2015-10-22
2015-10-22 863
863Интеграция Northbridge в процессор и SUMA-архитектура K8 не просто обеспечивает «более быстрый контроллер оперативной памяти», - она заодно позволяет очень эффективно решать и ряд свойственных многопроцессорным системам проблем.
Во-первых, SUMA решает «проблему общей памяти». Если сравнивать сегодняшние системы (а это, как минимум, двухканальная DDR400) с системами трехлетней давности (одноканальная SDRAM PC133), то прогресс здесь, конечно, достигнут впечатляющий: пропускная способность оперативной памяти увеличилась более чем в 8-10 раз, в то время, как вычислительная мощность центральных процессоров – несколько меньше (в ряде тестов - только в 3-4 раза). Правда, латентность оперативной памяти по меркам процессора остается по-прежнему огромной, но и с этой напастью научились эффективно бороться, используя кэш-память внушительных размеров и механизмы аппаратной и программной предвыборки из памяти. Однако стоит поставить в систему не одно, а два, четыре, а то и восемь процессорных ядер, как проблема «медленной памяти» всплывает с прежней силой – особенно в архитектуре SMP с контроллером памяти в чипсепте:
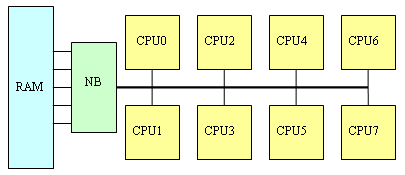 |
На практике это выливается в «проблему масштабируемости» - когда использование нескольких процессоров не приводит к ожидаемому приросту производительности. Считайте сами: если, например, одиночный процессор 20% своего времени простаивал, ожидая данных из оперативной памяти, то «двушка» будет простаивать 33% времени, а «четверка» - 50%. В пересчёте на общую производительность, 1P-система работает со скоростью 100%, 2P-система – со скоростью 167% (вместо расчётных 200%), а 4P-система – со скоростью 250% (вместо 400%). Более того: получить даже пятикратный прирост производительности в данном случае невозможно в принципе (см. график ниже)! И ничего с этим поделать невозможно. Интересно, кстати, что этот эффект свойственен исключительно многопроцессорным системам: если в примере выше заменить оперативную память на вдвое более быструю, то производительность однопроцессорной системы возрастет лишь на жалкие 11%. (Такие «ужасы» получаются в программах, которые много времени проводят в ожидании данных от памяти (не из кэша, а именно из ОЗУ: если у нас программа почти всегда работает с кэшем – никаких проблем не возникает). То есть если на одном процессоре 80% времени вычислений и 20% ожидания данных из памяти, то на двух получаем «40%» вычислений и «20%» ожидания данных из памяти (в пересчёте к «старым» процентам); выигрыш составляет 100/60 = 167%. И так далее. Ставим вдвое более быструю память – получаем на двухпроцессорной системе «80%» вычислений и «10%» ожидания данных из памяти; выигрыш – 100/90=111%).
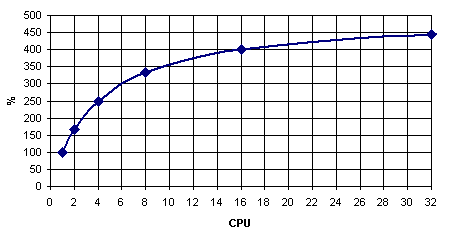 |
В идеале любая многопроцессорная система должна быть хорошо сбалансирована – слишком быстрая память обходится слишком дорого; слишком медленная – сводит эффект от установки нескольких процессоров к минимуму. То есть если для однопроцессорной системы вполне достаточно двухканальной оперативной памяти DDR (а практика показывает, что это, скорее всего, так), то в «двушку» желательно установить четырехканальный, а в «квад» - восьмиканальный контроллер памяти DDR. Но на практике даже четырехканальный контроллер пока обходится слишком дорого: заикаться же о чем-то большем в «классических» SMP даже не приходится. Правда, четыре канала в следующем поколении чипсетов Intel мы всё-таки увидим (причем контроллеры памяти в них вынесены за пределы Northbridge в виде отдельных микросхем); а через два года, к 2008му, на рынке должна появиться серверная оперативная память FB-DIMM с последовательным интерфейсом доступа к памяти, которая позволит создавать шести- и восьмиканальные- контроллеры памяти.
