 2017-12-16
2017-12-16 1870
1870Основные понятия
Система (от греческого systema — целое, составленное из частей соединение) — это совокупность элементов, взаимодействующих друг с другом, образующих определенную целостность, единство. Приведем некоторые понятия, часто использующиеся для характеристики системы.
Элемент системы — часть системы, имеющая определенное функциональное назначение. Сложные элементы систем, в свою очередь состоящие из более простых взаимосвязанных элементов, часто называют подсистемами.
Организация системы — внутренняя упорядоченность, согласованность взаимодействия элементов системы, проявляющаяся, в частности, в ограничении разнообразия состояний элементов в рамках системы.
Структура системы — состав, порядок и принципы взаимодействия элементов системы, определяющие основные свойства системы. Если отдельные элементы системы разнесены по разным уровням и внутренние связи между элементами организованы только от вышестоящих к нижестоящим уровням и наоборот, то говорят об иерархической структуре системы. Чисто иерархические структуры встречаются практически редко, поэтому, несколько рас ширяя это понятие, под иерархической структурой обычно понимают и такие структуры, где среди прочих связей иерархические связи имеют главенствующее значение.
Архитектура системы — совокупность свойств системы, существенных для пользователя.
Целостность системы — принципиальная несводимость свойств системы к сумме свойств отдельных ее элементов (эмерджентность свойств) и, в то же время, зависимость свойств каждого элемента от его места и функции внутри системы.
Информационная система — взаимосвязанная совокупность средств, методов и персонала, используемых для хранения, обработки и выдачи информации в интересах достижения поставленной цели»
«Информационная система — организационно упорядоченная совокупность документов (массивов документов) и информационных технологий, в том числе с использованием средств вычислительной техники и связи, реализующих информационные процессы»
Классификация
Классификация по масштабу
По масштабу информационные системы подразделяются на следующие группы:
одиночные;
групповые;
корпоративные.
Одиночные информационные системы реализуются, как правило, на автономном персональном компьютере (сеть не используется). Такая система может содержать несколько простых приложений, связанных общим информационным фондом, и рассчитана на работу одного пользователя или группы пользователей, разделяющих по времени одно рабочее место. Подобные приложения создайся с помощью так называемых настольных или локальных систем управления базами данных (СУБД). Среди локальных СУБД наиболее известными являются Clarion, Clipper, FoxPro, Paradox, dBase и Microsoft Access.
Групповые информационные системы ориентированы на коллективное использование информации членами рабочей группы и чаще всего строятся на базе локальной вычислительной сети. При разработке таких приложений используются серверы баз данных (Называемые также SQL-серверами) для рабочих групп. Существует довольно большое количество различных SQL-серверов, как коммерческих, так и свободно распространяемых. Среди них наиболее известны такие серверы баз данных, как Oracle, DB2, Microsoft SQL Server, InterBase, Sybase, Informix.
Корпоративные информационные системы являются развитием систем для рабочих групп, они ориентированы на крупные компании и могут поддерживать территориально разнесенные узлы или сети. В основном они имеют иерархическую структуру из нескольких уровней. Для таких систем характерна архитектура клиент-сервер со специализацией серверов или же многоуровневая архитектура. При разработке таких систем могут использоваться те же серверы баз данных, что и при разработке групповых информационных систем. Однако в крупных информационных системах наибольшее распространение получили серверы Oracle, DB2 и Microsoft SQL Server.
Для групповых и корпоративных систем существенно повышаются требования к надежности функционирования и сохранности данных. Эти свойства обеспечиваются поддержкой целостности данных, ссылок и транзакций в серверах баз.
Классификация по сфере применения
По сфере применения информационные системы обычно подразделяются на четыре группы:
системы обработки транзакций;
системы принятия решений;
информационно-справочные системы;
офисные информационные системы.
Системы обработки транзакций, в свою очередь, по оперативности обработки данных, разделяются на пакетные информационные системы и оперативные информационные системы. В информационных системах организационного управлений преобладает режим оперативной обработки транзакций, для отражения актуального состояния предметной области в любой момент времени, а пакетная обработка занимает весьма ограниченную часть.
Системы поддержки принятия решений — DSS (Decision Support Systeq) — представляют собой другой тип информационных систем, в которых с помощью довольно сложных запросов производится отбор и анализ данных в различных разрезах: временных, географических и по другим показателям.
Обширный класс информационно-справочных систем основан на гипертекстовых документах и мультимедиа. Наибольшее развитие такие информационные системы получили в сети Интернет.
Класс офисных информационных систем нацелен на перевод бумажных документов в электронный вид, автоматизацию делопроизводства и управление документооборотом.
Классификация по способу организации
По способу организации групповые и корпоративные информационные системы подразделяются на следующие классы:
системы на основе архитектуры файл-сервер;
системы на основе архитектуры клиент-сервер;
системы на основе многоуровневой архитектуры;
системы на основе Интернет/интранет - технологий.
В любой информационной системе можно выделить необходимые функциональные компоненты, которые помогают понять ограничения различных архитектур информационных систем.
Архитектура файл-сервер только извлекает данные из файлов так, что дополнительные пользователи и приложения добавляют лишь незначительную нагрузку на центральный процессор. Каждый новый клиент добавляет вычислительную мощность к сети.
Архитектура клиент-сервер предназначена для разрешения проблем файл-серверных приложений путем разделения компонентов приложения и размещения их там, где они будут функционировать наиболее эффективно. Особенностью архитектуры клиент-сервер является использование выделенных серверов баз данных, понимающих запросы на языке структурированных запросов SQL (Structured Query Language) и выполняющих поиск, сортировку и агрегирование информации.
В настоящее время архитектура клиент-сервер получила признание и широкое распространение как способ организации приложений для рабочих групп и информационных систем корпоративного уровня. Подобная организация работы повышает эффективность выполнения приложений за счет использования возможностей сервера БД, разгрузки сети и обеспечения контроля целостности данных.
