2015-08-21
2015-08-21 493
493START 1000 Закончить моделирование через 1000 циклов
Так как моделируется СМО вида М/М/1, то согласно формуле (1.7) при С=1 теоретическое среднее время пребывания в СМО Т= 1800, а результаты моделирования дают Т= 1833,053+440,258 для 90% доверительной вероятности (MEIN ± DELTA). Теоретический коэффициент загрузки равен 0,9, а по результатам моделирования 0,901. Как видно, полученные результаты близкие к теоретическим.
Приведенная программа может быть использована для любой i регенерирующей модели. Для этого между метками INP и OUT нужно вставить программу регенерирующей модели. Проверка циклов i регенерации осуществляется по количеству транзактов, которые находятся между этими метками. Цикл регенерации начинается, если в Модели между указанными метками нет ни одного транзакта.
При моделировании систем управления запасами цикл начинается, когда достигается минимальная величина запаса, поэтому для таких моделей необходимо изменить условие проверки начала цикла регенерации.
9.5. Факторный план
При экспериментировании с моделью различают входные и выходные переменные. Входные переменные называются факторами. Выходные переменные называются откликами. Каждый фактор в эксперименте может принимать одно или несколько значений, называемыми уровнями фактора. Множество уровней факторов определяет одно из возможных состояний моделируемой системы и представляет условия проведения одного из возможных экспериментов. Существует определенная связь между уровнями факторов и откликами системы, которая обычно заранее неизвестны. Эту связь можно определить следующим образом:
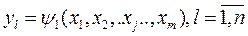
где у1, - l-й отклик, п - число анализируемых откликов, хi - i -йфактор, т- число факторов.
Функция ψ в правой части называется функцией отклика или реакции. Ее геометрический образ - поверхность отклика. Так как функция ψ заранее не известна, то используют другую приближенную функцию:
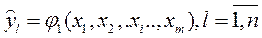
Эти функции φ l находят по данным эксперимента и представляют в виде степенного полинома первого, второго и, реже, третьего порядка. После проведения экспериментов аппроксимирующие полиномы заменяют уравнениями регрессии и методом наименьших квадратов находят статистические оценки их неизвестных коэффициентов.
Факторный эксперимент может быть отсеивающий, когда из всего множества факторов определяются те факторы, которые существенно влияют на отклики модели. Второй вид факторного эксперимента используется для определения экстремальных значений на поверхности отклика. В этом случае серия факторных экспериментов планируется так, чтобы достичь экстремума на поверхности отклика.
Факторный эксперимент представляет собой план, в котором все уровни каждого фактора встречаются в сочетании со всеми уровнями всех других факторов. Различные уровни некоторого фактора могут соответствовать качественным значениям (например, разные дисциплины обслуживания в устройстве) или количественным значениям (например, число устройств обслуживания). Если фактор f (f=1,...,к) имеет Lf уровней, то общее число комбинаций уровней определяется произведением:
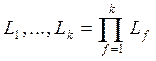 (9.1)
(9.1)
Если число уровней для каждого из факторов одинаково, то общее число комбинаций будет Lk.
Левая часть выражения (9.1) используется для обозначения факторного плана.
Применение факторного плана вместо классической схемы, согласно которой каждый раз изменяется только один фактор, имеет ряд преимуществ.
- Становится более полной картина влияния каждого фактора, поскольку они изучаются в самых различных условиях (вследствие одновременного изменения других факторов).
- Большое число комбинаций факторов, используемых в эксперименте, облегчает предсказание результатов, которые могут быть достигнуты при определенной комбинации условий.
- Если эффекты, вызываемые каждым фактором, статистически независимы, то о каждом факторе можно получить не меньше информации, чем при изменении в экспериментах только одного фактора при фиксации остальных.
- Если (как это часто бывает) различные факторы не являются независимыми, а вызывают эффекты, которые в большей или меньшей степени коррелированны, то в этом случае только факторный эксперимент может дать информацию о характере этих взаимодействий. При наличии нескольких взаимосвязанных существенных факторов обойтись без постановки факторного эксперимента невозможно. Для ряда часто встречающихся специальных задач разработано большое число стандартных факторных планов.
Рассмотрим пример 2-х факторного эксперимента, с двумя факторами на 2-х уровнях и с двумя наблюдениями в каждом опыте, т.е. план 22. Факторы принято обозначать буквами латинского алфавита А, В, С и т.д.
