 2015-08-21
2015-08-21 1249
1249Алгоритм LM Левенберга – Марквардта [17] реализует следующую стратегию для оценки матрицы Гессе. В предположении, что функционал определяется как сумма квадратов ошибок, что характерно при обучении нейронных сетей с прямой передачей, гессиан может быть приближенно вычислен как
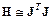 , (3.29)
, (3.29)
а градиент рассчитан по формуле
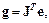 (3.30)
(3.30)
где 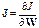 – матрица Якоби производных функционала ошибки по настраиваемым параметрам; e – вектор ошибок сети. Матрица Якоби может быть вычислена на основе стандартного метода обратного распространения ошибки, что существенно проще вычисления матрицы Гессе.
– матрица Якоби производных функционала ошибки по настраиваемым параметрам; e – вектор ошибок сети. Матрица Якоби может быть вычислена на основе стандартного метода обратного распространения ошибки, что существенно проще вычисления матрицы Гессе.
Алгоритм LM использует аппроксимацию гессиана следующего вида:
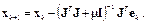 (3.31)
(3.31)
Когда коэффициент m равен 0, мы получаем метод Ньютона с приближением гессиана в форме (3.29); когда значение m велико, получаем метод градиентного спуска с маленьким шагом. Поскольку метод Ньютона имеет большую точность и скорость сходимости вблизи минимума, задача состоит в том, чтобы в процессе минимизации как можно быстрее перейти к методу Ньютона. С этой целью параметр m уменьшают после каждой успешной итерации и увеличивают только тогда, когда пробный шаг показывает, что функционал ошибки возрастает. Такая стратегия обеспечивает уменьшение ошибки после каждой итерации алгоритма.
Вновь обратимся к сети, показанной на рис. 3.8, но будем использовать функцию обучения trainlm:
net = newff([–1 2; 0 5],[3,1],{'tansig','purelin'},'trainlm');
Функция trainlm характеризуется следующими параметрами, заданными по умолчанию:
net.trainParam
ans =
epochs: 100
goal: 0
max_fail: 5
mem_reduc: 1
min_grad: 1.0000e–010
mu: 0.0010
mu_dec: 0.1000
mu_inc: 10
mu_max: 1.0000e+010
show: 25
time: Inf
В этом перечне появилось несколько новых параметров. Параметр mu – начальное значение для коэффициента m. Это значение умножается либо на коэффициент mu_dec, когда функционал ошибки уменьшается, либо на коэффициент mu_inc, когда функционал ошибки возрастает. Если mu превысит значение mu_max, алгоритм останавливается. Параметр mem_reduc позволяет экономить объем используемой памяти, что обсуждается ниже.
Установим параметры обучающей процедуры по аналогии с предшествующими
примерами:
net.trainParam.epochs = 300;
net.trainParam.show = 5;
net.trainParam.goal = 1e–5;
p = [–1 –1 2 2;0 5 0 5];
t = [–1 –1 1 1];
net = train(net,p,t); % Рис.3.18
На рис. 3.18 приведен график изменения ошибки обучения в зависимости от числа выполненных циклов обучения.
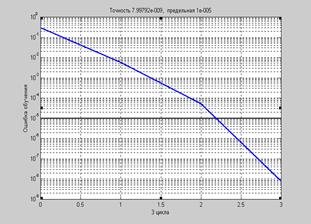 Рис. 3.18
Рис. 3.18
a = sim(net,p)
a = –1.0000 –0.9998 1.0000 0.9999
Как видим, здесь потребовалось всего 3 цикла обучения. Этот алгоритм, видимо,
является самым быстродействующим и пригоден для обучения больших нейронных сетей с несколькими сотнями настраиваемых параметров. Этот алгоритм имеет очень эффективную реализацию в системе MATLAB, являющейся интерпретатором векторной машины, где операция скалярного произведения реализуется с высокой точностью и быстродействием на математическом сопроцессоре компьютера. Поэтому достоинства алгоритма Левенберга – Марквардта становятся еще более ощутимыми при работе в среде системы MATLAB.
Демонстрационный пример nnd12m иллюстрирует применение алгоритма LM.
Экономия памяти. Главный недостаток алгоритма LM состоит в том, что он требует
памяти для хранения матриц больших размеров. Например, размер матрицы Якоби составляет Q ´ n, где Q – число обучающих наборов и n – число параметров сети. Это означает, что при оценке гессиана согласно соотношению (3.28) потребуются значительные ресурсы для ее хранения и вычисления. Как это часто делается при работе с матрицами, выполним ее декомпозицию, т. е. представим ее в виде разбиения на несколько подматриц. Допустим, что выделены 2 подматрицы; тогда соотношение (3.28) может быть записано в виде:
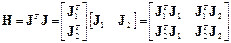 . (3.32)
. (3.32)
В этом случае уже не требуется хранить полную матрицу Якоби, а оценка гессиана может быть вычислена с использованием подматриц меньших размеров. Причем в процессе формирования матрицы Гессе использованные подматрицы могут быть удалены
из оперативной памяти.
При применении М-функции trainlm с помощью параметра mem_reduc можно указывать, на какое число подматриц разбивается исходная матрица. Если параметр mem_reduc равен 1, то используется полная матрица Якоби; если mem_reduc = 2, то матрица Якоби разбивается
по строкам на 2 части и сначала обрабатывается одна половина, а затем вторая. Это экономит половину объема памяти, требуемой для вычисления полного якобиана. Что же касается быстродействия, то оно будет частично потеряно. И если вам доступна достаточная оперативная память, то лучше устанавливать параметр mem_reduc равным 1. Это особо касается системы MATLAB, которая позволяет извлечь все преимущества при использовании математического сопроцессора. Если же все-таки имеющаяся память оказалась исчерпанной, то следует назначить параметр mem_reduc равным 2 и выполнить расчеты заново. Если и при этом памяти
не будет достаточно, следует еще увеличить значение этого параметра.