Многоуровневая архитектура стала развитием архитектуры клиент-сервер и в своей классической форме состоит из трех уровней:
- нижний уровень представляет собой приложения клиентов, имеющие программный интерфейс для вызова приложения на среднем уровне;
- средний уровень представляет собой сервер приложений;
- верхний уровень представляет собой удаленный специализированный сервер базы данных.
Трехуровневая архитектура позволяет еще больше сбалансировать нагрузку на разные узлы и сеть, а также способствует специализации инструментов для разработки приложений и устраняет недостатки двухуровневой модели клиент-сервер.
В развитии технологии Интернет/интранет основной акцент пока что делается на разработке инструментальных программных средств. В то же время наблюдается отсутствие развитых средств разработки приложений, работающих с базами данных. Компромиссным решением для создания удобных и простых в использовании и сопровождении информационных систем, эффективно работающих с базами данных, стало объединение Интернет/интранет-технологии с многоуровневой архитектурой. При этом структура информационного приложения приобретает следующий вид: браузер — сервер приложений — сервер баз данных — сервер динамических страниц — web-сервер.
По характеру хранимой информации БД делятся на фактографические и документальные. Если проводить аналогию с описанными выше примерами информационных хранилищ, то фактографические БД — это картотеки, а документальные — это архивы. В фактографических БД хранится краткая информация в строго определенном формате. В документальных БД — всевозможные документы. Причем это могут быть не только текстовые документы, но и графика, видео и звук (мультимедиа).
ЛЕКЦИЯ 5
Области применения и примеры информационных систем.
По сфере применения АИС различаются следующим образом: административные, производственные, учебные, медицинские, военные, метеорологические, экологические, криминалистические и др. Назначение и структура построения АИС характеризуются наличием соответствующих подсистем. Этот класс АИС является исторически одним из первых на производстве.

АИС на предприятии
АИС различаются также по уровню развития в зависимости от поколений ЭВМ, на которых они базируются.
Информационные технологии — это машинизированные способы обработки, хранения, передачи и использования информации в виде знаний. Они включают два основных элемента — машинный и человеческий (социальный), причем последний выступает главным.
Понятие технологии вообще включает комплекс научных и инженерных знаний, воплощенных в приемах труда, наборах материальных, технических, энергетических, трудовых факторов производства, способов их соединения для создания продукта или услуги, отвечающих определенным требованиям, стандартам. В таком понимании термин технология неразрывно связан с машинизацией производственного или непроизводственного (социального) процесса.
Переход к ИТ как технический базе автоматизированных информационно-управляющих систем обострил проблемы, относящиеся ко всему технологическому циклу сбора, переработки и применения информации в планово-управленческих, познавательных и других процессах, выдвинул на первый план обшие проблемы содержания информационных процессов и значения ИТ. Говорить о воздействии науки на что-либо вне информационного процесса бессмысленно. Научная идея должна превратиться в информацию, т.е. быть закодированной, переданной по каналу связи, принятой адресатом, чтобы ее можно было применить на практике. Чем больше потенциал знаний, тем важнее задача развития информационно-коммуникативных сфер народного хозяйства. Знания должны определенным образом фиксироваться, трансформироваться, распределяться, приниматься и перерабатываться.

Основные этапы технологического процесса в информационных системах
Информационные технологии и выступили новым средством превращения знаний в информационный ресурс (ИР) общества, его новым движущим фактором, стали средством его эффективного использования. Информационный ресурс стал основным ресурсом человечества, главной ценностью современной цивилизации. Но возникли и сложные проблемы, относящиеся к роли, механизму функционирования, социальным последствиям использования ИР.
ЛЕКЦИЯ 6
Понятие данных. Базы данных. Модели представления данных.
АВТОМАТИЗИРОВАННЫЕ БАНКИ ДАННЫХ
 Под автоматизированным банком данных понимается организационно-техническая система, представляющая собой совокупность баз данных пользователей, технических и программных средств формирования и ведения этих баз и коллектива специалистов, обеспечивающих функционирование системы.
Под автоматизированным банком данных понимается организационно-техническая система, представляющая собой совокупность баз данных пользователей, технических и программных средств формирования и ведения этих баз и коллектива специалистов, обеспечивающих функционирование системы.
В самом общем виде основные функции банка данных можно сформулировать следующим образом: адекватное информационное отображение предметной области, обеспечение хранения, обновления и выдачи необходимых данных пользователям. Составными частями любого банка данных являются база данных, система управления базой данных (СУБД), администратор базы данных, прикладное программное обеспечение (рис).
Функционирование системы управления базой данных основано на введении двух уровней организации базы данных — логического и физического. Эти два уровня соответствуют двум аспектам организации данных: физическому с точки зрения хранения данных в памяти ЭВМ и логическому с точки зрения использования данных в прикладных приложениях.
Описание логических организаций баз данных определяет взгляд пользователей на организацию данных в системе, которые отображают состояние некоторой предметной области. Описание логической организации данных иногда называют моделью данных или схемой.
Физическая организацияописывает много различных способов организации данных в запоминающей среде, c помощью которых можно обеспечить соответствие некоторой модели.
База данных — это совокупность хранимых в памяти ЭВМ и специальным образом организованных взаимосвязанных данных, отображающих состояние предметной области. База данных также предназначена для обеспечения информационных нужд определенных пользователей.
Создание единой базы данных о предметной области сложно и в настоящее время практически нереализуемо, хотя бы из-за недостаточного объема памяти современных ЭВМ. На практике большинство баз данных проектируется для ограниченного числа приложений. На одной ЭВМ, как правило, создается несколько различных баз данных. Со временем некоторые базы данных, предназначенные для выполнения родственных функций, могут объединиться, если это будет способствовать повышению производительности всего вычислительного комплекса.
Создание баз данных обеспечивает интеграцию данных и возможность централизованного управления данными.
Объекты и отношения объектов. Любая информационная система должна отображать те или иные стороны окружающего нас реального мира или, как иногда говорят, проблемной или предметной области. Мы воспринимаем окружающий мир состоящим из объектов, которые человек, по совокупности определенных достаточно устойчивых свойств, группирует в наборы (классы) объектов, которым он присваивает имя. Например, в реальном мире есть конкретные собаки, но нет собаки «вообще». Понятие «собаки» описывает целый класс в каком-то смысле однородных реальных объектов.

