 2015-09-06
2015-09-06 3559
3559Многомерные базы данных (Multi-value Database)
Многомерные базы данных — технология, которая длительное время воспринималась как новинка, — сегодня является решением, которое предлагает не только высокую производительность и простоту использования, но и обеспечивает возможности, необходимые для разработки, расширения и быстрого развертывания бизнес-приложений при сокращении ИТ-затрат. Системы на основе многомерных баз данных идеально подходят для потребностей как для рынков среднего и малого бизнеса (SMB), так и крупных предприятий.
Многомерные базы данных отличаются от реляционных прежде всего трехмерностью — поддержкой неограниченного числа значений в поле, и находят свое применение там, где необходима эффективная и простая работа с большими массивами символьной информации. В многомерных СУБД данные организованы в виде упорядоченных многомерных массивов, удовлетворяющих требованиям защиты от несанкционированного доступа в организации. Они обеспечивают более быструю реакцию на запросы данных за счет того, что обращения поступают к относительно небольшим блокам данных, необходимых для конкретной группы пользователей. Для достижения сравнимой производительности реляционные системы требуют тщательной проработки схемы базы данных, определения способов индексации и специальной настройки. Ограничения SQL остаются реальностью, что не позволяет реализовать в реляционных СУБД многие встроенные функции, легко обеспечиваемые в системах основанных на многомерном представлении данных.
Основные преимущества многомерных СУБД
· Общая простота системы, что позволяет осуществлять быстрое встраивание технологий многомерных СУБД в приложения. Системы на основе многомерных баз данных требуют меньше специальных навыков по разработке и администрированию;
· Относительно низкая общая стоимость владения, а также быстрый возврат инвестиций;
· В случае использования многомерных СУБД поиск и выборка данных осуществляется значительно быстрее, чем при многомерном концептуальном взгляде на реляционную базу данных, так как многомерная база данных обеспечивает оптимизированный доступ к запрашиваемым ячейкам;
· Многомерные СУБД легко справляются с задачами включения в информационную модель разнообразных встроенных функций, тогда как объективно существующие ограничения языка SQL делают выполнение этих задач на основе реляционных СУБД достаточно сложным, а иногда и невозможным.
Наиболее коммерчески успешными из известных программных продуктов, основанных на многомерных технологиях, являются СУБД UniVerse компании Rocket Software и СУБД jBASEодноименной компании jBASE International.
Специалисты компании ГазИнтех предлагают надежные и недорогие решения, которые позволяют перейти на использование современных открытых технологий. В том числе нами разработаны уникальные решения, позволяющие использовать преимущества стразу нескольких программных продуктов многомерных СУБД. Мы оказываем услуги по настройке, системной интеграции, администрированию и поддержке, а также разработке приложений различного масштаба на платформах многомерных СУБД UniVerse и jBASE.
9. Общая характеристика и виды документальных информационных систем
Напомним, что в фактографических информационных системах единичным элементом данных, имеющим отдельное смысловое значение, является запись, образуемая конечной совокупностью полей-атрибутов. Иначе говоря, информация о предметной области представлена набором одного или нескольких типов структурированных на отдельные поля записей.
В отличие от фактографических информационных систем, единичным элементом данных в документальных информационных системах является неструктурированный на более мелкие элементы документ. В качестве неструктурированных документов в подавляющем большинстве случаев выступают, прежде всего, текстовые документы, представленные в виде текстовых файлов, хотя к классу неструктурированных документированных данных могут также относиться звуковые и графические файлы.
Основной задачей документальных информационных систем является накопление и предоставление пользователю документов, содержание, тематика, реквизиты и т. п. которых адекватны его информационным потребностям. Поэтому можно дать следующее определение документальной информационной системы — единое хранилище документов с инструментарием поиска и отбора необходимых документов. Поисковый характер документальных информационных систем исторически определил еще одно их название — информационно-поисковые системы (ИПС), хотя этот термин не совсем полно отражает специфику документальных ИС.* Соответствие найденных документов информационным потребностям пользователя называется пертинентностью. В силу теоретических и практических сложностей с формализацией смыслового содержания документов пертинентность относится скорее к качественным понятиям, хотя, как будет рассмотрено ниже, может выражаться определенными количественными показателями.
