 2017-12-14
2017-12-14 1227
1227В нашем исследовании мы преобразуем события нажатия клавиш в два разных действия.
1. Действие с одним ключом, где функция - это время удержания ключа данного ключа. Из таблицы 7 видно, что seq. 61 и 62 - это действие с одним ключом, связанное с вводом ключа «N». Таким образом, функция нажатия клавиши «N» будет разницей во времени между событием нажатия клавиши и событием отпускания.
2. Действие ключевого диграфа, в котором функции: (1) Общая продолжительность; (2) время между первым нажатием клавиши и вторым нажатием клавиши (DownDownTime); (3) время между первым нажатием клавиши и вторым нажатием клавиши (Up-DownTime); и (4) время между выделением первого ключа и высвобождением второго ключа (время нарастания) конкретного ключевого ордера [4].
На фиг.7 представлено графическое представление процесса выделения признаков динамики нажатия клавиши. В таблице 7, 69-72 - это два последовательных ключа «I» и «S». Обратите внимание, что разность времени между нажатием клавиши «I» и нажатием клавиши «S» составляет 359 мс. В нашем анализе мы применили ограничение для действия KeyDigraph, что латентность между двумя последовательными ключами должна быть ниже 2000 мс. Например, в Таблице 7 мы видим, что латентность между «a» и «b» в событиях 77 и 78 равна 2624 мс, поэтому эта латентность выше порога в 2000 мс и, следовательно, действие ключевого диграфа «ab» будет проигнорировано. Причина, по которой длительные задержки игнорируются, заключается в том, что они не представляют собой нормальное поведение пользователя. Например, пользователь может остановиться, подумать, выпить кофе или прочитать что-то, а затем время, прошедшее между выпуском последней клавиши и нажатием новой клавиши, не является репрезентативным дляего обычного типирования.

Рисунок 7. Особенности динамики нажатия клавиш.
Таблица 9
Функции траектории мыши для перемещения мыши и перетаскивания. Здесь Pi - координата x-y последовательности перемещения мыши, где i = 0, 1, 2,..., n.

5.6. Особенности динамики мыши
В наших исследованиях мы превратили события мыши в четыре разных действия.
1. Действие мыши с одним щелчком мыши, где эта функция похожа на действие с одним ключом. В таблице 7 мы видим, что seq. 55 и 59 образуют действие мыши с одним щелчком мыши. Таким образом, для этого действия мыши одним щелчком мыши будет разница во времени между событием мыши (секвенция 55) и событием мыши (см. 59).
2. Действие мыши с двойным щелчком мыши, где функции те же, что и для действия ключевого диграфа. Два последовательных щелчка мыши считаются двойным щелчком, когда время простоя ниже порога 1000 мс.
3. Мышь MoveAction может быть сформирована последовательностью событий перемещения мыши. В таблице 7 мы видим, что seq. 5-54 образуют последовательность действия перемещения мыши, а функции для этого действия представлены в таблице 9. 4. Мышь Drag-DropAction очень похожа на действие перемещения мыши. Для этого действия сначала должно быть событие щелчка мыши, за которым следуют последовательности перемещения мыши, а затем событие мыши. Подобно функциям перемещения мыши, мы рассчитали действие «Перетаскивание мышью мыши» в соответствии с таблицей 9 и также добавили функцию «Одноразовый клик мыши».
В нашем программном обеспечении для сбора данных используется эффективная техника сжатия, где она записывает только соответствующие действия перемещения мыши в последовательности перемещения мыши. Это означает, что мы можем восстановить кривую мыши с незначительной ошибкой. На основе информации, предоставленной нашим программным обеспечением для сбора данных, мы можем извлечь множество связанных с траекторией функций для перемещения мыши и действий перетаскивания мышью [12,29,41]. В таблице 9 показаны функции перемещения мыши и перетаскивания, используемые в этом исследовании. Некоторые из этих функций впервые используются в исследовании CA (выделено жирным шрифтом в таблице 9).
Обработка данных
Разделение данных для создания профиля пользователя, алгоритмическая настройка параметров и тестирование производительности системы будут обсуждаться в этом разделе.
6.1. Разделение данных
Мы разделили наши данные на 3 части для каждого биометрического объекта: (1) построить и обучить систему (набор учебных материалов M); (2) настроить параметры алгоритмов, используемых в этом исследовании (набор данных валидации V); и (3) проверить работоспособность системы (тестовый набор данных T). Примерно 35% общих данных использовалось в качестве набора учебных материалов для создания моделей классификаторов или создания шаблонов, 10% от общего числа данных использовалось в качестве набора данных для калибровки параметров алгоритмов, а остальные 55% данных использовались как тестовый набор данных.
Пусть S = [s1,s2,...,sn] - набор данных n биометрических объектов (т. Е. N = 53), и пусть M = [m1,m2,...,mn], V = [v1,v2,...,vn] n и T = [t1,t2,...,tn] представляют собой тренировку, настройку параметров, и набор данных тестирования. На рисунке 8 показано графическое представление этих трех наборов, где mi ≈ 35%, vi ≈ 10% и ti ≈ 55% от всех данных i-го пользователя.