База данных
Проблемная среда изменяется со временем, что выражается в изменении свойств объектов, возникновении новых и исчезновении старых объектов. Эти изменения происходят в результате событий. Временная последовательность событий образует процесс.
Всякая информационная система имеет дело не с самими объектами, как реальными сущностями, а с их знаковыми отображениями-идентификаторами. Главная функция знака-идентификатора — отличить объект в группе однородных объектов. Идентификатор объекта, вообще говоря, может не нести никакой информации о свойствах объекта или, что то же самое, об его принадлежности к тому или иному классу.
Например, 11591 — «табельный номер служащего» — является числовым идентификатором. Этот идентификатор не описывает свойства, их приходится задавать дополнительно.
Более полно объект описывается записью об объекте, которая обычно состоит из идентификатора объекта-знака, позволяющего отличить один объект от другого среди однородных объектов, и идентификаторов (значений) свойств (атрибутов). Например, запись о служащем некоторой организации имеет табельный номер служащего в качестве идентификатора и такие элементы данных, как должность, заработная плата, льготы и т.д., рассматриваемые как идентификаторы (значения) свойств служащего.
Следует подчеркнуть, что понятие объекта и свойства относительны. Если речь идет о служащем, то естественно понимать должность как свойство служащего. Но если речь идет о должности, например, в смысле должностных инструкций, то уже сама должность выступает в качестве объекта, который может иметь свойства. В частности, в определенном контексте табельный номер служащего может рассматриваться как свойство должности.
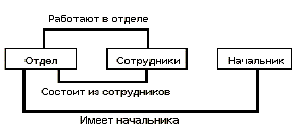
Поэтому при информационном отображении предметных сред (рис) можно (а иногда и нужно) говорить не об объектах и их свойствах, а об отношениях объектов, ибо в этом случае все идентификаторы в записи можно рассматривать симметрично, а не в ориентации на один специально выделенный объект. Как увидим позднее, это соответствует так называемой реляционной точке зрения на базу данных.
При информационном отображении реального мира весьма важно, в каких количественных пропорциях могут осуществляться отношения объектов. Четкое понимание того, к какой категории относится отношение объектов, позволяет сделать заключение о возможном характере связи между соответствующими данными. Фиксация этой стороны при информационном отображении предметной области определяет одну из сторон модели данных. Важно подчеркнуть, что характер отношений одних и тех же объектов не есть нечто застывшее. Оно может измениться и тогда изменится характер связей между элементами данных, который может оказать существенное влияние на структуру банка данных, как логическую, так и физическую. Усложнение характера связей между данными делает более сложными программы их обработки.
Данные. Информация об объекте или отношениях объектов, выраженная в знаковой форме, образует данные. Эти данные могут быть восприняты человеком или каким-либо техническим устройством и соответствующим образом интерпретированы.
Характерной особенностью данных является то, что их можно переводить из одной знаковой системы в другую (перекодировка) без потери информации.
Модели представления данных
ER - модель.
На использовании разновидностей ER-модели основано большинство современных подходов к проектированию баз данных (главным образом, реляционных). Модель была предложена Ченом (Chen) в 1976 г. Моделирование предметной области базируется на использовании графических диаграмм, включающих небольшое число разнородных компонентов. В связи с наглядностью представления концептуальных схем баз данных ER-модели получили широкое распространение в системах CASE, поддерживающих автоматизированное проектирование реляционных баз данных. Основными понятиями ER-модели являются сущность, связь и атрибут.
Сущность - это реальный или представляемый объект, информация о котором должна сохраняться и быть доступна. В диаграммах ER-модели сущность представляется в виде прямоугольника, содержащего имя сущности. При этом имя сущности - это имя типа, а не некоторого конкретного экземпляра этого типа. Для большей выразительности и лучшего понимания имя сущности может сопровождаться примерами конкретных объектов этого типа. Каждый экземпляр сущности должен быть отличим от любого другого экземпляра той же сущности.
Связь - это графически изображаемая ассоциация, устанавливаемая между двумя сущностями. Эта ассоциация всегда является бинарной и может существовать между двумя разными сущностями или между сущностью и ей же самой (рекурсивная связь). В любой связи выделяются два конца (в соответствии с существующей парой связываемых сущностей), на каждом из которых указывается имя конца связи, степень конца связи (сколько экземпляров данной сущности связывается), обязательность связи (т.е. любой ли экземпляр данной сущности должен участвовать в данной связи). Связь представляется в виде линии, связывающей две сущности или ведущей от сущности к ней же самой. При это в месте "стыковки" связи с сущностью используются трех точечный вход в прямоугольник сущности, если для этой сущности в связи могут использоваться много (many) экземпляров сущности, и одноточечный вход, если в связи может участвовать только один экземпляр сущности. Обязательный конец связи изображается сплошной линией, а необязательный - прерывистой линией.
Атрибутом сущности является любая деталь, которая служит для уточнения, идентификации, классификации, числовой характеристики или выражения состояния сущности. Имена атрибутов заносятся в прямоугольник, изображающий сущность, под именем сущности и изображаются малыми буквами, возможно, с примерами.
Типичным представителем (наиболее известным и распространенным) является Information Management System (IMS) фирмы IBM. Первая версия появилась в 1968 г. До сих пор поддерживается много баз данных, что создает существенные проблемы с переходом, как на новую технологию БД, так и на новую технику.
Иерархическая БД состоит из упорядоченного набора деревьев; более точно, из упорядоченного набора нескольких экземпляров одного типа дерева. Тип дерева состоит из одного "корневого" типа записи и упорядоченного набора из нуля или более типов поддеревьев (каждое из которых является некоторым типом дерева). Тип дерева в целом представляет собой иерархически организованный набор типов записи. В IMS использовалась оригинальная и нестандартная терминология: "сегмент" вместо "запись", а под "записью БД" понималось все дерево сегментов.
