 2015-09-06
2015-09-06 1134
1134Необходимо отметить, что на этапе проектирования информационных систем нейросетевому моделированию любого экономического процесса или явления должен предшествовать априорный анализ объекта исследования. Если этот этап будет исключен, то, как и при статистическом моделировании, возможно получение неадекватных действительности результатов на этапе эксплуатации модели при функционировании информационной системы. Априорный анализ при нейросетевом моделировании частично отличается от технологии статистического анализа и состоит из следующих этапов: постановка задачи исследования; обобщение профессиональных знаний об объекте исследования на основании опыта, интуиции, изучения литературных источников, консультаций со специалистами и т.п.; формализация полученной априорной информации об объекте исследования; уточнение и конкретизация постановки задачи, сбор исходных данных, формирование обучающей выборки. Этапы априорного анализа статиcтических данных подробно рассмотрены в литературе [17,31,100,102].
На этапе предобработки важную роль играет компонент предобработчик данных. Он занимает место между обучающей выборкой и нейросетью. В него входят блоки собственно предобработки данных, а также погружения (формирования обучающей выборки) (рис. 4.13). Из литературных источников следует, что разработка эффективных предобработчиков для нейрокомпьютеров является новой, почти совсем не исследованной областью [110].Поэтому данный раздел при использовании нейросетевого подхода в информационных системах подлежит существенной доработке. К этапам предобработки данных при нейросетевом моделировании в информационных системах будем относить: исключение аномальных наблюдений, проверку однородности данных, заполнение пропусков в данных, фильтрацию, нормировку данных, погружение данных (рис. 4.13). На этапе погружения данных происходит формирование
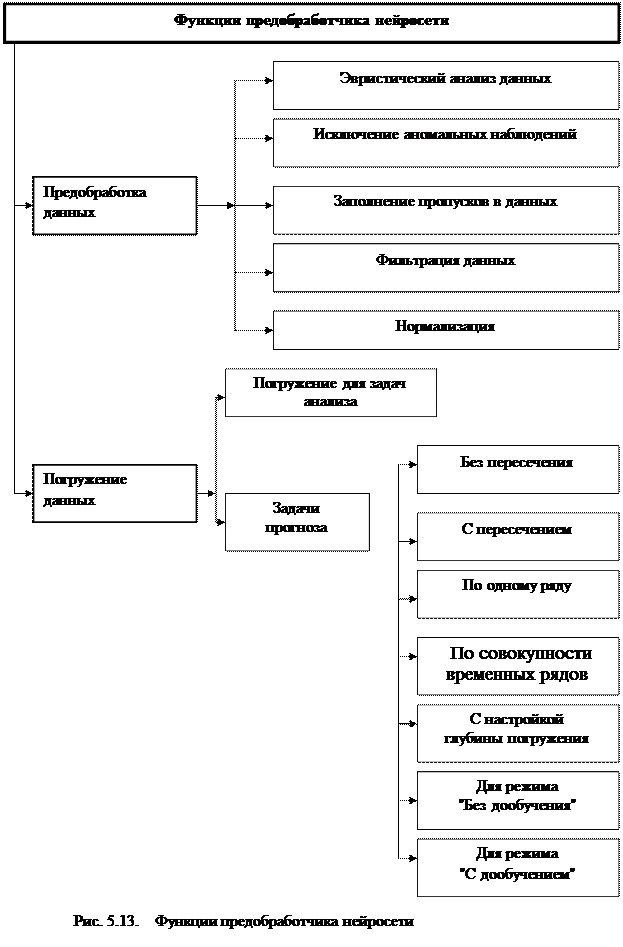
обучающей выборки в базе данных в соответствие с определенными правилами, заданными процедурой решения конкретной прикладной задачи. В частности, различаются функции погружения при решении задач анализа и прогноза. При решении задач прогнозирования выделяются варианты погружения данных в режимах "без пересечения", "с пересечением", "по одному ряду", "по совокупности временных рядов"(см. гл.3).