Рисунок 8. Изобразительное представление процесса последующей обработки данных.
Процессы проверки
При оценке производительности системы мы можем использовать различные сценарии. Мы описываем три общих сценария, но возможны вариации. Эти сценарии будут называться «внутренними», «внешними» и «смешанными» по причинам, которые вскоре станут очевидными. Все эти сценарии связаны с использованием инструментов машинного обучения (ML). Мы предполагаем, что для каждого пользователя системы CA мы обучаем двоичный классификатор, который имеет классы «подлинный пользователь» и «пользователь-самозванец». Каждый классификатор обучается с комбинацией подлинных и приносящих данных в равных количествах, чтобы избежать предвзятости. Если используется количество выборок данных, используемых от подлинного пользователя, равное n, а также данные пользователя-жертвователя, то каждый из этих самозваных пользователей будет поставлять приблизительно n / k образцы данных для обучения. Данные для проверки производительности системы для всех этих сценариев (набор данных T (см. Рис.8)) - данные, которые никогда не использовались для обучения и настройки параметров. Мы рассмотрели разное количество самозваных пользователей (т. Е. Разные значения k) для разных сценариев во время тренировки и фазы настройки параметров, которые будут описаны ниже.
Рисунок 9. Представление данных User-1 для VP-1
В случае «внутреннего» сценария мы предполагаем, что система используется внутри организации, где доступны данные всех участников. Можно предположить, что, поскольку данные всех самозванцев используются во время обучения, это будет оказывать положительное влияние на производительность системы. По этой причине также разработаны «внешние» и «смешанные» сценарии. Для «внешнего» сценария мы предполагаем, что на систему могут нападать только люди, у которых нет данных при подготовке классификатора. «Смешанный» сценарий представляет собой комбинацию как «внутреннего», так и «внешнего» сценариев. Подобно «внешнему» сценарию, это классификатор, обученный данными реального пользователя и данными подмножества самозваных пользователей.
Мы выполнили четыре разных процесса проверки:
1. Процесс проверки 1 (VP-1): этот процесс проверки подразумевает, что данные всех участников могут использоваться для обучения классификаторов и корректировки параметров. Если мы предполагаем M участников внутри организации, то каждый классификатор обучается данным одного подлинного пользователя и пользователей-самозвановM-1, то есть все самозванцы были рассмотрены в этом процессе проверки. На рисунке 9 показаны данные, используемые для обучения и проверки для пользователя-1 для этого процесса проверки. Область, отмеченная серым цветом на этом рисунке, используется как для данных обучения M, так и для данных настройки параметров V. Был использован весь объем данных User-1, доступных для обучения, и от пользователей-самозванцев за обучение было получено равное количество данных, т. е.  . Количество данных, взятых у каждого самозваного пользователя, составляет приблизительно
. Количество данных, взятых у каждого самозваного пользователя, составляет приблизительно  . В случае настройки параметров используется весь набор V. Аналогичный подход был принят и для других пользователей.