 Пример типа дерева (схемы иерархической БД):
Пример типа дерева (схемы иерархической БД):
База данных с такой схемой могла бы выглядеть следующим образом (мы показываем один экземпляр дерева):
 |
Все экземпляры данного типа потомка с общим экземпляром типа предка называются близнецами. Для БД определен полный порядок обхода - сверху вниз, слева направо.
1. Найти указанное дерево БД (например, отдел 310);
2. Перейти от одного дерева к другому;
3. Перейти от одной записи к другой внутри дерева (например, от отдела - к первому сотруднику);
4. Перейти от одной записи к другой в порядке обхода иерархии;
5. Вставить новую запись в указанную позицию;
6. Удалить текущую запись.
Ограничения целостности.
Автоматически поддерживается целостность ссылок между предками и потомками. Основное правило: никакой потомок не может существовать без своего родителя. Заметим, что аналогичное поддержание целостности по ссылкам между записями, не входящими в одну иерархию, не поддерживается
В иерархических системах поддерживалась некоторая форма представлений БД на основе ограничения иерархии.
Сетевые системы.
Типичным представителем является Integrated Database Management System (IDMS) компании Cullinet Software, Inc., предназначенная для использования на машинах основного класса фирмы IBM под управлением большинства операционных систем. Архитектура системы основана на предложениях Data Base Task Group (DBTG) Комитета по языкам программирования Conference on Data Systems Languages (CODASYL), организации, ответственной за определение языка программирования Кобол. Отчет DBTG был опубликован в 1971 г., а в 70-х годах появилось несколько систем, среди которых IDMS.
Сетевой подход к организации данных является расширением иерархического. В иерархических структурах запись-потомок должна иметь в точности одного предка; в сетевой структуре данных потомок может иметь любое число предков. Сетевая БД состоит из набора записей и набора связей между этими записями, а если говорить более точно, из набора экземпляров каждого типа из заданного в схеме БД набора типов записи и набора экземпляров каждого типа из заданного набора типов связи. Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка P и типом записи потомка C должны выполняться следующие два условия:
1. Каждый экземпляр типа P является предком только в одном экземпляре L;
2. Каждый экземпляр C является потомком не более, чем в одном экземпляре L.
На формирование типов связи не накладываются особые ограничения; но возможны, например, следующие ситуации:
1. Тип записи потомка в одном типе связи L1 может быть типом записи предка в другом типе связи L2 (как в иерархии).
2. Данный тип записи P может быть типом записи предка в любом числе типов связи.
3. Данный тип записи P может быть типом записи потомка в любом числе типов связи.
4. Может существовать любое число типов связи с одним и тем же типом записи предка и одним и тем же типом записи потомка; и если L1 и L2 - два типа связи с одним и тем же типом записи предка P и одним и тем же типом записи потомка C, то правила, по которым образуется родство, в разных связях могут различаться.
5. Типы записи X и Y могут быть предком и потомком в одной связи и потомком и предком - в другой.
6.  Предок и потомок могут быть одного типа записи.
Предок и потомок могут быть одного типа записи.
Пример:
1. Найти конкретную запись в наборе однотипных записей (инженера Сидорова);
2. Перейти от предка к первому потомку по некоторой связи (к первому сотруднику отдела 310);
3. Перейти к следующему потомку в некоторой связи (от Сидорова к Иванову);
4. Перейти от потомка к предку по некоторой связи (найти отдел Сидорова);
5. Создать новую запись;
6. Уничтожить запись;
7. Модифицировать запись;
8. Включить в связь;
9. Исключить из связи;
10. Переставить в другую связь и т.д.
Ограничения целостности.
В принципе их поддержание не требуется, но иногда требуют целостности по ссылкам (как в иерархической модели).
ЛЕКЦИЯ 7
Базовое понятие реляционной модели данных: отношение, атрибут, картеж, домен, ключ, тип данных.
Для создания и обслуживания систем баз данных используется специализированное программное обеспечение - системы управления базами данных СУБД.
Можно считать, что если прикладная информационная система опирается на некоторую систему управления данными, обладающую этими свойствами, то эта система управления данными является системой управления базами данных (СУБД).
1. К основным функциям СУБД любого типа можно отнести:
2. создание (конструирование) базы данных путем описания структуры хранимой информации и взаимосвязей между ее частями;
3. занесение, хранение и удаление информации из базы данных - т. е. поддержание БД в актуальном состоянии;
4. обслуживание выборок и запросов пользователей
5. Непосредственное управление данными во внешней памяти. Эта функция включает обеспечение необходимых структур внешней памяти как для хранения данных, непосредственно входящих в БД, так и для служебных целей, например, для убыстрения доступа к данным в некоторых случаях (обычно для этого используются индексы).
6. Управление буферами оперативной памяти. СУБД обычно работают с БД значительного размера; по крайней мере этот размер обычно существенно больше доступного объема оперативной памяти. Понятно, что если при обращении к любому элементу данных будет производиться обмен с внешней памятью, то вся система будет работать со скоростью устройства внешней памяти. Практически единственным способом реального увеличения этой скорости является буферизация данных в оперативной памяти. Поэтому в развитых СУБД поддерживается собственный набор буферов оперативной памяти с собственной дисциплиной замены буферов.
7. Управление транзакциями. Транзакция - это последовательность операций над БД, рассматриваемых СУБД как единое целое. Либо транзакция успешно выполняется, и СУБД фиксирует (COMMIT) изменения БД, произведенные этой транзакцией, во внешней памяти, либо ни одно из этих изменений никак не отражается на состоянии БД. Понятие транзакции необходимо для поддержания логической целостности БД.
8. Журнализация. Одним из основных требований к СУБД является надежность хранения данных во внешней памяти. Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя. Обычно рассматриваются два возможных вида аппаратных сбоев: так называемые мягкие сбои, которые можно трактовать как внезапную остановку работы компьютера (например, аварийное выключение питания), и жесткие сбои, характеризуемые потерей информации на носителях внешней памяти. Поддержание надежности хранения данных в БД требует избыточности хранения данных, причем та часть данных, которая используется для восстановления, должна храниться особо надежно. Наиболее распространенным методом поддержания такой избыточной информации является ведение журнала изменений БД. Журнал - это особая часть БД, недоступная пользователям СУБД и поддерживаемая с особой тщательностью (иногда поддерживаются две копии журнала, располагаемые на разных физических дисках), в которую поступают записи обо всех изменениях основной части БД. Во всех случаях придерживаются стратегии "упреждающей" записи в журнал (так называемого протокола Write Ahead Log - WAL). Самая простая ситуация восстановления - индивидуальный откат транзакции.
