 2015-10-13
2015-10-13 3293
3293Математической моделью рассмотренного явления может быть функция, отражающая зависимость числа хронических больных Р от концентрации угарного газа С. Вид этой функции неизвестен, ее следует искать методом подбора по экспериментальным данным.
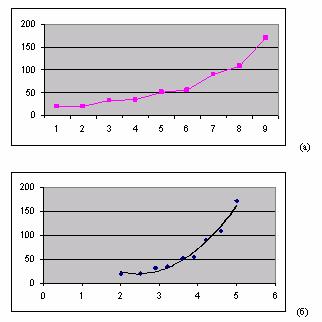
График искомой функции должен проходить близко к точкам диаграммы экспериментальных данных. Строить функцию так, чтобы ее график точно проходил через все данные точки (рисунок а), не имеет смысла, поскольку экспериментальные значения являются приближенными. Отсюда следуют основные требования к искомой функции:
- график этой функции должен проходить вблизи экспериментальных точек так, чтобы отклонения этих точек от графика были минимальны и равномерны (рисунок б);
- среди возможных в этом плане функций желательно отыскать достаточно простую (для использования ее в дальнейших вычислениях).
Такую функцию принято называть в статистике регрессионной моделью.
Построение регрессионной модели происходит в два этапа:
- подбор вида функции;
- вычисление параметров функции.
Первая задача не имеет строгого решения. Здесь могут помочь опыт и интуиция исследователя, а возможен и "слепой" перебор из конечного числа функций и выбор лучшей из них. Например, это может быть линейная функция у = ах + b, квадратичная у = ах2 + bх+ сили более сложная.
Если пробная функция выбрана, то следующим шагом нужно подобрать параметры (а, b, с и пр.) так, чтобы функция располагалась как можно ближе к экспериментальным точкам. Классический способ подбора параметров называется методом наименьших квадратов (МНК). Суть его заключается в следующем: искомая функция должна быть построена так, чтобы сумма квадратов отклонений y-координат всех экспериментальных точек от y-координат графика функции была бы минимальной.
На рисунке изображены две функции, построенные методом наименьших квадратов (с помощью MS Excel) по данным, представленным в приведенной на таблице. Значение R2 позволяет оценить качество приближения: чем оно меньше, тем приближение лучше. Таким образом, можно сделать вывод: квадратичная функция дает лучшее регрессионное приближение, чем линейная. Разумеется, отсюда не следует, что не существует лучшей зависимости. Возможен дальнейший поиск с опорой на качественные соображения и опыт исследователя.
Регрессионные модели, как правило, используются с целью прогноза поведения системы. Определение зависимой величины Y для промежуточных значений аргумента X называется интерполяцией.
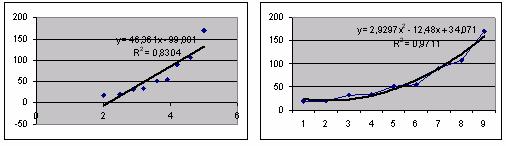
Линейная и квадратичная зависимости, построенные с помощью МНК (линии тренда).
Продолжение линии тренда за границы области данных, приведенных в исходной таблице, называется экстраполяцией. Однако не следует слишком далеко удаляться от области экспериментальных данных, поскольку нет гарантии, что там характер зависимости не изменится.
Моделирование корреляционных связей
Функциональная зависимость между двумя величинами является в некотором смысле самой простой из возможных зависимостей. Если величина у является функцией от величины х, то значение х полностью и однозначно определяет значение у.
Однако бывают (и в реальной жизни гораздо чаще) случаи, когда зависимость, несомненно, есть, но она не имеет однозначного выражения. Простой вопрос: определяет ли рост человека его вес, т.е. можно ли сказать, что при росте 170 см вес обязательно равен некоторому определенному значению? Конечно, нет. На вес человека накладывают отпечаток многие факторы. Но правильно ли на основании этого утверждать, что вес от роста не зависит? Тоже нет. На бытовом уровне ответ таков: вообще говоря, чем больше рост, тем больше вес. "Вообще говоря" здесь означает, что точной (функциональной) зависимости нет, но есть некоторая иная, а именно корреляционная, зависимость.
