 2015-10-22
2015-10-22 8624
8624Информация, представленная в формализованном виде, пригодном для автоматизированной ее обработки, хранения и передачи, называются данными. С точки зрения программиста данные — это часть программы совокупность значений определенных ячеек памяти преобразование которых осуществляет код. С точки зрения компилятора процессора операционной системы это совокупность ячеек памяти, обладающих определёнными свойствами.
Как правило, данные имеют форму чисел, литер, текстов, символов и более сложных структур типа последовательностей, списков и деревьев и др.
Под структурой данных в общем случае понимают множество элементов данных и множество связей между ними. Структура данных - организационная схема записи или массива, в соответствии с которой упорядочены данные, с тем чтобы их можно было интерпретировать и выполнять над ними определенные операции.
Структура данных - это исполнитель, который организует работу с данными, включая их хранение, добавление и удаление, модификацию, поиск и т.д. Структура данных поддерживает определенный порядок доступа к ним. Структуру данных можно рассматривать как своего рода склад или библиотеку. При описании структуры данных нужно перечислить набор действий, которые возможны для нее, и четко описать результат каждого действия.
Структура данных определяет их семантику, а также способы организации и управления ими. Структура данных и алгоритмы служат тем материалом, из которого строятся программы.
Понятие " физическая структура данных” отражает способ физического представления данных в памяти машины. Рассмотрение структуры данных без учета ее представления в машинной памяти называется абстрактной или логической структурой. Различаются простые (базовые, примитивные) структуры (типы) данных и интегрированные (структурированные, композитные). Простыми называются такие структуры данных, которые не могут быть расчленены на составные части, большие, чем биты. Для физической структуры можно заранее сказать, каков будет размер данного простого типа и какова структура его размещения в памяти. С логической точки зрения простые данные являются неделимыми единицами.
Интегрированными называются такие структуры данных, составными частями которых являются другие структуры данных - простые или в свою очередь интегрированные. Интегрированные структуры данных конструируются программистом с использованием средств интеграции данных, предоставляемых языками программирования.
В зависимости от отсутствия или наличия явно заданных связей между элементами данных следует различать несвязные структуры (векторы, массивы, строки, стеки, очереди) и связные структуры (связные списки).
Классификация структур данных по признаку изменчивости. Важный признак структуры данных - ее изменчивость, т.е. изменение числа элементов и (или) связей между элементами структуры. В определении изменчивости структуры не отражен факт изменения значений элементов данных, поскольку в этом случае все структуры
данных имели бы свойство изменчивости. По признаку изменчивости различают структуры статические, полустатические, динамические и файловые. Классификация структур данных по признаку изменчивости приведена на рис. 1.

Рис. 1 Классификация структур данных
Базовые структуры данных, статические, полустатические и динамические характерны для оперативной памяти и часто называются оперативными структурами. Файловые структуры соответствуют структурам данных для внешней памяти.
Простые структуры данных называют также примитивными или базовыми структурами. Эти структуры служат основой для построения более сложных структур. В языках программирования простые структуры описываются простыми (базовыми) типами. К таким типам относятся: числовые, битовые, логические, символьные, перечисляемые, интервальные, указатели.
Приведем определения статических структур. В этих структурах количество элементов строго фиксировано.
Вектор (одномерный массив) - структура данных с фиксированным числом элементов одного и того же типа. Каждый элемент вектора имеет уникальный в рамках заданного вектора номер. Обращение к элементу вектора выполняется по имени вектора и номеру требуемого элемента.
Массив - такая структура данных, которая характеризуется:
· фиксированным набором элементов одного и того же типа;
· каждый элемент имеет уникальный набор значений индексов;
· количество индексов определяют мерность массива, например, два индекса - двумерный массив, три индекса - трехмерный массив, один индекс - одномерный массив или вектор;
· обращение к элементу массива выполняется по имени массива и значениям индексов для данного элемента.