. В случае настройки параметров используется весь набор V. Аналогичный подход был принят и для других пользователей.
Этот процесс проверки представляет собой внутренний сценарий
2. Процесс проверки 2 (VP-2): В этом случае мы предполагаем, что M1 нарушителей, данные которых используются во время обучения, являются частью организации, которая будет использовать систему CA. Остальные пользователи-самозвацыM2 = M-1-M1 считаются внешними по отношению к организации или добавляются в организацию после этапа обучения, и данные данных этих пользователей не считаются доступными для целей обучения. В качестве альтернативы можно было бы принять крупную организацию, в которой слишком много участников обучают классификатора подлинного пользователя данными всех других участников. В этом процессе проверки тестовые данные поступают от всех участников, т. т. все самозваные пользователи включаются в тестирование. На рисунке 10 показаны данные, используемые для обучения и проверки для пользователя-1 для этого процесса проверки. Как и в VP-1, область, отмеченная серым как для данных обучения M, так и для параметров V настройки параметров, и . Однако число самозваных пользователей, рассматриваемых в этом процессе проверки, будет наполовину, то есть 26. Таким образом, количество данных обучения, полученных от каждого самозваного пользователя, составляет 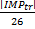 . Аналогичный подход был принят и для других пользователей.
. Аналогичный подход был принят и для других пользователей.
Этот процесс проверки представляет собой смешанный сценарий.
3. Процесс верификации 3 (VP-3): в этом процессе проверки организация стандартизированных данных об импотенте должна быть предоставлена организацией, продающей систему СА, и что каждый пользователь должен обучать классификатор на основе предоставленных данных обучения самозванца и его / ее собственные данные обучения. Этот сценарий можно протестировать, разбив набор самозванцев в 2 набора соответственно пользователей M1 и M2 = M-1-M1. Затем, используя данные мошенников M1, а также данные подлинного пользователя для обучения (опять же, убедившись, что количество образцов подлинных и привитых данных для обучения примерно одинаково), бинарный классификатор может быть обучен. В этом случае, однако, тестирование будет проводиться с использованием данных подлинного пользователя, который не использовался для обучения, и данных оставшихся пользователей-мессетовM2. Эта процедура может повторяться несколько раз для разных разделов набора самозваных пользователей. На рис.11 показаны данные, используемые для обучения и проверки для пользователя-1 для этого процесса проверки. Аналогичный подход был принят и для других пользователей.
Этот процесс проверки представляет собой внешний сценарий.
4. Процесс проверки 4 (VP-4): Помимо трех процессов проверки, которые вводятся до этого, мы также используем новый. В этом процессе проверки мы не используем данные об импотенте во время тренировочной фазы для действий нажатия клавиш и действий мыши и двойного щелчка мыши. Для перемещения мыши и перетаскивания мы придерживались того же подхода, что и VP-1 или VP-2.