Предварительная очистка и первичная статистическая обработка исходных данных при нейросетевом моделировании включает также этап исключения аномальных наблюдений. Для этих целей можно применить алгоритмы содержащиеся в работах [17,98], а также алгоритмы «ремонта» данных [184]
Следующим этапом предобработки данных следует считать проверку однородности данных [17]. Исследования показывают, что часто весь исходный статистический материал, как правило, разбивается на ряд групп, объединенных каким – либо общим признаком. Применение нейросетевой аппроксимации по таким данным часто бывает затруднено, сеть учится с перебоями, так как алгоритмы оптимизации работают не устойчиво. В связи с этим встает вопрос о сравнении различных групп исходных данных для определения их однородности и установления принадлежности различных выборок единой генеральной совокупности.
Часто при эксплуатации реальных информационных систем неизвестна связь обучающей выборки с генеральной совокупностью. Неизвестна связь выборки с теми или иными законами распределения, корреляционными и регрессионными зависимостями. Поэтому, для проверки однородности выборки необходимо, прежде всего, обратиться к известной из литературы по распознаванию образов гипотезе компактности [62]. Она утверждает, что реализации одного и того же образа обычно отображаются в признаковом пространстве в геометрически близкие точки, образуя «компактные сгустки». При исследовании компактности (в том числе определения однородности выборки) можно в качестве предобработки использовать различные меры компактности: среднее расстояние от центра тяжести до всех точек образа, средней длиной ребра полного графа или ребра кратчайшего незамкнутого пути, соединяющего точки одного образа, максимальным расстоянием между двумя точками образа и т.д.[62]. Кроме того, эффективными являются следующие меры близости объектов – квадрат евклидова расстояния между векторами значений и признаков, квадрат расстояния Махаланобиса, квадрат коэффициента корреляции [17]. Для проверки однородности данных можно применять методы классификации данных «без учителя» [41]. Наиболее эффективными являются методы динамических ядер и нейросетевой метод адаптивной кластеризации данных, основанный на картах Кохонена[41,44,207,233,234].
Важным этапом предобработки является также процедура заполнения пропусков в данных. Распространенными приемами анализа данных с пропусками являются исключение некомплектных наблюдений (содержащих пропуски хотя бы в одной из переменных) и традиционные методы заполнения пропусков средневыборочными по присутствующим значениям с помощью регрессии и главных компонент [102]. Эти методы в общем случае имеют малую эффективность, ведут, как правило, к несмещенности и несостоятельности, к нарушению уровней значимости критериев и другим искажениям статистических выводов, не обладают устойчивостью к распределению пропусков. Наиболее популярным в настоящее время за рубежом является EM –алгортм [98]. В нашей стране известны работы в области заполнения пропусков в данных, в том числе, наиболее эффективными являются алгоритмы ZET, адаптивный генетический алгоритм LGAP [60].
Для проводимых исследований за основу взята работа[184]. Авторами этой работы создан программный комплекс «Линейный и нелинейный факторный анализ». Он предназначен для восстановления пропущенных (ремонт известных) данных в таблицах путем моделирования исходных данных многообразиями малой размерности и последующего замещения пропущенных данных значениями из модели. Метод интерпретируется как построение конвейера нейронов для обработки данных с пробелами. Другая возможная интерпретация - итерационный метод главных компонент и нелинейный факторный анализ для данных с пробелами.
Следующим элементом предобработчика является оценка выборки и, при необходимости, фильтрация данных. Данные методы обсуждались в третьей главе работы. В зависимости от характера обучающей выборки возможно использование различных методов фильтрации данных. Для выбора методов необходимо произвести предварительную оценку данных. Для этого можно использовать оценку дисперсии, эвристические методы. В зависимости от результатов анализа при помощи экспертной системы (продукционной, основанной на теории прецедентов и др.) определяется тот или иной метод фильтрации данных: простые скользящие средние, взвешенные скользящие средние, экспоненциальное скользящее среднее, фурье, вейвлет –анализ и т.д [57,102,222].