9. Поддержка языков БД. Для работы с базами данных используются специальные языки, в целом называемые языками баз данных. В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная от ее создания, и обеспечивающий базовый пользовательский интерфейс с базами данных. Стандартным языком наиболее распространенных в настоящее время реляционных СУБД является язык SQL (Structured Query Language).
Различные СУБД позволяют создавать и обслуживать базы данных различной структуры: иерархические, сетевые и т. д. Наибольшее распространение получили так называемые реляционные БД. Реляционные базы данных представляют собой набор связанных таблиц и ничего кроме них. Термин «реляционная» указывает на то, что между таблицами базы данных могут быть установлены различные отношения. РСУБД составляют один из крупных сегментов рынка баз данных: они включают все от систем клиент/сервер до настольных систем.
Основные понятия РСУБД.
Поле – базовый элемент любой базы данных, не обязательно реляционной. Поля это элементарный информационный объект базы данных. В данном случае, «элементарный», означает, что поле не может быть разбито на более мелкие порции информации. Кроме того, в каждом поле может храниться только строго определенный тип информации (текстовые поля, поля типа дата/время, числовые поля и т. п.). Большинство СУБД поддерживают возможность создания полей следующих типов:
- текстовые (для хранения строк размером до 255 символов);
- числовые (целочисленное, с плавающей точкой и т. п.);
- memo поля – поля для хранения тестовых фрагментов любого размера;
- дата/время – поля, в которых могут храниться даты и (или) время в национальном формате;
- логические – поля для хранения утверждений типа ДА/НЕТ, ВКЛЮЧЕНО/ВЫКЛЮЧЕНО, ИСТИНА/ЛОЖЬ и т. п.;
Кроме перечисленных типов современные СУБД позволяют создавать поля для хранения гиперссылок, объектов OLE или ссылок на них и т. п.
Запись (картеж) – набор данных специфицирующих некоторый объект. Например в БД автотранспортных средств каждая запись содержит сведения о транспортном средстве (госномер, марку, год выпуска, № кузова и т. п.). Каждая запись БД содержит уникальный набор информации – в нашем примере, каждая запись представляет данные о конкретном транспортном средстве. В РСУБД записи не хранятся в каком либо порядке набора. Иными словами в концепции РСУБД вообще не существует номера записи, как в системах другого типа.
Таблица – это набор полей. Данные, содержащиеся в таблице, хранятся в виде записей. Каждая таблица базы данных представляет некоторый тип хранящихся в ней объектов. В БД может быть любое количество таблиц, между которыми могут быть установлены различные отношения. Тот факт, что таблица представляет только один тип объекта, отнюдь не является недостатком. Наоборот, это один из ключей к созданию эффективной базы данных.
Ключевое поле – это поле, которое используется для связи между двумя и более таблицами. Ключи – это поля, которые являются общими для связываемых таблиц. При этом значение этих полей в связанных таблицах дублируется. Ключи могут быть первичными, внешними или составными. Позже мы рассмотрим эти типы ключей.
Отношение – это связь, устанавливаемая между двумя и более таблицами посредством ключевого поля. Принципиально возможны три типа отношений: один-к-одному, один-к-многим и многие-к-многим.
Соединение – виртуальная таблица, создаваемая, когда пользователь запрашивает информацию из различных таблиц связанных отношением. Ключевые поля в этом случае используются для поиска соответствующих записей в различных таблицах, из которых формируется соединение.
Домен. Понятие домена более специфично для баз данных, хотя и имеет некоторые аналогии с подтипами в некоторых языках программирования. В самом общем виде домен определяется заданием некоторого базового типа данных, к которому относятся элементы домена, и произвольного логического выражения, применяемого к элементу типа данных. Если вычисление этого логического выражения дает результат "истина", то элемент данных является элементом домена. Наиболее правильной интуитивной трактовкой понятия домена является понимание домена как допустимого потенциального множества значений данного типа.
Первичный ключ – уникально идентифицирует каждую запись в таблице и не имеет повторяющихся значений. Выбор поля в качестве первичного ключа – одно из важнейших решений принимаемых при проектировании БД.
Если запись в таблице не может быть однозначно идентифицирована каким-либо одним полем, то можно использовать составной ключ – группу полей. Составные ключи используются значительно реже первичных.
Внешний ключ – это поле (или группа полей) одной таблицы, для которого имеется дублированное значение в другой, связанной таблице. В отличие от первичных ключей, внешние ключи зачастую многократно повторяются при установлении отношения один-к-многим.
Для более наглядного представления о СУБД реляционного типа попытаемся спроектировать БД в которой будут хранится сведения о студентах нашего учебного заведения. При проектировании нам необходимо заложить концепцию наращиваемости БД так, чтобы в одной и той же базе хранились паспортные данные (эта часть БД может использоваться ОК), данные об успеваемости (учебный отдел), поощрения и взыскания (воспитательная часть), бухгалтерские сведения и т. п. Концепция РСУБД позволяет без особых затруднений решить эту проблему.
Для начала создадим основную таблицу со следующими полями:
| Имя поля | Тип данных | Примечание |
| Фамилия | Текст (25) | |
| Имя | Текст (20) | |
| Отчество | Текст (20) | |
| Дата рождения | Дата/время | |
| Зачетная книжка | Текст (7) | Ключ |
Здесь в качестве первичного ключа выбрано поле [Зачетная книжка] поскольку значение этого поля однозначно идентифицирует интересующий нас объект – стукдента. Для БД ОК можно было бы ввести ключевое поле личный номер. Если выбор ключа затруднителен, можно использовать составное поле или, что делается чаще – вводится дополнительное поле-идентификатор.
