 2015-10-22
2015-10-22 515
515Завершим очередной раздел обзором возможностей, которые предлагают языки высокого уровня для управления структурами хранения рассмотренного типа. Для реализации хэширования в различных языках можно найти множество функций. Начнем с обсуждения программной среды Java.
Популярность хэширования как способа организации больших структур хранения в оперативной памяти отражается тем фактом, что в среде программирования Java существует предопределенный класс (тип) с названием Hashtable, при помощи которого можно конструировать таблицы. Точнее, оператор
Table = new HashtableCCapacity, Factor);
создаст объект типа Hashtable и назначит этот объект переменной Table. Переменная Capacity указывает количество сегментов, а переменная Factor определяет предел фактора нагрузки. Каждый сегмент таблицы на самом деле является связным списком, в котором содержатся записи, определенные хэш-функцией в этот сегмент. В результате хэш-таблица, созданная таким образом, не будет испытывать переполнения — сегменты просто будут постоянно расти. Но фактор нагрузки — это отношение непустых сегментов к общему количеству сегментов. Когда определенный предел фактора будет достигнут, Java автоматически увеличит количество сегментов и переделает всю таблицу.
Новые записи можно записывать в таблицу при помощи метода put (аргументы которого содержат ключевое значение и данные), а получать записи из таблицы можно методом get (в качестве аргумента передается ключевое значение). Обратите внимание, что такая структура освобождает Java-программиста от реализации и поддержки таблицы, то есть хэш-таблицу можно использовать как абстрактный инструмент.
Предположим, однако, что мы хотим создать хэш-файл на запоминающем устройстве, а не хэш-таблицу в оперативной памяти. В зависимости от языка программирования доступны различные подходы. Один из них заключается в создании нескольких последовательных файлов, каждый из которых играет роль отдельного сегмента. В этом случае с точки зрения операционной системы хэш-файл будет состоять из набора отдельных файлов. Могут возникнуть проблемы, так как операционная система часто ограничивает количество файлов, которые приложению разрешается одновременно открыть. Обойти эту сложность можно, разработав программу таким образом, чтобы она открывала и закрывала файлы при необходимости обратиться к различным сегментам.
Более практичный подход — зарезервировать большую область на запоминающем устройстве, объявив ее одним большим пустым файлом. Затем части этого файла можно использовать как сегменты нашей системы. Этот подход поддерживается в нескольких языках программирования. Например, язык COBOL позволяет программистам создавать большие пустые файлы, к которым можно обращаться как к массивам, то есть местоположения данных в файле могут быть указаны индексами. Тогда программист сможет создать такой файл и разбить на сегменты хэш-файла (рис. 8.13). К примеру, места с 1 по 20 можно считать первым сегментом, с 21 по 40 — вторым и т. д. Таким образом, по необходимости к содержимому отдельных сегментов можно обращаться напрямую.

Схожую систему можно реализовать на языке С, используя для доступа к разным частям файла функции fgetpos и fsetpos, с которыми мы познакомились в предыдущем разделе.
Еще один подход к созданию хэш-файла использует преимущества большого объема оперативной памяти, доступного в современных компьютерах. Он заключается в считывании всего файла в оперативную память при первом открытии и обращении к нему как к большой хэш-таблице. В таких случаях в действительности данные хранятся в последовательном файле, из которого во время выполнения программы создается хэш-таблица.
Этот подход реализован в языке Java. В среде программирования Java есть вариация класса Hashtable под названием Properties. Объект типа Properties является хэш-таблицей, которую можно инициализировать из файла на запоминающем устройстве при помощи метода 1 oad и записать на устройство методом store. Но не следует думать, что объект типа Properties хранится на запоминающем устройстве как хэш-файл. Это последовательный файл, состоящий из последовательности битов, из которой соответствующая хэш-таблица конструируется в оперативной памяти.
СТРУКТУРЫ БАЗ ДАННЫХ
Базы данных представляют собой синтез структур данных и файловых структур. В современных базах данных методы из обеих областей применяются для создания такой системы хранения больших объемов данных, которая может выглядеть как система с множеством видов организаций данных и обслуживать приложения различных типов. В этой главе мы рассмотрим строение систем баз данных и некоторые направления современных исследований.
Общие вопросы
Термин база данных (database) относится к набору данных, многомерному в том смысле, что между его элементами существуют внутренние связи, и поэтому доступ к информации можно осуществлять с различных точек зрения. В этом отличие базы данных от файлов традиционных систем, иногда называемых одноуровневыми файлами, которые являются одномерной системой хранения и представляют информацию только с одной точки зрения. Если одноуровневый файл, в котором хранится информация о композиторах и их произведениях, может предоставить только список произведений, отсортированный по автору, в базе данных можно найти все работы одного композитора, всех композиторов, написавших произведения определенного типа, или, например, всех композиторов, создавших аранжировки произведений других авторов.