Заключительным этапом предобработки является нормировка данных. При этом осуществляется преобразование входных сигналов таким образом, чтобы обеспечить эффективную работу нейронной сети. Для количественных признаков стандартными процедурами предобработки являются нормировка и центрирование, которые обеспечивают универсальность нейронной сети при работе с произвольными данными и позволяют сохранять параметры сети в оптимальном для функционирования диапазоне. Существует несколько стандартных методов нормировки [41], использующих оценки математического ожидания и дисперсии, основанные на текущей выборке, но оценки статистических параметров могут меняться от выборки к выборке, что создаст трудности при обработке новых данных, которые могут менять статистические параметры выборки. Более удобной в нашем случае является формула [41, 110]:
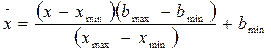 , , | (4.3) |
где [ bmin,bmax ] - диапазон приемлемых значений входных переменных, в нашем случае [-1,1]; [ xmin,xmax ] – интервал допустимых значений признака x, полученный на этапе структурирования, 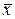 –преобразованный сигнал, который будет подан на вход сети. При использовании (4.3) параметры нормировки остаются неизменными при обработке различных выборок.
–преобразованный сигнал, который будет подан на вход сети. При использовании (4.3) параметры нормировки остаются неизменными при обработке различных выборок.
Значения переменных, измеренных в номинальной шкале, обычно представлены в обучающей выборке в виде натуральных чисел 1.. S, где S – число возможных состояний. Преобразование номинальных переменных по формуле (4.3) некорректно, так как явным образом вводит расстояние между отдельными значениями переменной.
Применяется следующий метод предобработки. Пусть Р Î{1..S} –номинальная переменная, S – число возможных состояний. C=(C1 .. CS), Ci Î {-1,1} – кортеж бинарных переменных. Тогда каждой Рk ставится в соответствие Ck. При этом
| Pk = i Þ Cik = 1, Cjk = -1, "j ¹ i; i,j = 1 .. S, | (4.4) |
где i, j – номера состояний Рk. В итоге, каждой номинальной переменной соответствует несколько бинарных полей в обучающей выборке.
Преобразования (4.3), (4.4) проводятся как для входных, так и для выходных параметров обучающей выборки.
В [41, 110] предлагается включить в предобработку данных вычисление оценки константы Липшица для выборки для определения «минимального порога разрешения», которым должна обладать нейросеть, чтобы иметь возможность разделить два близких сигнала:
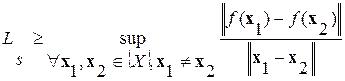 , , | (4.5) |
где Ls – выборочная константа Липшица; x 1, x 2 – примеры из выборки X; 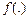 – значение целевой переменной; ||×|| – евклидова норма.
– значение целевой переменной; ||×|| – евклидова норма.
Если x 1 = x 2 при f (x 1) ¹ f (x 2), то примеры x 1, x 2 являются конфликтными и оценка обучения сети на данной выборке будет не меньше, чем
e = 0.5 × (| f (x 1) - f (x 2)|)2.
Конфликтные примеры свидетельствуют либо об ошибках измерения различной природы, либо о недостаточности набора параметров для описания объекта. В первом случае один из примеров исключают из рассмотрения, или, при малом значении e, продолжают обучение, используя оценку МНК «с допуском» [110]. Во втором случае необходим дополнительный анализ предметной области для выявления новых параметров описания, позволяющих разделить конфликтные примеры.
Если в значениях выходной переменной присутствует аддитивный шум формула (4.5) может дать завышенную оценку константы Липшица аппроксимируемой функции. В этом случае предлагается использовать оценку:
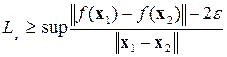 , , | (4.6) |
где || f (x 1) – f (x 2)||>2 e, т.е. требования к нейросетевой модели станут менее жесткими, что позволит построить более гладкую нейросетевую зависимость. Заметим, что использование того или иного вида выборочной константы Липшица зависит от вида функционала оценки работы нейросети. Классическому МНК соответствует (4.5), при оценке типа МНК с допуском предлагается использовать (4.6).
Выборка может содержать как количественные, так и номинальные переменные. В случае векторов со смешанным типом компонент расстояние определяется в соответствии с функцией HEOM (Heterogeneous Euclidean –Overlap Metric function) [279]: для количественных параметров, после их нормирования в интервал [-1,1], за расстояние принимается модуль разности значений. Для дискретных переменных расстояние между двумя значениями P 1 и P 2 переменной Р определяется по правилу:
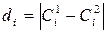 , , | (4.7) |
где С1, С 2 получены по формуле (4.4). Тогда расстояние между векторами вычисляется по формуле
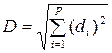 , , | (4.8) |
где i – номер компоненты вектора.

