 2015-10-22
2015-10-22 1132
1132Двувходовое объединение используется (относительно редко) в обстоятельствах, когда ожидается, что и наблюдения и переменные одновременно вносят вклад в обнаружение осмысленных кластеров.
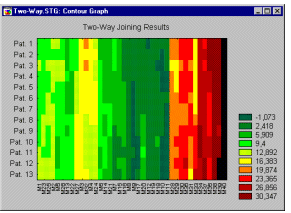
Так, возвращаясь к предыдущему примеру, можно предположить, что медицинскому исследователю требуется выделить кластеры пациентов, сходных по отношению к определенным кластерам характеристик физического состояния. Трудность с интерпретацией полученных результатов возникает вследствие того, что сходства между различными кластерами могут происходить из (или быть причиной) некоторого различия подмножеств переменных. Поэтому получающиеся кластеры являются по своей природе неоднородными. Возможно это кажется вначале немного туманным; в самом деле, в сравнении с другими описанными методами кластерного анализа (см. Объединение (древовидная кластеризация) и Метод K средних), двувходовое объединение является, вероятно, наименее часто используемым методом. Однако некоторые исследователи полагают, что он предлагает мощное средство разведочного анализа данных (за более подробной информацией вы можете обратиться к описанию этого метода у Хартигана (Hartigan, 1975))
Метод K средних
· Пример
· Вычисления
· Интерпретация результатов
· Общая логика
Этот метод кластеризации существенно отличается от таких агломеративных методов, как Объединение (древовидная кластеризация) и Двувходовое объединение. Предположим, вы уже имеете гипотезы относительно числа кластеров (по наблюдениям или по переменным). Вы можете указать системе образовать ровно три кластера так, чтобы они были настолько различны, насколько это возможно. Это именно тот тип задач, которые решает алгоритм метода K средних. В общем случае метод K средних строит ровно K различных кластеров, расположенных на возможно больших расстояниях друг от друга.
Пример
В примере с физическим состоянием (см. Двувходовое объединение), медицинский исследователь может иметь "подозрение" из своего клинического опыта, что его пациенты в основном попадают в три различные категории. Далее он может захотеть узнать, может ли его интуиция быть подтверждена численно, то есть, в самом ли деле кластерный анализ K средних даст три кластера пациентов, как ожидалось? Если это так, то средние различных мер физических параметров для каждого кластера будут давать количественный способ представления гипотез исследователя (например, пациенты в кластере 1 имеют высокий параметр 1, меньший параметр 2 и т.д.).
Вычисления
С вычислительной точки зрения вы можете рассматривать этот метод, как дисперсионный анализ (см. Дисперсионный анализ) "наоборот". Программа начинает с K случайно выбранных кластеров, а затем изменяет принадлежность объектов к ним, чтобы: (1) - минимизировать изменчивость внутри кластеров, и (2) - максимизировать изменчивость между кластерами. Данный способ аналогичен методу "дисперсионный анализ (ANOVA) наоборот" в том смысле, что критерий значимости в дисперсионном анализе сравнивает межгрупповую изменчивость с внутригрупповой при проверке гипотезы о том, что средние в группах отличаются друг от друга. В кластеризации методом K средних программа перемещает объекты (т.е. наблюдения) из одних групп (кластеров) в другие для того, чтобы получить наиболее значимый результат при проведении дисперсионного анализа (ANOVA).