training data (М) parameter adjustment data (V)
Рисунок 10. Представление данных пользователя-1 для VP-2.

Рисунок 11. Представление данных User-1 для VP-3
Данные настройки параметров-parameteradjustmentdata
Данныедляобучения-training data
Мы применяли отдельные методы классификации для разных модальностей наряду с различными процессами проверки. Описание этих методов приведено ниже
7.1. Классификация для VP-1, VP-2 и VP-3
Мы используем три разных классификатора в архитектуре MultiClassifierFusion (MCF) для всех различных действий и для VP-1, VP-2 и VP-3. Регрессионными моделями являются искусственная нейронная сеть (ANN) и искусственная нейронная сеть противодействия распространению (CPANN), а модель прогнозирования - VectorVectorMachine (SVM). Мы используем вектор оценки
(f1,f2,f3)=(Scoreann, Scorespann, Scoresvm).
Из этих трех оценок классификатора мы вычисляем общий балл, который используется в модели доверия следующим образом:

где wj - веса для метода взвешенного плавления. Весовые коэффициенты оптимизированы с использованием методов генетического алгоритма (GA).
7.2. Классификация для VP-4
7.2.1. Классификация одного ключа
Мы используем парное масштабированное евклидово расстояние для конкретных ключевых наблюдений для этого процесса проверки. Например, если ключ a имеет n наблюдений в данных обучения, то мы рассчитаем n масштабированных евклидовых расстояний для нового тестового образца a. Используемый нами метрический вектор расстояний теперь (f1,f2,f3)= (средний, минимум, максимум) этих n расстояний. Из этих 3 атрибутов мы вычисляем оценку, которая используется в целевой модели следующим образом: sc=1-(f1-f2)/(f3-f2).
7.2.2. Классическаяклассификацияорграфа
Мы использовали две матрицы расстояний: масштабное евклидово расстояние (SED) и корреляционное расстояние (CD) для конкретных ключевых наблюдений. Например, предположим, что ключевой орграф ab имеет n наблюдений в данных обучения. Теперь мы получаем n масштабированных евклидовых расстояний и n корреляционных расстояний для нового тестового образца орграфа ab. Затем мы берем вектор расстояния как (f1,f2,f3)= (среднее значение SED, минимум SED, максимум CD). Из этого мы вычисляем оценку sc, используемую в модели доверия, следующим образом: sc=(f1 ×f3)/f2.
7.2.3. Однократное нажатие мыши
У нас есть только продолжительность клика как функция. Мы вычисляем попарно масштабированное евклидово расстояние (SED) из всех учебных наблюдений после удаления выбросов с использованием интерквартильного диапазона (IQR). В этом процессе проверки учебный образец (x) был удален из обучающего набора, когда x <(Q1-1,5*IQR) или x> (Q 3+ 1,5 × IQR) 3, где Q1 и Q3 являются первым и третьим квартиль и IQR =Q3-Q1. Затем мы строим вектор расстояния как (f1,f2,f3)= (среднее значение SED, минимум SED, стандартное отклонение SED). Из этого мы вычисляем оценку sc, используемую в модели доверия, следующим образом: sc=wl(f1+f3)+(1-w) × (1 - (f1-f3) / (f2-f3)) где, w - вес для метода взвешенного плавления и оптимизирован с использованием GA. Мы попытались применить тот же метод классификации, что и для SingleKey, но при применении вышеупомянутой методики мы получили лучшие результаты.
7.2.4. Мышь двойной щелчок
Аналогичная методика классификации была применена для двойного щелчка мыши, как для мыши с одним щелчком мыши. Сначала мы применили аналогичную методику классификации, как для SingleKey для этого действия, но это привело к ухудшению производительности.
7.2.5. Перемещениемыши и перетаскивание
Для этих двух действий был принят аналогичный подход классификации для VP-4 в качестве других процессов проверки, то есть VP-1, VP-2 и VP-3.
Выбор функции
Мы использовали все извлеченные функции, описанные в Разделах 5.5 и 5.6 для разных действий, за исключением действий перемещения мыши и перетаскивания. Во время обучения, из-за того, что классификатор смещен в сторону какого-либо одного класса (то есть подлинных или самозваных), мы сначала применяем метод выбора признаков [26] для этих двух типов действий. Подмножество функций, используемое для этих двух типов действий, было создано путем применения наших предлагаемых методов выбора функций, а подмножество функций варьируется для разных пользователей. Описаниеметодоввыбораприменяемыхпризнаковописанониже.
8.1. Методвыбора объекта-1
Подмножество функций основано на Sn>Порога,где

CDF () - это функция кумулятивного распределения, xgn - это n-я особенность настоящего пользователя, а xin - это nth функция imposter. На рисунке 12 показан график эмпирического кумулятивного распределения функций перемещения мыши после выбора функции для пользователя-12.

