 2015-08-21
2015-08-21 2895
2895Альтернативой методу сопряженных градиентов для ускоренного обучения нейронных сетей служит метод Ньютона. Основной шаг этого метода определяется соотношением
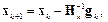 (3.28)
(3.28)
где 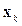 – вектор настраиваемых параметров;
– вектор настраиваемых параметров; 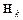 – матрица Гессе вторых частных производных функционала ошибки по настраиваемым параметрам;
– матрица Гессе вторых частных производных функционала ошибки по настраиваемым параметрам; 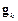 – вектор градиента функционала ошибки. Процедуры минимизации на основе метода Ньютона, как правило, сходятся быстрее, чем те же процедуры на основе метода сопряженных градиентов.
– вектор градиента функционала ошибки. Процедуры минимизации на основе метода Ньютона, как правило, сходятся быстрее, чем те же процедуры на основе метода сопряженных градиентов.
Однако вычисление матрицы Гессе – это весьма сложная и дорогостоящая в вычислительном отношении процедура. Поэтому разработан класс алгоритмов, которые основаны на методе Ньютона, но не требуют вычисления вторых производных. Это класс квазиньютоновых алгоритмов, которые используют на каждой итерации некоторую приближенную оценку матрицы Гессе.
Одним из наиболее эффективных алгоритмов такого типа является алгоритм BFGS, предложенный Бройденом, Флетчером, Гольдфарбом и Шанно (Broyden, Fletcher, Goldfarb and Shanno) [9]. Этот алгоритм реализован в виде М-функции trainbfg.
Вновь обратимся к сети, показанной на рис. 3.7, но будем использовать функцию
обучения trainbfg:
net = newff([–1 2; 0 5],[3,1],{'tansig','purelin'},'trainbfg');
Параметры функции trainbfg практически совпадают с параметрами функции traincgf, за исключением используемой программы одномерного поиска, которая в данном случае заменена М-функцией srchbac.
Установим параметры обучающей процедуры по аналогии с предшествующими примерами:
net.trainParam.epochs = 300;
net.trainParam.show = 5;
net.trainParam.goal = 1e–5;
p = [–1 –1 2 2;0 5 0 5];
t = [–1 –1 1 1];
net = train(net,p,t); % Рис.3.16
На рис. 3.16 приведен график изменения ошибки в зависимости от числа выполненных циклов обучения.
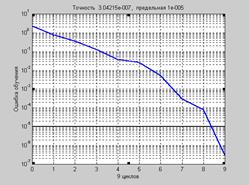 Рис. 3.16
Рис. 3.16
a = sim(net,p)
a = –1.0011 –1.0001 0.9999 1.0003
Алгоритм BFGS требует большего количества вычислений на каждой итерации
и большего объема памяти, чем алгоритмы метода сопряженных градиентов, хотя, как правило, он сходится на меньшем числе итераций. Требуется на каждой итерации хранить оценку матрицы Гессе, размер которой определяется числом настраиваемых параметров сети. Поэтому для обучения нейронных сетей больших размеров лучше использовать алгоритм Rprop или какой-либо другой алгоритм метода сопряженных градиентов. Однако для нейронных сетей небольших размеров алгоритм BFGS может оказаться эффективным.