Множество - структура данных, которая представляет собой набор неповторяющихся данных одного и того же типа. Множество может принимать все значения базового типа. Базовый тип не должен превышать 256 возможных значений.
Запись - конечное упорядоченное множество полей, характеризующихся различным типом данных.
Таблица - последовательность записей, которые имеют одну и ту же организацию. С физической точки зрения таблица представляет собой вектор, элементами которого являются записи. Характерной логической особенностью таблиц является то, что доступ к элементам таблицы производится не по номеру (индексу), а по ключу - по значению одного из свойств объекта, описываемого записью-элементом таблицы. Ключ - это свойство, идентифицирующее данную запись во множестве однотипных записей. Как правило, к ключу предъявляется требование уникальности в данной таблице.
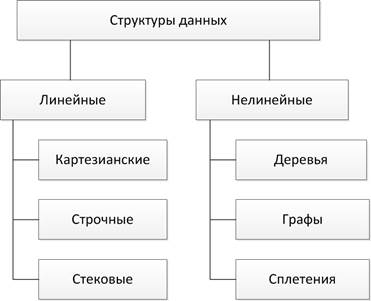
Рис 2. Структура данных по признаку упорядоченности
Важный признак структуры данных - характер упорядоченности ее элементов. По этому признаку структуры можно делить на линейные и нелинейные структуры (см. рис.2). В линейных структурах связи между элементами не зависят от какого-либо условия. В нелинейных структурах связи между элементами зависят от выполнения определенного условия.
Картезианские (прямоугольные) структуры включают в себя множество, матрицу, вектор, структуру, имеющую вид прямоугольных таблиц.
Строчные структуры (типа ряда) - одномерные, динамически изменяемые структуры данных, различающиеся способами включения и исключения элементов. К ним относятся: стек, дек, очередь, строка.
Стек - такой последовательный список с переменной длиной, включение и исключение элементов из которого выполняются только с одной стороны списка, называемого вершиной стека. Применяются и другие названия стека - магазин и очередь, функционирующая по принципу LIFO (Last - In - First- Out - "последним пришел - первым исключается").
Очередью FIFO (First - In - First- Out - "первым пришел - первым исключается") называется такой последовательный список с переменной длиной, в котором включение элементов выполняется только с одной стороны списка (эту сторону часто называют концом или хвостом очереди), а исключение - с другой стороны (называемой началом или головой очереди). Основные операции над очередью - те же, что и над стеком - включение, исключение, определение размера, очистка, неразрушающее чтение.
Дек - особый вид очереди. Дек (от англ. deq - double ended queue,T.e очередь с
двумя концами) - это такой последовательный список, в котором как включение, так и исключение элементов может осуществляться с любого из двух концов списка. Применительно к деку целесообразно говорить не о начале и конце, а о левом и правом конце.
Строка - это линейно упорядоченная последовательность символов, принадлежащих конечному множеству символов, называемому алфавитом.
Строки обладают следующими важными свойствами:
· их длина, как правило, переменна, хотя алфавит фиксирован;
· обычно обращение к символам строки идет с какого-нибудь одного конца
последовательности, т.е важна упорядоченность этой последовательности, а не ее индексация; в связи с этим свойством строки часто называют также цепочками;
· чаще всего целью доступа к строке является не отдельный ее элемент (хотя это тоже не исключается), а некоторая цепочка символов в строке.
Говоря о строках, обычно имеют в виду текстовые строки - строки, состоящие из
символов, входящих в алфавит какого-либо выбранного языка, цифр, знаков
препинания и других служебных символов. Базовыми операциями над строками
являются: определение длины строки; присваивание строк; конкатенация (сцепление) строк; выделение подстроки; поиск вхождения.
К нелинейным структурам относятся: деревья, графы, сплетения.
Дерево - это граф, который характеризуется следующими свойствами:
Существует единственный элемент (узел или вершина), на который не ссылается никакой другой элемент - и который называется корнем
Начиная с корня и следуя по определенной цепочке указателей, содержащихся в элементах, можно осуществить доступ к любому элементу структуры.
