2015-09-06
2015-09-06 2103
2103Множення матриці на вектор і матриці на матрицю є базовими макроопераціями для багатьох задач лінійної алгебри, наприклад ітераційних методів розв’язання систем лінійних рівнянь і т.п. Тому приведені алгоритми тут можна розглядати як фрагменти в алгоритмах цих методів. Розглянемо три алгоритми множення матриці на матрицю. Розмаїтість варіантів алгоритмів виникає із-за розмаїтості обчислювальних систем і розмаїтості розмірів задач. Розглядаються і різні варіанти завантаження даних у систему: завантаження даних через один комп'ютер; і завантаження даних безпосередньо кожним комп'ютером з дискової пам'яті. Якщо завантаження даних здійснюється через один комп'ютер, то дані зчитуються цим комп'ютером з дискової пам'яті, розрізаються на частини, які розсилаються іншим комп'ютерам. Але дані можуть бути підготовлені і заздалегідь, тобто заздалегідь розрізані вроздріб і кожна частина записана на диск у виді окремого файлу зі своїм ім'ям; потім кожен комп'ютер безпосередньо зчитує з диска, призначений для нього файл.
Алгоритм 1- Перемноження матриці на матрицю на кільцевій структурі
Задано дві вихідні матриці A і B. Обчислюється добуток C = А х B, де А - матриця n1 х n2, і B - матриця n2 х n3. Матриця результатів C має розмір n1 х n3. Вихідні матриці попередньо розрізані на смуги, смуги записані на дискову пам'ять окремими файлами зі своїми іменами і доступні всім комп'ютерам. Матриця результатів повертається в нульовий процес.
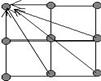
Реалізація алгоритму виконується на кільці з p1 комп'ютерів. Матриці розрізані як показане на рис. 7.1: матриця А розрізана на p1 горизонтальних смуг, матриця B розрізана на p1 вертикальних смуг, і матриця результату C розрізана на p1 смуги. Тут передбачається, що в пам'ять кожного комп'ютера завантажується і може знаходитися тільки одна смуга матриці А і одна смуга матриці B.

Рис. 7.1 Розрізування даних для паралельного алгоритму добутку двох матриць при обчисленні на кільці комп'ютерів. Виділені смуги розташовані в одному комп'ютері.
Оскільки за умовою в комп'ютерах знаходиться по одній смузі матриць, то смуги матриці B (або смуги матриці A) необхідно "прокрутити" по кільцю комп'ютерів повз смуги матриці A (матриці B). Кожний зсув смуг уздовж кільця і відповідна операція множення наведена на рис.7.2 у виді окремого кроку. На кожному з таких кроків обчислюється тільки частина смуги. Процес i обчислює на j-м кроці добуток i-й горизонтальної смуги матриці A j-ї вертикальної смуги матриці B, добуток отриманий у підматриці(i,j) матриці C.
Обчислення відбувається в такій послідовності.
1. Кожен комп'ютер зчитує з дискової пам’яті відповідну йому смугу матриці А. Нульова смуга повинна зчитуватися нульовим комп'ютером, перша смуга - першим комп'ютером і т.д., остання смуга - зчитується останнім комп'ютером. На рис. 7.2 смуги матриці А і B пронумеровані.
2. Кожен комп'ютер зчитує з дискової пам’яті відповідну йому смугу матриці B. У даному випадку нульова смуга повинна зчитуватися нульовим комп'ютером, перша смуга - першим комп'ютером і т.д., остання смуга - зчитується останнім комп'ютером.
3. Обчислювальний крок 1. Кожен процес обчислює одну підматрицю добутку. Вертикальні смуги матриці B зсуваються уздовж кільця комп'ютерів.
4. Обчислювальний крок 2. Кожен процес обчислює одну підматрицю добутку. Вертикальні смуги матриці B зсуваються уздовж кільця комп'ютерів. І т.д.
5. Обчислювальний крок p1-1. Кожен процес обчислює одну підматрицю добутку. Вертикальні смуги матриці B зсуваються уздовж кільця комп'ютерів.
