2015-08-21
2015-08-21 872
872Алгоритм CGF, реализующий метод Флетчера – Ривса [12, 18], использует следующее выражение для вычисления константы метода:
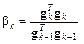 . (3.25)
. (3.25)
В данном случае константа равна отношению квадрата нормы градиента на текущей
к квадрату нормы градиента на предыдущей итерации.
Вновь обратимся к сети, показанной на рис. 3.8, но будем использовать функцию
обучения traincgf:
net = newff([–1 2; 0 5],[3,1],{'tansig','purelin'},'traincgf');
Функция traincgf характеризуется следующими параметрами, заданными по умолчанию:
net.trainParam
ans =
epochs: 100
show: 25
goal: 0
time: Inf
min_grad: 1.0000e–006
max_fail: 5
searchFcn: 'srchcha'
scale_tol: 20
alpha: 0.0010
beta: 0.1000
delta: 0.0100
gama: 0.1000
low_lim: 0.1000
up_lim: 0.5000
maxstep: 100
minstep: 1.0000e–006
bmax: 26
Здесь epochs – максимальное количество циклов обучения; show – интервал вывода информации, измеренный в циклах; goal – предельное значение критерия обучения; time – предельное время обучения; min_grad – минимальное значение градиента; max_fail – максимально допустимый уровень превышения ошибки контрольного подмножества по сравнению с обучающим; searchFcn – имя функции одномерного поиска; scale_tol – коэффициент для вычисления шага tol процедуры одномерного поиска tol = delta/scale_tol; alpha – коэффициент, определяющий порог уменьшения критерия качества; beta – коэффициент, определяющий выбор шага; delta – начальный шаг разбиения интервала; gama – параметр, регулирующий изменение критерия качества; low_lim – нижняя граница изменения шага; up_lim – верхняя граница изменения шага; maxstep – максимальное значение шага; minstep – минимальное значение шага; bmax – максимальное значение шага для процедуры srchhyb.
Установим следующие значения параметров:
net.trainParam.epochs = 300;
net.trainParam.show = 5;
net.trainParam.goal = 1e–5;
p = [–1 –1 2 2;0 5 0 5];
t = [–1 –1 1 1];
net = train(net,p,t); % Рис.3.12
На рис. 3.12 приведен график изменения ошибки обучения в зависимости от числа выполненных циклов обучения.
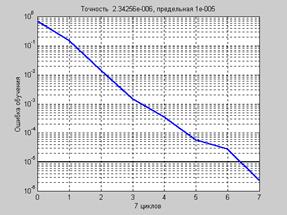 Рис. 3.12
Рис. 3.12
a = sim(net,p)
a = –1.0015 –0.9978 0.9999 0.9986
Алгоритм Флетчера – Ривса CGF работает намного быстрее, чем градиентный алгоритм CGM с выбором параметра скорости настройки, а иногда и быстрее, чем алгоритм Rprop, как в рассматриваемом случае; хотя на практике это зависит от конкретной задачи. Алгоритмы метода сопряженных градиентов требуют не намного больше памяти, чем градиентные алгоритмы, поэтому их можно рекомендовать для обучения нейронных
сетей с большим количеством настраиваемых параметров.
Демонстрационная программа nnd12cg иллюстрирует работу алгоритмов минимизации на основе метода сопряженных градиентов.