Но это всё - в SMP: а вот в NUMA (типа AMD-шной), где двухканальный контроллер памяти интегрирован в каждый процессор, суммарная производительность подсистемы памяти как раз и возрастает пропорционально количеству процессоров. Правда, у NUMA, как уже было сказано, «свои тараканы» - неоднородность скорости работы различных участков памяти. В случае новых AMD Opteron можно подсчитать, что «в среднем» пропускная способность памяти в пересчёте на один процессор составляет для 2P-систем порядка 81% (100% в лучшем, 62% в худшем), для 4P – где-то между 62% и 53% (31% в худшем случае). Для 8P-систем всё гораздо неприятнее – без учета особенностей NUMA там не получится «выжать» из подсистемы памяти и 30% её пропускной способности (большинство обращений будут к чужой памяти, причем в среднем каждый линк HT будут занимать по три процессора одновременно). (Суть этих оценок в том, чтобы посчитать устоявшиеся потоки данных, полагая, что они равномерно распределяются по кратчайшим путям между процессорами. Считается, сколько каждому CPU достанется «процентов» от общей пропускной способности линков HT; считаются доли запросов в «свою» память и запросов, проходящих через линки HT. Например, для двухпроцессорной системы линк HT процессору ни с кем делить не требуется, 50% запросов идет в оперативную память, 50% - по линку HT. Всего (6,4 * 0,5 + 4,0 * 0,5) = 5,2 Гбайт/c, т.е. 5,2/6,4 = 81%.)
Впрочем, если сравнивать с аналогичными цифрами для SMP (50, 25 и 12% соответственно), то нельзя не признать, что даже неоптимизированные программы должны работать с памятью на Opteron-ах в несколько раз быстрее, чем на «традиционных» SMP. А если еще вспомнить, что кросс-бар и контроллер памяти AMD K8 работают с поразительно низкой латентностью1, то эффективности работы Opteron с оперативной памятью можно только позавидовать.
 Увеличить Увеличить |
Решение «проблемы общей памяти» - далеко не единственное преимущество подхода AMD. Обычные SMP страдают еще и от «проблемы общей шины»: мало сделать быстрый контроллер памяти – нужно еще и обеспечить достаточно быструю передачу полученных из памяти данных к процессору. Что толку с того, что новейший чипсет Intel 955X Express, поддерживает двухканальную оперативную память DDR2 667 МГц с пиковой пропускной способностью 10,7 Гбайт/с, если 800-мегагерцовая процессорная шина не позволяет «прокачивать» более 6,4 Гбайт/с? И ведь это еще не всё: чем больше процессоров мы помещаем на системную шину, тем сложнее обеспечить безошибочную передачу по ней данных (возрастает электрическая нагрузка, усложняется разводка). В итоге если один процессор свободно работает с шиной 800 и даже 1066 МГц, то два процессора уже вынуждены ограничиться шиной не выше 800 МГц, а четыре – так и вовсе работают только с шиной 667 МГц и ниже. Вот так всё неидеально получается для SMP. Мегабайты и даже десятки мегабайт кэш-памяти третьего уровня для них не роскошь, а жестокая необходимость.
Intel, правда, нашла достаточно успешный способ отчасти обойти эту проблему, используя в новейших многопроцессорных системах сразу две независимых процессорных шины. Но в неоднородной AMD-шной SUMA-архитектуре этой проблемы-то вообще нет! И хотя два ядра в двухядерниках AMD разделяют общую шину SRI, работает эта шина все же, как и кросс-бар, на полной частоте процессора, как и вообще все его «внутренние» шины. То есть ничем не отличается, скажем, от шины, соединяющий между собой его кэш-память различных уровней. В итоге эта «общая» шина у AMD получается настолько быстродействующая, что ядра друг другу практически не мешают – их ограничивает только пропускная способность оперативной памяти, да ведущих во «внешний мир» линков HyperTransport.