6. Обчислювальний крок p1. Кожен процес обчислює одну підматрицю добутку. Вертикальні смуги матриці B зсуваються уздовж кільця комп'ютерів.
7. Матриця C збирається в нульовому комп'ютері.

1. scatter A 2. scatter B
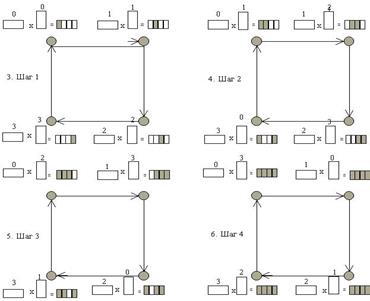
7. Збір результатів у С
Рис. 7.2 Стадії обчислень добутку матриць у кільці комп'ютерів.
Якщо "прокручувати" вертикальні смуги матриці B, то матриця С буде розподілена горизонтальними смугами, а якщо "прокручувати" горизонтальні смуги матриці A, то матриця С буде розподілена вертикальними смугами.
Алгоритм характерний тим, що після кожного кроку обчислень здійснюється обмін даними. Нехай tu, ts, і tp час операцій, відповідно, множення, додавання і пересилання одного числа в сусідній комп'ютер. Тоді сумарний час операцій множень дорівнює:
U = (n1*n2)*(n3*n2)*tu,
сумарний час операцій додавань дорівнює:
S = (n1*n2)*(n3*(n2-1))*ts,
сумарний час операцій пересилань даних по всіх комп'ютерах дорівнює:
P = (n3*n2)*(p1-1)*tp.
Загальний час обчислень визначимо як:
T = (U+S+P)/p1
Відношення часу "обчислень без обмінів" до загального часу обчислень є величина:
K = (U+S)/(U+S+P).
Якщо час передачі даних великий в порівнянні з часом обчислень, або канали передачі повільні, то ефективність алгоритму буде не висока. Тут не враховується час початкового завантаження і вивантаження даних у пам'ять системи. У смугах матриць може бути різна кількість рядків, а різниця в кількості рядків між смугами - 1. При великих матрицях цим можна знехтувати.
При достатніх ресурсах пам'яті в системі краще використовувати алгоритм, у якому мінімізовані обміни між комп'ютерами в процесі обчислень. Це досягається за рахунок дублювання деяких даних у пам'яті комп'ютерів. У наступних двох алгоритмах використовується цей підхід.
Алгоритм 2 - Перемноження матриці на матрицю на2D решітці
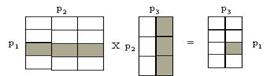
Обчислюється добуток C = А х B, де А - матриця n1 х n2, і B - матриця n2 х n3. Матриця результатів C має розмір n1 х n3. Вихідні матриці спочатку доступні на нульовому процесі, і матриця результатів повертається в нульовий процес.
Паралельне виконання алгоритму здійснюється на двовимірній (2D) решітці комп'ютерів розміром p1 х p2. Матриці розрізані, як показано на рис. 7.3: матриця А розрізана на p1 горизонтальних смуг, матриця B розрізана на p2 вертикальних смуг, і матриця результату C розрізана на p1 х p2 підматриці (або субматриці).
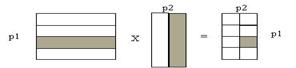
A B C
Рис. 7.3 Розрізування даних для паралельного алгоритму добутку двох матриць при обчисленні на 2D решітці комп'ютерів. Виділені дані розташовані в одному комп'ютері.
Кожен комп'ютер (i,j) обчислює добуток i -й горизонтальної смуги матриці A і j -й вертикальної смуги матриці B, добуток отримується у підматриці (i,j) матриці C.
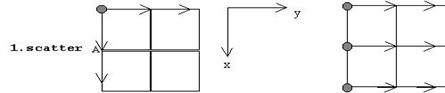
Послідовність стадій обчислення наведена на рис.7.4:
1. Матриця А розподіляється по горизонтальних смугах уздовж координати (x,0).
2. Матриця B розподіляється по вертикальних смугах уздовж координати (0,y).
3. Смуги А поширюються у вимірі y.
4. Смуги B поширюються у вимірі х.
