2015-10-22
2015-10-22 1019
1019Эффективность функционирования информационной системы во многом зависит от ее архитектуры. В современных условиях свыше 90% всех ИС используют БД для обеспечения хранения информации. Существует несколько вариантов организации взаимодействия ИС с БД, обеспечивающие наиболее эффективное ее использование. Коротко рассмотрим каждый из таких вариантов.
1. БД расположена локально (на том же компьютере, где функционирует ИС). Хорошо подходят для систем малого объема, предназначенных для индивидуального использования. Преимущества: простота, легкость в обслуживании, дешевизна. Недостатки: невозможность одновременной работы нескольких пользователей с одним и тем же набором данных.
2. БД размещена на компьютере-сервере, выполняющем функции файл-сервера. Сервером называется компьютер, предоставляющий свои услуги другим компьютерам, имеющим возможность подключаться к нему и запрашивать эти услуги (клиентам). Фактически это выглядит также как и в случае с локальной БД, но файлы БД доступны посредством локальной сети. В ходе сеанса работы происходит непрерывный обмен информацией между сервером и компьютером пользователя, в ходе которого файлы БД передаются на компьютеры пользователей, где производится их обработка. Преимущества: возможность доступа к БД с нескольких рабочих мест (нескольких пользователей). Недостатки: невозможность одновременной корректировки (внесения изменений) в содержимое БД несколькими пользователями одновременно. Если один пользователь находится в режиме редактирования таблицы БД, остальные могут ее только просматривать, высокая интенсивность передачи обрабатываемых данных. Зачастую передаются избыточные данные: вне зависимости от того сколько записей БД требуется пользователю, файлы БД передаются целиком.
3. БД размещена на компьютере-сервере, выполняющем функции клиент-сервера. При этом сервер БД обеспечивает выполнение основного объема обработки данных. Формируемые клиентом запросы поступают к серверу БД в виде инструкций языка SQL. Сервер БД выполняет поиск и извлечение нужных данных, которые затем передаются на компьютер пользователя. Достоинства: меньший объем передаваемых данных, быстрая обработка больших объемов информации за счет оптимизации процедур обработки информации. Недостатки: необходимость наличия отдельной программы-сервера, обеспечивающих исполнение запросов пользователей. Наиболее распространенными СУБД являются MS SQL Server, Oracle, Sybase, Informix, Interbase. В настоящее время перспективной является архитектура клиент-сервер.
Так как система в целом может быть четко разделена на две части (сервер и клиенты), появляется возможность работы этих двух частей на разных машинах. Иначе говоря, существует возможность распределенной обработки. Распределенная обработка предполагает, что отдельные машины можно соединить какой-нибудь коммуникационной сетью таким способом, что определенная задача, обрабатывающая данные, может быть распределена на нескольких машинах в сети.
Модели данных
Модель данных определяет порядок организации данных в единое целое. Применение той или иной модели данных позволяет придать данным конкретную структуру и смысловое значение. Данные, вписанные в определенную модель, называют информацией. Другими словами, модель данных – это совокупность структур данных и операций по их обработке.
Пример:
Данные: «Иванов Иван Иванович 2500 р.»
Информация:
| ФИО сотрудника | Сумма выплаченного аванса, р. |
| Иванов Иван Иванович |
Любая модель данных должна обеспечивать представление основных категорий восприятия реального мира - объектов, их свойств, связей и взаимодействий объектов. Количество различных моделей данных определяется наличием различных множеств используемых информационных конструкций. Классификация информационных конструкций:
1. Объекты для технологии баз данных – отношения и веерные отношения.
2. Объекты для технологии искусственного интеллекта – предикаты, фреймы и семантические сети.
3. Объекты для технологии мультимедиа – тексты, графические изображения, фонограммы и видеофрагменты.
Упрощенная классификация моделей данных:
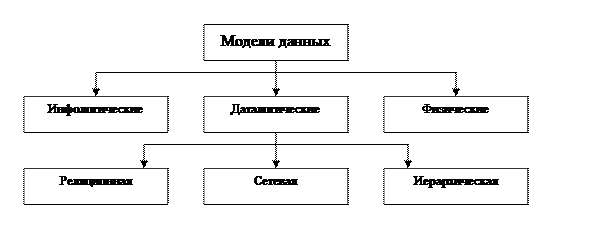
Инфологические модели данных используются на ранних стадиях проектирования для описания структур данных в процессе разработки приложения. Инфологические модели отражают в естественной и удобной для разработчиков и других пользователей форме описание объектов предметной области, их свойств и их взаимосвязей. Даталогические модели уже поддерживаются конкретной СУБД. Физические модели описывают структуры и принципы их хранения во внешней памяти, а также доступа к ним в зависимости от используемых аппаратных средств и программного обеспечения.