Фрагмент заполненной таблицы с такими полями может выглядеть следующим образом:
| Зачетная книжка | Фамилия | Имя | Отчество | Дата рождения |
| 98/1111 | Иванов | Иван | Иванович | 01.01.78 |
| 98/1112 | Петров | Петр | Петрович | 10.10.78 |
| 98/1113 | Козлов | Иван | Петрович | 12.12.78 |
Любая РСУБД позволяет вносить данные в такую таблицу, редактировать их, удалять и т. п. Кроме того, вы можете поручить системе отсортировать записи в нужном порядке или произвести выборку в соответствии с запросом.
Конечно, информации, которая может быть сохранена в такой таблице явно не достаточно для целей, поставленных при проектировании БД.
ЛЕКЦИЯ 8
Базовое понятие реляционной модели данных. Нормализация отношений
Приведение модели к требуемому уровню нормальной формы является основой построения оптимальной реляционной БД.
В процессе нормализации элементы данных разделяются и группируются в дополнительные таблицы, представляющие дополнительные объекты и их взаимосвязи. Теория нормализации основана на том, что определённый набор таблиц, называемый нормализованным, обладает лучшими свойствами при таких операциях с БД как внесение, модификация; и удаление данных, по сравнению с другими возможными наборами таблиц, с помощью которых могут быть представлены те же данные.
Введение нормализации таблиц при разработке информационной модели обеспечивает минимальный объём физической, то есть записанной на каком-либо носителе БД и её максимальное быстродействие, что непосредственно отражается на качестве функционирования информационной системы. Нормализация информационной модели выполняется в несколько этапов.
Этапы нормализации:
1. Если данные о предметной области занести в одну двумерную таблицу, то такая таблица будет представлять собой первую нормальную форму реляционной модели данных.
Первый этап нормализации заключается в образовании двумерной таблицы, содержащей все необходимые атрибуты информационной модели, и в выделении ключевых атрибутов. Очевидно, что полученная весьма внушительная таблица будет содержать очень разнородную информацию о предметной области. В этом случае при работе с такой таблицей будут наблюдаться аномалии в производительности БД, например, при включении, обновлении и удалении из неё разных данных.
Это объясняется тем, что при выполнении таких действий над одними данными приходится уделять внимание другим данным (вводить или заботиться о том, чтобы они не были стёрты), которые не имеют к текущим действиям никакого отношения.
2. Если каждый атрибут таблицы не являющийся её первичным ключом, полностью зависит от уникального ключа только этой таблицы, то есть принадлежит только этой таблице, то такая таблица задана во второй нормальной форме.
Для того, чтобы таблица была задана во второй нормальной форме достаточно, чтобы её уникальный и все первичные ключи содержали по одному атрибуту (полю). В этом случае все атрибуты, не являющиеся первичными, полностью зависят от одного уникального ключа этой таблицы.
Если уникальный и первичные ключи таблицы состоят более чем из одного атрибута, то она может и не быть таблицей во второй нормальной форме, так как может содержать несколько доменов. Такая таблица приводится ко второй нормальной форме разбиением исходной таблицы на несколько, каждая из которых содержит по одному атрибуту, тогда все её атрибуты будут иметь полную функциональную зависимость от уникального ключа соответствующей выделенной таблицы.
Таким образом, в процессе приведения модели ко второй нормальной форме в основном исключаются аномалии дублирования данных.
3. Если каждый атрибут таблицы, не являющийся первичным ключом, не транзитивно зависит от её уникального ключа, то такая таблица задана в третьей нормальной форме.
Транзитивная зависимость возникает при дублировании данных в одной таблице. Если А, В, С - три атрибута одной таблицы и С зависит от В, а В от А, то говорят, что С транзитивно зависит от А, как это схематично показано на рис.19,а (где:.А - уникальный ключ таблицы).

Схема транзитивной зависимости:
а) связи между объектами с транзитивной зависимостью;
б) связи между объектами без транзитивной зависимости
Например, если все данные о моделях автомобилей и самих автомобилях хранятся в одной таблице, то для нескольких моделей одного автомобиля пришлось бы многократно указывать тип кузова, количество дверей и другие технические характеристики. В этом случае технические характеристики зависят от автомобиля и при наличии нескольких моделей этого автомобиля технические характеристики дублируются в каждой модели автомобиля
Дублирование исчезает, если такую таблицу разбить на две: в одной хранить данные об автомобилях, а в другой — данные о моделях, которыми модели одного автомобиля отличаются друг от друга. Существуют и более высокие формы нормализации, но они используются редко и здесь рассматриваться не будут
Правила нормализации логической модели:
Для построения оптимальной (нормализованной) логической модели:
1. Необходимо исключать повторяющиеся группы атрибутов для каждого набора связанных атрибутов (доменов) следует создавать отдельную таблицу и снабжать её уникальным ключом.
Выполнение этого правила автоматически приведёт ко второй нормальной форме. Помимо теоретического в этом правиле есть и чисто практический смысл – повышение производительности и надёжности БД.
2. Необходимо исключать из таблиц избыточные данные - если атрибут зависит только от части составного ключа, то его следует переместить в отдельную таблицу и присвоить ей уникальный ключ.
Это правило помогает избежать потери одних данных при удалении каких-либо других.
3. В случаях, когда это возможно, следует использовать идентификаторы вместо описательных атрибутов, создавая для них отдельную таблицу идентификаторов.
4. Необходимо исключать из таблиц столбцы, которые не зависят от ключа - то есть если атрибуты не вносят свою лепту в описание ключа, то их следует переместить в отдельную таблицу.
В основном изменения в логической модели связаны с введением дополнительных атрибутов, которые выделены в отдельные таблицы, а в исходной таблице присутствуют только первичные коды этих выделенных таблиц.
При проектировании логической модели необходимо должное внимание уделять выбору уникального и первичных ключей таблиц. Обычно различают естественные и искусственные атрибуты. Под естественным атрибутом, обычно, понимают название или имя, а под искусственным цифровой код (табельный номер).