5. Кожен процес обчислює одну підматрицю добутку.
7. Матриця C збирається з (x,y) площини.
Здійснювати пересилання між комп'ютерами під час обчислень не потрібно, тому що всі смуги матриці А перетинаються з усіма смугами матриці B у пам'яті комп'ютерів системи.
Цей алгоритм ефективніший від попереднього, тому що непродуктивний час пересилань даних здійснюється тільки при завантаженні даних у пам'ять комп'ютерів і при їхньому вивантаженні, і обміни даними в процесі обчислень відсутні. Оскільки час обмінів рівний нулеві, а час завантаження і вивантаження тут не враховується, то загальний час обчислень дорівнює:
T = (U+S)/(p1*p2)
А відношення часу "обчислень без обмінів" до загального часу обчислень є величина:
K = (U+S)/(U+S)=1.
2.scatter B координати
3. broadcast підматриць A

4. broadcast 5. обчислення
підматриць B добутків
(підматриць в C )
6. збір
результатів в C
Рис. 7.4 Стадії обчислення добутку матриць у 2D паралельному алгоритмі.
Алгоритм 3 - Перемноження матриці на просторовій сітці комп’ютерів
Для великих матриць, час обчислення добутків може бути зменшений шляхом застосуванням алгоритму, що здійснює обчислення на 3-мірній (просторовій) сітці комп'ютерів.
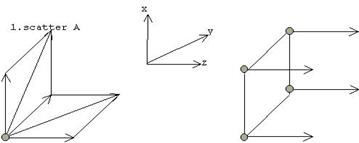
У приведеному нижче алгоритмі відображаються основні дані обсягом n1 х n2 + n2 х n3 + n1 х n3 на об'ємну сітку комп'ютерів розміром p1 х p2 х p3. Матриці розрізані, як показано на рис. 7.5: Матриця А розрізана на p1 х p2 субматриці, матриця B розрізана на p2 х p3 субматриці, і матриця C розрізана на p1 х p3 субматриці. Комп'ютер (i,j,k) обчислює добуток субматриці (i,j) матриці А і субматриці (j,k) матриці B. Субматриця (i,k) матриці C виходить підсумовуванням проміжних результатів, обчислених у комп'ютерах (i,j,k), j = 0,...,p2-1.
Послідовність стадій обчислення наведена на рис. 7.6.
1. Субматриці А розподіляються в (x,y,0) площині.
2. Субматриці B розподіляються в (0,y,z) площині.
3. Субматриці А поширюються у вимірі z.
4. Субматриці B поширюються у вимірі х.
5. Кожен процес обчислює одну субматрицю.
6. Проміжні результати редукується у вимірі y.
7. Матриця C збирається з (x,0,z) площини.
Алгоритм подібний до попереднього, але додатково розрізаються ще смуги матриць, і ці розрізані смуги розподіляються в третьому вимірі y. У даному випадку в кожному комп'ютері будуть перемножуватися тільки частини векторів рядків матриці А і частини стовпців матриці B. В результаті буде тільки часткова сума для кожного елемента результуючої матриці C. Операція підсумовування уздовж координати y цих отриманих часткових сум для результуючих елементів і завершує обчислення матриці C.
Загальний час обчислень у цьому алгоритмі дорівнює:
T = (U+S)/(p1*p2*p3)
А відношення часу "обчислень без обмінів" до загального часу обчислень є величина:
K = (U+S)/(U+S)=1.
A B C
Рис. 7.5 Розрізування даних для паралельного алгоритму добутку двох матриць при обчисленні на просторовій сітці комп'ютерів.
2. scatter B 3. broadcast
підматриць з А
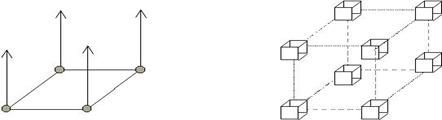
4. broadcast підматриць зУ 5. Обчислення добутків підматриць у С)

6. reduce (підсумовування)добутків 7. gather C (збір результатів)
Рис. 7.6. Стадії обчислень у 3D паралельному алгоритмі добутку матриць.