 2015-08-12
2015-08-12 4396
4396Стандарт предложен в 1991 году некоммерческой организацией «Консорциум Юникода» (англ. Unicode Consortium, Unicode Inc.). Применение этого стандарта позволяет закодировать очень большое число символов из разных письменностей: в документах Unicode могут соседствовать китайские иероглифы, математические символы, буквы греческого алфавита, латиницы и кириллицы, при этом становится ненужным переключение кодовых страниц.
Стандарт состоит из двух основных разделов: универсальный набор символов (англ. UCS, universal character set) и семейство кодировок (англ. UTF, Unicode transformation format). Универсальный набор символов задаёт однозначное соответствие символов кодам — элементам кодового пространства, представляющим неотрицательные целые числа. Семейство кодировок определяет машинное представление последовательности кодов UCS.
Стандарт Unicode был разработан с целью создания единой кодировки символов всех современных и многих древних письменных языков. Каждый символ в этом стандарте кодируется 16 битами, что позволяет ему охватить несравненно большее количество символов, чем принятые ранее 8-битовые кодировки. Еще одним важным отличием Unicode от других систем кодировки является то, что он не только приписывает каждому символу уникальный код, но и определяет различные характеристики этого символа, например:
- тип символа (прописная буква, строчная буква, цифра, знак препинания и т.д.);
- атрибуты символа (отображение слева направо или справа налево, пробел, разрыв строки и т.д.);
- соответствующая прописная или строчная буква (для строчных и прописных букв соответственно);
- соответствующее числовое значение (для цифровых символов).
Весь диапазон кодов от 0 до FFFF разбит на несколько стандартных подмножеств, каждое из которых соответствует либо алфавиту какого-то языка, либо группе специальных символов, сходных по своим функциям. На приведенной ниже схеме содержится общий перечень подмножеств Unicode 3.0 (рисунок 2).
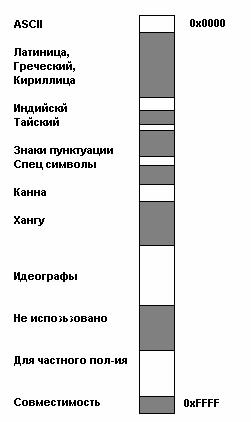
Рисунок 2
Стандарт Unicode является основой для хранения и текста во многих современных компьютерных системах. Однако, он не совместим с большинством Интернет-протоколов, поскольку его коды могут содержать любые байтовые значения, а протоколы обычно используют байты 00 - 1F и FE - FF в качестве служебных. Для достижения совместимости были разработаны несколько форматов преобразования Unicode (UTFs, Unicode Transformation Formats), из которых на сегодня наиболее распространенным является UTF-8. Этот формат определяет следующие правила преобразования каждого кода Unicode в набор байтов (от одного до трех), пригодных для транспортировки Интернет-протоколами.
| Диапазон Unicode | Двоичный код символа | Байты UTF-8 (двоичные) |
| 0000 - 007F | 00000000 0zzzzzzz | 0zzzzzzzz |
| 0080 - 07FF | 00000yyy yyzzzzzz | 110yyyyy 10zzzzzz |
| 0800 - FFFF | xxxxyyyy yyzzzzzz | 1110xxxx 10yyyyyy 10zzzzzz |
Здесь x,y,z обозначают биты исходного кода, которые должны извлекаться, начиная с младшего, и заноситься в байты результата справа налево, пока не будут заполнены все указанные позиции.
Дальнейшее развитие стандарта Unicode связано с добавлением новых языковых плоскостей, т.е. символов в диапазонах 10000 - 1FFFF, 20000 - 2FFFF и т.д., куда предполагается включать кодировку для письменностей мертвых языков, не попавших в таблицу, приведенную выше. Для кодирования этих дополнительных символов был разработан новый формат UTF-16.
Таким образом, существует 4 основных способа кодировки байтами в формате Unicode:
UTF-8: 128 символов кодируются одним байтом (формат ASCII), 1920 символов кодируются 2-мя байтами ((Roman, Greek, Cyrillic, Coptic, Armenian, Hebrew, Arabic символы), 63488 символов кодируются 3-мя байтами (Китайский, японский и др.) Оставшиеся 2 147 418 112 символы (еще не использованы) могут быть закодированы 4, 5 или 6-ю байтами.
UCS-2: Каждый символ представлен 2-мя байтами. Данная кодировка включает лишь первые 65 535 символов из формата Unicode.
UTF-16:Является расширением UCS-2, включает 1 114 112 символов формата Unicode. Первые 65 535 символов представлены 2-мя байтами, остальные - 4-мя байтами.
USC-4: Каждый символ кодируется 4-мя байтами.