Результаты экспериментов сведем в таблицу 9.1.
Таблица 9.1
| Фактор А | Фактор В | |
| Уровень 1 | Уровень 2 | |
| Уровень 1 | y111 y112 | y121 y122 |
| Уровень 2 | y 211 y212 | y 221 y222 |
В этой таблице yijg обозначает g-e наблюдение (g = 1,2) в ячейке i, j. Количество наблюдений (прогонов модели) g определяется желаемой точностью получения оценок откликов.
В общем случае в 2-х факторном эксперименте число уровней факторов А и В равно соответственно i и J. Обозначим математическое ожидание E{yijg)=ηij, тогда в планировании эксперимента предполагается верной следующая модель:
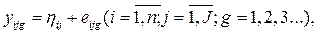
где eijg - ошибка опыта. Предполагается, что все эти ошибки являются независимыми нормально распределенными случайными величинами с математическим ожиданием 0 и дисперсией σ2. При имитации ошибки опытов можно сделать независимыми, применяя различные последовательности случайных чисел при прогонах модели.
9.6. Дисперсионный анализ ANOVA в планировании экспериментов
Для определения, является фактор значимым или нет, используется дисперсионный анализ ANOVA (analysis of variance), который применим только к количественным факторам. С помощью него определяются количественные отклонения наблюдений от среднего значения. Если какой-либо фактор не оказывает влияние на отклик, то он является незначимым. С другой стороны, если фактор влияет на отклик, то его (фактора) количественное значение сравнивают с оценкой изменчивости наблюдения, то есть со стандартной ошибкой. Это делается для исключения эффектов, которые являются не более чем случайной флуктуацией.
Неявно в ANOVA используется аддитивная математическая модель, которая определяет компоненты изменения в наблюдениях. Ее называют статистической моделью. Самая простая статистическая модель:
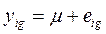
т.е. каждое i -е наблюдение представляет собой общее среднее по всем опытам μ, и случайную ошибку eig. В этой модели общее среднее не изменяется от опыта к опыту, в отличие от ошибки.
Статистическая модель для анализа данных экспериментов с одним фактором А имеет следующий вид:
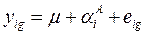
где 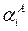 - главный эффект фактора А на уровне i. Все наблюдения на данном уровне обработки анализируются, используя то же самое значение для аА. Так как в этом эксперименте имеется только один фактор, число комбинаций обработки определяется числом уровней I этого фактора.
- главный эффект фактора А на уровне i. Все наблюдения на данном уровне обработки анализируются, используя то же самое значение для аА. Так как в этом эксперименте имеется только один фактор, число комбинаций обработки определяется числом уровней I этого фактора.
Для двух факторов общая модель факторного плана такова:
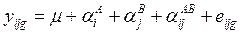 (9.2)
(9.2)
где 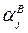 - главный эффект фактора В на уровне j;
- главный эффект фактора В на уровне j; 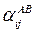 - взаимодействие фактора А на уровне i и фактора В на уровне j. Сумма эффектов двух факторов не равна сумме их отдельных эффектов из-за взаимодействия между ними. Главный эффект фактора определяет долю участия фактора в значении функции отклика во время перехода его с нижнего уровня к верхнему.
- взаимодействие фактора А на уровне i и фактора В на уровне j. Сумма эффектов двух факторов не равна сумме их отдельных эффектов из-за взаимодействия между ними. Главный эффект фактора определяет долю участия фактора в значении функции отклика во время перехода его с нижнего уровня к верхнему.
Дисперсионный анализ, основанный на статистической модели (9.2), заканчивается построением таблицы ANOVA, в которой анализируется влияние факторов А, В, взаимодействие между факторами АВ и случайные помехи наблюдения.
С помощью ANOVA проверяется гипотеза об отсутствии влияния фактора. Если справедлива гипотеза об отсутствии влияния фактора, то считается, что все наблюдения получены из одной генеральной совокупности. Для проверки гипотезы используется F- распределение Фишера. Критерий Фишера определяет отношение двух выборочных дисперсий. Если фактор существенно влияет на отклик, то значения F-распределения принимает большие значения и F- статистика становится значимой. Таким образом, большие значения F приводят к отбрасыванию гипотезы об отсутствии влияния фактора, т.е. фактор является значимым.