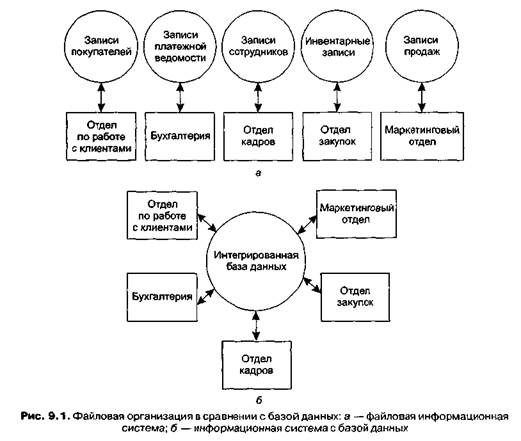
Исторически базы данных развивались как способ интеграции систем хранения данных. С развитием компьютерных технологий для них находилось все больше применений в управлении информацией, и каждое приложение реализовыва-лось как отдельная система с собственным набором данных. Необходимость обработки платежных ведомостей привела к появлению последовательных файлов, а позже необходимость интерактивного получения данных в отделах кадров привела к возникновению другой файловой структуры, основанной на индексировании. Хотя обе эти системы представляют собой существенное улучшение прежних ручных способов обработки данных, набор отдельных автоматизированных систем все же являлся неэффективной тратой ресурсов по сравнению с возможностями интегрированной системы базы данных. Например, если в каждом отделе использовалась собственная файловая система, большая часть информации, необходимой в организации, дублировалась в этих хранилищах. В результате, когда сотрудник переезжал на новое место жительства, ему необходимо было посетить несколько отделов по всей организации, чтобы заполнить там формы о смене адреса. Опечатки, неправильное размещение учетных карточек или бездействие сотрудника приводили к появлению ошибочных и конфликтующих между собой данных в различных системах. После переезда информационный бюллетень мог прийти по правильному адресу, но с указанием неверного имени, а в записях платежной ведомости мог все так же оставаться старый адрес. Системы баз данных стали мощным средством интеграции информации, хранимой и обрабатываемой внутри определенной структуры (рис. 9.1). В них и с платежными ведомостями, и с информационными бюллетенями можно работать внутри одной интегрированной информационной системы.
Еще одно преимущество интегрированной информационной системы состоит в контроле, который получает организация, когда вся ее информация размещена в одном общем хранилище. Если каждый отдел обладает собственными независимыми данными, эти данные обычно работают на конкретный отдел, а не на целую организацию. В противоположность этому, если в большой организации внедрена интегрированная база данных, управление информацией может быть отдано административной должности, известной как администратор базы данных (database administrator, DBA), которая исполняется одним или несколькими сотрудниками. Этот центральный администратор осведомлен как о данных, доступных внутри организации, так и о потребностях различных отделов. Таким образом, в структуре базы данных заложено, что решения относительно организации и доступа к данным можно принимать, учитывая интересы всей организации.
Там, где есть преимущества, есть и недостатки. Одна из проблем — управление доступом к данным, требующим деликатного обращения. Например, сотрудник, работающий с информационными бюллетенями организации, должен иметь доступ к именам и адресам всех сотрудников, но финансовые данные должны быть ему недоступны; аналогично, сотрудник, занимающийся платежными ведомостями, не должен иметь доступ к прочим финансовым записям корпорации. Можно утверждать, что правильное управление доступом к информации в базе данных зачастую так же важно, как и возможность совместно использовать ее.
Разграничение прав доступа в системах баз данных обычно осуществляется на основе схем и подсхем. Схема (schema) — это описание структуры всей базы данных, которое используется в приложениях базы данных. Подсхема — это описание только части базы данных, имеющей отношение к определенным задачам пользователя. Например, представим себе схему университетской базы данных, записи о студентах в которой содержат не только поля, относящиеся к учебе, но и текущий адрес, и номер телефона. Кроме того, в базе запись каждого студента связана с записью его факультетского научного руководителя. Записи каждого сотрудника факультета содержат имя, адрес, сведения о трудовой деятельности и т. д. На основе этой схемы поддерживается система указателей, которая в конечном итоге может даже связать информацию о студенте с данными о трудовой деятельности сотрудника факультета.
Чтобы секретарь университета не мог при помощи этих связей получить конфиденциальную информацию о факультете, его права доступа к базе данных должны, быть ограничены подсхемой, которая описывает записи факультета, но не включает сведения о трудовой деятельности. В пределах этой подсхемы пользователь может узнать, кто из сотрудников факультета является научным руководителем определенного студента, но не может получить дополнительную информацию об этом сотруднике. А подсхема для бухгалтерии позволяет получить данные о трудовой деятельности любого сотрудника факультета, но не предоставляет информации о связях между студентами и научными руководителями. Так, бухгалтер сможет изменить размер заработной платы сотрудника факультета, но не сможет узнать имена студентов, для которых данный сотрудник является научным руководителем.
Кроме относящихся непосредственно к безопасности существуют и другие недостатки, связанные с развитием технологии баз данных. Сегодня возможно хранить огромные объемы данных и обмениваться ими на больших расстояниях с минимальными усилиями, и с этим увеличением масштаба возрастает вероятность получения неверных данных и неправильного их применения. Известно немало случаев несправедливых действий, произошедших по причине неправильных отчетов о кредитных операциях, ошибочных досье преступников и дискриминации, причиной которых был неавторизованный или неэтичный доступ к частной информации.
В других случаях проблема возникает в первую очередь из-за права собирать и хранить информацию. Какого рода информацию о своих клиентах имеет право собирать страховая компания? Имеет ли право правительство вести учет мнений отдельных граждан, высказанных посредством голосования? Имеет ли право компания, продающая товары по кредитным карточкам, продавать записи о покупках, совершенных ее клиентами, в маркетинговые фирмы? Эти вопросы представляют лишь несколько проблем, которые необходимо решить обществу в связи с разрастанием технологий баз данных.