Укажем, в каких случаях рекомендуется вместо естественного ключевого атрибута использовать искусственный, то есть цифровой код:
1. Естественный атрибут таблицы не обладает свойством уникальности. Например, среди сотрудников фирмы могут быть однофамильцы или даже полные тёзки. В этом случае решить проблему помогает уникальный табельный номер (код).
2. Таблица участвует во многих связях, тогда для отображения таких связей создаётся несколько идентификационных таблиц, в каждой из которых повторяется идентификатор исходной таблицы. Для того чтобы не использовать во всех таблицах длинный естественный атрибут, следует использовать вместо него более короткий цифровой код. Такая замена будет способствовать повышению быстродействия всей системы.
3. Естественный атрибут может изменяться во времени (например, фамилия женщины) - это может привести к большим трудностям при эксплуатации системы. Использование же в этом случае неизменного кода (табельного номера) позволит избежать этих сложностей.
Нормализация баз данных
В сущности, нормализация баз данных представляет собой процесс оптимизации хранения и использования информации в таблицах. Е.Ф. Кода (Е. F. Codd), служащий IBM, впервые предложил процесс нормализации в 1972 г. (Normalized Data Structure: A Brief Tutoric 1971г. и Relational Completeness of Data Base Sublanguages, 1972). Кодд предложил взять схему отношений (relational schema) (систему взаимодействующих между собой таблиц) и провести серию тестов для определения ее принадлежности к определенной нормальной форме (normal form). Первоначально он предложил три нормальных формы, так называемые первая, вторая и третья нормальная форма. Позже Е.Ф. Кодд и мистер Бойс (Мг. Воусе) создали боле точное определение, известное как нормальная форма Бойса-Кодда (Boyce-Codd normal form -BCNF). Затем они разработали четвертую и пятую нормальную форму, которые основаны на менее четких концепциях зависимостей (многозначность и объединение).
Просто следует запомнить, что данные "нормальные формы" основаны на функциональных зависимостях полей таблицы и их взаимодействии с другими таблицами системы баз данных. При нормализации гарантируется сохранение и использование содержащейся в таблицах информации наиболее эффективным способом.
Приведение к третьей нормальной форме
Для выполнения нормализации необходимо разделить все таблицы на уже используемые проекте группы. После этого следует отдельно рассмотреть каждую таблицу и определить, можно ли оптимизировать ее еще лучше. Для этого применяют процесс, известный как приведение к третьей нормальной форме (3NF). Данная операция состоит из трех этапов.
Довольно часто программист выполняет описанные ниже действия уже после создания всех полей таблиц.
Существуют две причины, по которым следует создавать таблицы в соответствии с третьей нормальной формой.
Ø Устранение избыточности данных. Повторное внесение данных вручную влечет за собой две проблемы. Во-первых, для этого используется больше места и ресурсов, чем необходимо. Во-вторых, при повторном вводе информации существует вероятность возникновения опечаток.
Ø Непредвиденные проблемы масштабирования. Как правило, после создания базы данных "разрастаются" и в некоторой степени "живут собственной жизнью". Если не нормализовать таблицы, то при необходимости добавить дополнительные поля вы рискуете столкнуться с серьезными трудностями. Например, в системе имеются два поля телефонных номеров (один — домашний, другой — рабочий). Допустим, через некоторое время необходимо внести в базу данных также поле номера сотового телефона и, возможно, поле номера пейджера. Для размещения новой информации следует возвратиться и изменить структуру, что в лучшем случае является громоздкой операцией. А может быть и иначе; например, представим себе студенческую систему, согласно которой каждый студент изучает пять предметов, однако решением администрации количество предметов сокращается до трех. Система должна быть такой, чтобы ее можно было быстро изменить согласно введенным установкам.
Подобных проблем можно легко избежать, используя для формирования таблиц три ocновных этапа приведения к третьей нормальной форме.
Первая нормальная форма (1NF)
Процесс приведения таблицы к первой нормальной форме относительно прост. Первым делом устраняются все повторяющиеся группы данных — их помещают в свои собственные таблицы.
Соответствующий практический совет, которому необходимо следовать.
Устраните повторяющиеся группы, т.е. создайте специальную таблицу для повторяющихся полей и переместите их туда.
Важным моментом в процессе приведения к первой нормальной форме является назначение каждой таблице первичного ключа — индекса, созданного из одного или более полей в таблице, который обеспечивает уникальность каждой записи.
Вторая нормальная форма (2NF)
Для приведения таблицы ко второй нормальной форме требуется немного больше усилий. Вторая нормальная форма подразумевает, что в каждой таблице должен быть определен первичный ключ.
Устраните избыточные данные. Любое поле в таблице, которое является избыточным или всегда остается неизменным, основанным на значении другого поля, необходимо переместить в отдельную таблицу.
Третья нормальная форма (3NF)
Заключительный этап в модели третьей нормальной формы является немного более трудным. Третья нормальная форма подразумевает, что все поля каждой таблицы непосредственно связаны с полем первичного ключа и не зависят от других полей.
Устраните все столбцы (поля), не зависящие от ключа, т.е. любое поле в таблице, непосредственно не связанное с полем первичного ключа, необходимо переместить в отдельную таблицу.
При разработке таблиц необходимо изначально следовать третьей нормальной форме, повышая таким образом точность и работоспособность системы.
ЛЕКЦИЯ 9
Проектирование реляционных баз данных
ТЕОРЕТИЧЕСКИЕ ОСНОВЫ ПРОЕКТИРОВАНИЯ БАЗ ДАННЫХ
Прежде всего, приступая к проектированию БД для конкретной предметной области, необходимо осмыслить задачу, поставленную перед Вами Заказчиком.
Всю эту информацию следует привести к виду наиболее удобному для создания БД. Причём для построения оптимальной базы данных требуется наиболее правильно организовать хранение и доступ к данным БД.
Для достижения этой цели, прежде всего, необходимо построить информационную модель предметной области таким образом, чтобы она наиболее полно отражала структуру и взаимосвязи на вашем предприятии. Такая модель и будет в дальнейшем положена в основу системы автоматизированной обработки данных.
