2015-10-22
2015-10-22 518
518Предположим, что нам надо записать последовательный файл, текстовый файл или, возможно, изображение на магнитный диск. Очевидно, что эти данные займут более одного сектора, что означает, что при каждом обращении к данным нам придется считывать последовательно несколько секторов. В первую очередь обратите внимание на то, что по возможности весь файл следует записывать на одну дорожку (или один цилиндр). В противном случае при обращении к данным придется перемещать головку считывания-записи. Другая особенность не столь очевидна — не следует хранить данные в последовательных секторах дорожки. Наоборот, лучше после каждого использованного сектора пропускать несколько.
Причина заключается в том, что после считывания одного сектора происходит небольшая задержка перед чтением следующего. Если мы записали соседние части файла на соседние секторы на дорожке, к моменту, когда все будет готово к считыванию очередного сектора, он уже пройдет мимо головки считывания-записи. Тогда, чтобы считать данные из нужного сектора, придется ждать следующего оборота диска. Если же между считанным сектором и сектором, к которому мы собираемся обратиться, есть ненужные нам секторы, то мы успеем подготовиться к считыванию сектора к моменту, когда он достигнет головки считывания-записи. В случае, если дорожка разбита на 16 секторов, мы можем записать последовательный файл в секторы 5, 10, 15, 1,6, 11, 16, 2, 7 и т. д1. Так мы используем все секторы на дорожке и сможем считать данные со всей дорожки всего за пять оборотов диска.
Идеальный пример этому можно найти в среде языка программирования С. Функция fgetpos используется для получения текущей позиции в файле. Например, оператор
fgetpos(Personnel. SPosition);
передает значение текущего положения в файле Personnel в переменную Position. (Способ кодировки этой позиции изменяется от системы к системе.) «Текущее положение» — это позиция, из/в которую в этом файле будет производиться следующая операция чтения/записи. Эту позицию можно использовать в индексе для сохранения местоположения записи на накопителе. Таким образом, если мы сохраним позицию, полученную при помощи fgetpos перед передачей на носитель каждой записи, то получим индекс, определяющий расположение записей. Если fgetpos используется для получения текущей позиции в файле, то при помощи функции fsetpos осуществляется переход к новой позиции. В частности, оператор
fsetpos(Personnel. SPosition);
запрашивает перемещение текущего положения в файле Personnel к позиции, значение которой хранится в переменной Position. Если после этого оператора выполнить оператор чтения из файла, мы получим данные, хранящиеся в соответствующем Position месте. Таким образом, fsetpos — это необходимый инструмент для восстановления нужной записи с использованием информации, полученной fgetpos.
Короче говоря, функция fgetpos позволяет получить расположение элемента данных в файле, и, если мы сохраним это значение в индексе, то при помощи функции fsetpos сможем вернуться к этой позиции и считать данные.
Хэширование
Хотя индексирование обеспечивает относительно быстрый доступ к записям в структуре хранения данных, оно достигает этого за счет поддержки индекса. Хэширование (hashing) — это способ, обеспечивающий похожий доступ без излишней нагрузки. Этот способ позволяет находить запись при помощи ключевого значения, но вместо поиска ключа в индексе хэширование определяет положение записи исходя из значения ключа. Процесс можно описать так: пространство хранилища данных разделено на несколько секций, называемых сегментами (bucket). Записи распределены по блокам согласно алгоритму (называемому хэш-функцией), который преобразует ключевые значения в номера сегментов. Каждая запись хранится в сегменте, идентифицируемом при помощи этого процесса. Таким образом, чтобы найти элемент в структуре хранилища, нужно применить хэш-функцию к идентификационному ключу этого элемента и определить соответствующий сегмент; затем считать содержимое сегмента и найти в нем нужную запись. Результат применения хэширования к структуре хранения на запоминающем устройстве называется хэш-файлом (hash file). Результат применения хэш-функции к структуре хранения в оперативной памяти обычно называется хэш-таблицей (hash table).
Хэш-система
Применим концепцию хэширования к классическому файлу сотрудников. Сначала на запоминающем устройстве выделим несколько свободных областей, которые будут играть роль сегментов. Выбор их количества и размера мы обсудим позже. Сейчас же предположим, что мы создали 40 сегментов, к которым будем обращаться как к сегменту № 0, сегменту № 1 и так далее до сегмента № 39.
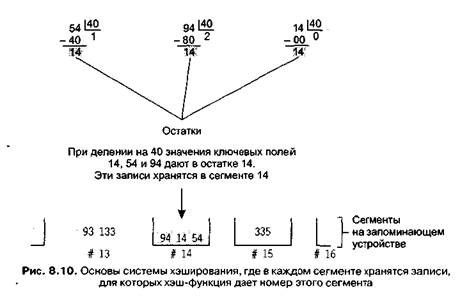
Предположим, что в качестве ключа для идентификации записи сотрудника будет использоваться его идентификационный номер. Наша следующая задача — разработать хэш-функцию для преобразования этих ключей в номера сегментов. Хотя идентификаторы могут иметь форму 25X3Z или J2X35, то есть не являться числовыми значениями, они хранятся в виде комбинаций битов, и мы можем интерпретировать эти комбинации как номера. Воспользовавшись числовой интерпретацией, разделим каждый ключ на количество сегментов и запишем остаток, который в нашем случае будет целым числом от 0 до 39. Таким образом, мы можем использовать остаток от деления для идентификации одного из наших 40 сегментов (рис. 8.10).
Искусство хэширования
Многое уже было написано о хэшировании. Цель всех исследований — найти эффективный алгоритм хэширования, равномерно распределяющий записи по сегментам. Один из способов, называемый методом середины квадрата (midsquare method), заключается в умножении ключевого значения на само себя и выборе средних цифр из результата. Эти цифры и являются номером сегмента. Другой метод называется методом выбора (extraction method), при этом выбираются цифры, находящиеся на определенных позициях в ключе, и номер сегмента создается путем перестановки этих цифр каким-либо предопределенным методом. Сегодня достаточно популярны различные вариации процесса деления, который мы обсуждали в этом разделе. Главная задача при этом — избежать ключей, подчиненных какой-либо системе, так как система среди ключей приводит к тому, что сегменты также выбираются согласно системе. По этой причине для функции хэширования лучше использовать последние несколько цифр в телефонных номерах, так как цифры в начале номера обычно представляют географическую область, населенный пункт и т. д. Аналогично, не рекомендуется использование имен в качестве ключей, так как в зависимости от региона определенные имена встречаются чаще (сравните, например, Смит, Иван, Мухаммед и Дешпанде).
Используя эти вычисления как хэш-функцию, мы перейдем к созданию файла. Будем брать записи по одной, применять к их ключу нашу хэш-функцию деления на 40, получать номера сегмента и затем передавать записи в соответствующие сегменты (рис. 8.11). Позже, если нам потребуется считать определенную запись, мы применим хэш-функцию к ее ключу, найдем соответствующий сегмент и произведем поиск этой записи в сегменте.