Корреляция — систематическая и обусловленная связь между двумя рядами данных. Например, ростом и весом; датой и дневной температурой, числом компьютеров в классе и средней оценкой в этом классе на ЕГЭ по информатике и т.п. Можно сказать иначе: корреляция — это связь переменных, при которой одному значению одного признака соответствует несколько значений другого признака, отклоняющегося в ту или иную сторону от своего среднего значения.
Зависимости между величинами, каждая из которых подвергается не контролируемому полностью разбросу, называются корреляционными зависимостями. Раздел математической статистики, который исследует такие зависимости, называется корреляционным анализом. Корреляционный анализ изучает усредненный закон поведения каждой из величин в зависимости от значений другой величины, а также меру такой зависимости.
Формальная постановка задачи корреляционного анализа выглядит так: пусть важной характеристикой некоторой сложной системы является фактор А. На него могут оказывать влияние одновременно многие другие факторы: В, С, D и т.д. Для исследователя могут представлять интерес два типа задач:
- Оказывает ли фактор В какое-либо заметное регулярное влияние на фактор А?
- Какие из факторов — В, С, D и т.д. — оказывают наибольшее влияние на фактор А?
Оценку корреляции величин начинают с высказывания гипотезы о возможном характере зависимости между их значениями. Простейшее допущение — наличие линейной зависимости. В таком случае мерой корреляционной зависимости является величина, которая называется коэффициентом корреляции.
Коэффициент корреляции (обычно обозначаемый греческой буквой р) есть число, заключенное в диапазоне от —1 до +1;
- • если это число по модулю близко к 1, то имеет место сильная корреляция, если к 0, то слабая;
- • близость р к +1 означает, что возрастанию одного набора значений соответствует возрастание другого набора, к —1 означает обратное.
В случае полной положительной корреляции этот коэффициент равен (+1), а при полной отрицательной — (-1). На графике "облако точек" в этих случаях уже не "облако": точки точно ложатся на прямые.
Если же точки не выстраиваются по прямой линии, а образуют "облако", коэффициент корреляции по абсолютной величине становится меньше единицы и, по мере округления этого облака, приближается к нулю, то между переменными точно нет линейной корреляционной зависимости.
На практике пользуются понятиями "сильная корреляция" и "слабая корреляция". Это достаточно условные понятия. В гуманитарных науках корреляция считается сильной, если ее коэффициент выше 0,60; если же он превышает 0,90, то корреляция считается очень сильной. Следует, однако, иметь в виду, что все это годится лишь при большом количестве точек, по которым вычисляется коэффициент корреляции. Говоря более формально, важен не только сам коэффициент, но и степень его достоверности, для вычисления которой существуют специальные правила.
Для вычисления коэффициента корреляции используется формула:
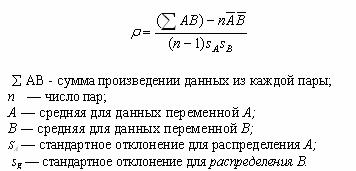
Коэффициент корреляции определяет степень, с которой значения двух переменных "пропорциональны" друг другу. Важно, что значение коэффициента корреляции не зависит от масштаба измерения. Например, корреляция между ростом и весом будет одной и той же, независимо от того, проводились измерения в дюймах и фунтах или в сантиметрах и килограммах. Пропорциональность означает просто линейную зависимость.
В качестве примера опишем способ получения с помощью MS Excel регрессионной модели по методу наименьших квадратов для приведенной выше задачи медицинской статистики. Начать надо с ввода табличных данных и построения точечной диаграммы. Далее следует:
=> щелкнуть мышью по полю диаграммы;
=>выполнить команду Диаграмма => Добавить линию тренда;
=>в открывшемся окне на закладке "Тип" выбрать "Линейный тренд";
=> перейти к закладке "Параметры"; установить галочки на флажках "показывать уравнения на диаграмме" и "поместить на диаграмму величину достоверности аппроксимации R^2", щелкнуть по кнопке ОК.
Диаграмма готова! Аналогично можно получить и другие типы трендов. Квадратичный тренд получается путем выбора полиномиального типа функции с указанием степени 2.
Заметим, что MS Excel дает возможность пользователю самому задавать тип регрессионной модели, а не ограничиватьсяпредлагаемым меню из шести функций. Однако для большого числа практических ситуаций этих функций бывает вполне достаточно.

