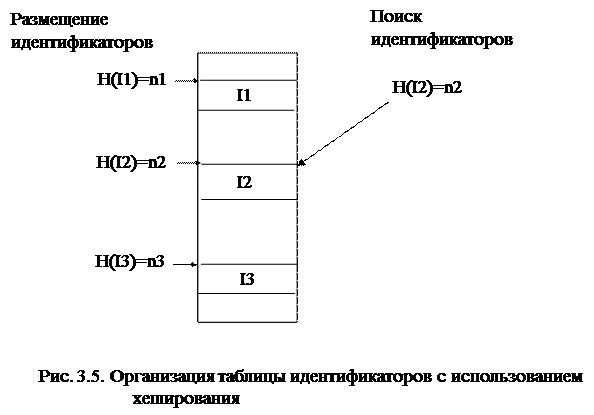
Метод хеширования весьма эффективен, поскольку время размещения и время поиска идентификатора в таблице определяется только временем вычисления хеш-функции. Однако рассмотренный выше способ организации таблицы идентификаторов имеет и очевидные недостатки. Во-первых, память при такой организации хеш-таблицы используется неэффективно, поскольку размер массива для ее хранения должен соответствовать области значений хеш-функции, в то время как реально хранимых в таблице данных будет значительно меньше. Во-вторых, непростой задачей является разумный выбор хеш-функции. Хеш-функция должна вычисляться достаточно эффективно, то есть состоять из небольшого числа основных арифметических и логических операций, а также равномерно отображать значения идентификаторов на весь диапазон изменения индексов массива, в котором будут храниться идентификаторы.
Собственно хеш-функция представляет собой некоторый набор простых арифметических и логических действий, производимых над идентификатором. В качестве примера примитивной хеш-функции можно привести код внутреннего представления в ЭВМ первой литеры идентификатора.
Пока для двух различных элементов результаты хеширования различны, время поиска совпадает со временем, затраченным на хеширование. Однако возникает затруднение, когда результаты хеширования двух разных элементов совпадают. Это называется коллизией. В одну позицию таблицы может быть помещен только один из конфликтующих элементов. Удачная хеш-функция распределяет элементы в таблице равномерно, так что коллизии возникают не столь часто. Хеш-функция, предложенная выше, очевидно неудачна, так как все идентификаторы, начинающиеся с одной буквы, ссылаются на один и тот же адрес. Существует множество различных хеш-функций, но ни одна из них не позволяет полностью избавиться от коллизий. На практике при разработке алгоритма хеш-функции обычно стремятся максимально уменьшить количество возникающих коллизий для ограниченного набора идентификаторов, а именно, тех идентификаторов, которые наиболее часто встречаются в программах. С этой целью производится статистическая обработка данных для определенного множества типичных программ.
Для разрешения коллизий существует достаточно много способов. Одним из наиболее удачных является метод цепочек. Метод цепочек использует кроме таблицы идентификаторов дополнительную хеш-таблицу, которая должна быть пустой в начале работы алгоритма. Таблица идентификаторов формируется динамически по мере добавления в нее элементов и представляет собой совокупность однонаправленных списков (цепочек). Каждый элемент списка включает в себя кроме значения идентификатора дополнительное поле ссылки на следующий элемент списка. Адреса образующихся списков хранятся в хеш-таблице.
При добавлении идентификатора в таблицу для него вычисляется хеш-функция (адрес ячейки в хеш-таблице). Если ячейка в хеш-таблице по вычисленному адресу пустая, то динамически выделяется память под первый элемент списка, куда заносится значение идентификатора. Адрес первого элемента списка заносится в соответствующую ячейку хеш-таблицы. В противном случае происходит переход по ссылкам в конец списка, и туда добавляется еще один элемент (динамически выделяется память, в выделенную область памяти записывается значение идентификатора, а адрес выделенного участка памяти заносится в поле ссылки предыдущего элемента).
При поиске необходимого элемента цепочка просматривается до тех пор, пока не будет встречен нужный элемент или цепочка не закончится (тогда элемент не найден).
Интересным вариантом является комбинирование метода цепочек с другими вариантами организации таблиц символов: цепочка идентификаторов с одинаковым значением хеш-функции может представлять собой неупорядоченный или упорядоченный списки, либо, например, бинарное дерево. В зависимости от способа организации цепочки меняются соответственно и методы поиска.
Метод цепочек является очень эффективным средством организации таблиц идентификаторов. Среднее время на размещение или поиск элемента зависит только от среднего числа коллизий, возникающих при вычислении хеш-функции. Этот метод позволяет более экономно использовать память, но требует затрат на организацию работы с динамическими структурами данных.