На каждый элемент, кроме корня, имеется единственная ссылка, т.е. каждый элемент адресуется единственным указателем.
Название "дерево" проистекает из логической эквивалентности древовидной структуры абстрактному дереву в теории графов. Линия связи между парой узлов дерева называется обычно ветвью. Те узлы, которые не ссылаются ни на какие другие узлы дерева, называются листьями (или терминальными вершинами). Узел, не являющийся листом или корнем, считается промежуточным или узлом ветвления (нетерминальной или внутренней вершиной).
Граф - это сложная нелинейная многосвязная динамическая структура, отображающая свойства и связи сложного объекта.
Многосвязная структура обладает следующими свойствами:
1. на каждый элемент (узел, вершину) может быть произвольное количество ссылок;
2. каждый элемент может иметь связь с любым количеством других элементов;
3. каждая связка (ребро, дуга) может иметь направление и вес.
В узлах графа содержится информация об элементах объекта. Связи между узлами задаются ребрами графа. Ребра графа могут иметь направленность, показываемую стрелками, тогда они называются ориентированными, ребра без стрелок - неориентированные.
Сплетение (многосвязанный список, плекс) - это нелинейная структура данных, объединяющая такие понятия, КПК дерево, граф и списковые структуры. У каждого элемента имеется несколько полей с указателями на другие элементы того же сплетения.
В зависимости от характера взаимного расположения элементов в памяти линейные структуры можно разделить на структуры с последовательным распределением элементов в памяти (векторы, строки, массивы, стеки, очереди) и структуры с произвольным связным распределением элементов в памяти (односвязные, двусвязные списки). Пример нелинейных структур - многосвязные списки, деревья, графы.
В языках программирования понятие "структуры данных” тесно связано с понятием "типы данных". Любые данные, т.е. константы, переменные, значения функций или выражения, характеризуются своими типами.
Информация по каждому типу однозначно определяет:
1. структуру хранения данных указанного типа, т.е. выделение памяти и представление данных в ней, с одной стороны, и интерпретирование двоичного представления, с другой;
2. множество допустимых значений, которые может иметь тот или иной объект описываемого типа;
3. множество допустимых операций, которые применимы к объекту описываемого типа.
Концепция типа данных появилась в языках программирования высокого уровня как естественное отражение того факта, что обрабатываемые программой данные могут иметь различные множества допустимых значений, храниться в памяти компьютера различным образом, занимать различные объёмы памяти и обрабатываться с помощью различных команд процессора.
Над любыми структурами данных могут выполняться четыре общие операции: создание, уничтожение, выбор (доступ), обновление.
Операции с массивами. Типичными операциями при работе с массивами являются:
· вывод массива;
· ввод массива;
· поиск максимального или минимального элемента массива;
· поиск заданного элемента массива;
· сортировка массива.
Ввод массива. Чтобы заполнить массив данными, существует несколько способов:
· непосредственное присваивание значений элементам;
· генерация и присваивание значений с помощью функции random;
· ввод значений элементов с клавиатуры;
Вывод массива. Под выводом массива понимается вывод на экран монитора (в диалоговое окно) значений элементов массива.
Алгоритмы сортировки одномерных массивов и поиска элементов Существует большое количество алгоритмов сортировки массивов, но все они базируются на трех основных: сортировка обменом; сортировка выбором; сортировка вставкой.
1. Сортировка методом "пузырька".
В основе алгоритма лежит обмен соседних элементов массива. Каждый элемент массива, начиная с первого, сравнивается со следующим, и если он больше следующего, то элементы меняются местами. Таким образом, элементы с меньшим значением продвигаются к началу массива (всплывают), а элементы с большим значением — к концу массива (тонут). Поэтому данный метод сортировки обменом иногда называют методом "пузырька". Этот процесс повторяется столько раз, сколько элементов в массиве, минус единица.