* Поиск информации (данных) осуществляется и в фактографических ИС. Таким образом термин ИПС определяет функциональное назначение ИС, но не отражает специфики представления и обработки данных. Специфика документальных ИПС заключается в том, что они удовлетворяют информационные потребности пользователя, предоставляя ему документы, в которых содержится интересующая пользователя информация.
В зависимости от особенностей реализации хранилища документов и механизмов поиска документальные ИПС можно разделить на две группы:
• системы на основе индексирования;
• семантически-навигационные системы.
В семантически-навигационных системах документы, помещаемые в хранилище (в базу) документов, оснащаются специальными навигационными конструкциями, соответствующими смысловым связям (отсылкам) между различными документами или отдельными фрагментами одного документа. Такие конструкции реализуют некоторую семантическую* (смысловую) сеть в базе документов. Способ и механизм выражения информационных потребностей в подобных системах заключаются в явной навигации пользователя по смысловым отсылкам между документами. В настоящее время такой подход реализуется в гипертекстовых ИПС.
* Семантика (от греч. «semantikos»—обозначающий)—смысловая сторона языка, отдельных слов и частей слова, а также— раздел языкознания, изучающий значения слов.
В системах на основе индексирования исходные документы помещаются в базу без какого-либо дополнительного преобразования,* но при этом смысловое содержание каждого документа отображается в некоторое поисковое пространство. Процесс отображения документа в поисковое пространство называется индексированием и заключается в присвоении каждому документу некоторого индекса-координаты в поисковом пространстве. Формализованное представление (описание) индекса документа называется поисковым образом документа (ПОД). Пользователь выражает свои информационные потребности средствами и языком поискового пространства, формируя поисковый образ запроса (ПОЗ) к базе документов. Система на основе определенных критериев и способов ищет документы, поисковые образы которых соответствуют или близки поисковым образам запроса пользователя, и выдает соответствующие документы. Соответствие найденных документов запросу пользователя называется релевантностью.** Схематично общий принцип устройства и функционирования документальных ИПС на основе индексирования иллюстрируется на рис. 6.1.
* За исключением возможного сжатия (архивирования).
** На практике термин релевантность часто отождествляют с термином пертинентность, хотя в строгом отношении они различны.
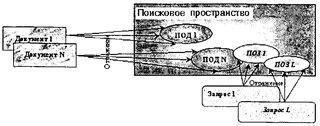
Рис. 6.1. Общий принцип устройства и функционирования документальных ИПС на основе индексирования
Особенностью документальных ИПС является также то, что в их функции, как правило, включаются и задачи информационного оповещения пользователей по всем новым поступающим в систему документам, соответствующим заранее определенным информационным потребностям пользователя.* Принцип решения задач информационного оповещения в документальных ИПС на основе индексирования аналогичен принципу решения задач поиска документов по запросам и основан на отображении в поисковое пространство информационных потребностей пользователя в виде так называемых поисковых профилей пользователей (ППП). Информационно-поисковая система по мере поступления и индексирования новых документов сравнивает их образы с поисковыми профилями пользователей и принимает решение о соответствующем оповещении. Принцип решения задач информационного оповещения схематично иллюстрируется на рис. 6.2.
* Задачи информационного оповещения основаны на идеологии т.н. избирательного распространения информации (ИРИ), наработанной в библиотечном деле.
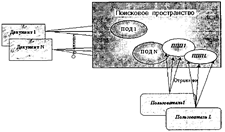
Рис. 6.2. Принцип решения задач информационного оповещения в документальных ИПС на основе индексирования
Поисковое пространство, отображающее поисковые образы документов и реализующее механизмы информационного поиска документов так же, как и в СУБД фактографических систем, строится на основе языков документальных баз данных, называемых информационно-поисковыми языками (ИПЯ). Информационно-поисковый язык представляет собой некоторую формализованную семантическую систему, предназначенную для выражения содержания документа и запросов по поиску необходимых документов. По аналогии с языками баз данных фактографических систем ИПЯ можно разделить на структурную и манипуляционную составляющие.
Структурная составляющая ИПЯ (поискового пространства) документальных ИПС на основе индексирования реализуется индексными указателями в форме информационно-поисковых каталогов, тезаурусов и генеральных указателей.