СТРУКТУРА ИНФОРМАЦИОННОЙ МОДЕЛИ ПРЕДМЕТНОЙ ОБЛАСТИ
Процесс создания информационной модели начинается с определения концептуальных требований будущих пользователей БД, которыми могут быть различные подразделения предприятия и его дирекция. На рис. 1 представлена структура информационной модели некоторой предметной области.

Рис. 1. Структурная схема информационной модели
Требования отдельных пользователей интегрируются в едином «обобщением представлении», которое называют концептуальной моделью данной предметной области. Концептуальная модель отображает предметную область в виде взаимосвязанных объектов без указания способов их физического хранения.
Проектирование концептуальной модели предприятия основано на анализе решаемых на этом предприятии задач по обработке данных. При этом усилия разработчика должны быть направлены в основном на структуризацию данных, принадлежащих будущим пользователям БД и выявление взаимосвязей между ними.
Таким образом, концептуальная модель включает описания объектов и их взаимосвязей, выявляемых в результате анализа данных, используемых данным предприятием. Пользователи, для которых создаётся БД, могут либо уже иметь прикладные программы с помощью которых они будут обслуживаться базой данных, либо такие прикладные программы пользователей должны быть созданы.
Возможно, что отражённые в концептуальной модели взаимосвязи между объектами окажутся впоследствии нереализуемыми средствами выбранной СУБД. Это потребует изменения концептуальной модели. Версия концептуальной модели, которая может быть реализована конкретной СУБД, называется логической моделью.
Логическая модель отражает логические связи между атрибутами объектов вне зависимости от их содержания и среды хранения и может быть реляционной, иерархической или сетевой.
Различным пользователям в информационной модели соответствуют различные подмножества её логической модели, которые называются внешними моделями пользователей. Таким образом, внешняя модель пользователя представляет собой отображение концептуальных требований этого пользователя в логической модели и соответствует тем представлениям, которые пользователь получает о предметной области на основе логической модели. Следовательно, насколько хорошо спроектирована внешняя модель, настолько полно и точно информационная модель отображает предметную область и настолько полно и точно работает автоматизированная система управления этой предметной областью.
Подчеркнём различия между концептуальной и логической моделями.
Концептуальная модель представляет интегрированные концептуальные требований всех пользователей к базе данных данной предметной области.
Логическая модель отображает логические связи между информационными данными в данной концептуальной модели.
Логическая модель отображается в физическую память, которая может быть построена на электронных, магнитных, оптических, биологических или других принципах.
Внутренняя модель предметной области определяет размещение данных, методы доступа и технику индексирования в данной логической модели и иначе называется физической моделью.
Информационные данные любого пользователя в БД должны быть независимы от всех других пользователей. Однако, так как информационная модель рассчитана на развитие концептуальной модели, то вносимые в неё изменения не должны оказывать влияния на существующие внешние модели. Это первый уровень независимости данных. С другой стороны внешние модели пользователей никак не связаны с типом физической памяти, в которой будут храниться данные, и с физическими методами доступа к этим данным. Это положение отражает второй уровень независимости данных.
Минимизация влияния изменений в одной прикладной программе пользователя на другие прикладные программы как того же, так и других пользователей достигается всесторонним анализом объектов и их взаимосвязей в предметной области. При этом степень независимости данных определяется тщательностью проектирования базы данных.
ТИПЫ ИНФОРМАЦИОННЫХ МОДЕЛЕЙ
В настоящее время различают в основном три типа информационных моделей: иерархическую, сетевую и реляционную.
Иерархическая и сетевая модели данных стали применяться в системах управления данных в начале 60-х годов. В начале 70-х годов была предложена реляционная модель данных, которая предназначалась для создания БД на основе ПК.
Эти три модели различаются в основном способами информационного отображения объектов и их взаимосвязей.
Иерархическая модель данных строится по принципу иерархии типов объектов. В этой модели один тип объектов, находящихся на одном её уровне является главным, а остальные, находящиеся на низших уровнях иерархии - подчинёнными (рис.2).
Для данного главного типа объекта может существовать несколько подчинённых типов объектов. При этом для каждого экземпляра главного объекта может быть несколько экземпляров подчинённых объектов.
В иерархической информационной модели объект представляется узлом, содержащем совокупность его атрибутов. Наивысший в иерархии узел, располагается на первом уровне модели, называется корневым.
ПОСТРОЕНИЕ ИНФОРМАЦИОННОЙ МОДЕЛИ ПРЕДМЕТНОЙ ОБЛАСТИ
Все тонкости построения информационной модели преследуют одну - единственную цель - получить хорошую базу данных.
А что это такое?
База данных - это большое по объёму хранилище, в которое предприятие помещает все используемые на нём информационные данные и из которого различные пользователи их могут получать, используя различные приложения.
Такая единая база данных представляется идеальной для всех структурных подразделений предприятия, хотя на практике это решение по различным причинам труднодостижимо.
В основу проектирования БД должны быть положены представления конечных пользователей конкретной организации - концептуальные требования к системе. Именно конечный пользователь в своей работе принимает решения с учётом информации, получаемой в результате доступа к базе данных. От оперативности и качества этой
информации будет зависеть эффективность работы организации. Данные, помещаемые в базу данных, также представляет конечный пользователь.
При рассмотрении требований конечных пользователей необходимо принимать во внимание следующее:
1. БД должна удовлетворять актуальным информационным потребностям предприятия. А это значит, что организация информационных данных в БД должна по структуре и содержанию соответствовать решаемым на предприятии задачам.
2. БД должна обеспечивать получение требуемых данных за приемлемое время, то есть обеспечивать заданную производительность.
3. БД должна быть рассчитана на возможность удовлетворения вновь возникающих требований конечных пользователей.
4. База данных должна быть рассчитана на возможность расширения при реорганизации и расширении предметной области.
5. БД должна легко изменяться при изменении программной и аппаратной среды.
6. Загруженные в БД корректные данные должны оставаться корректными.
7. Данные до включения в БД должны проверяться на достоверность.
8. Доступ к данным, размещаемым в БД, должны иметь только лица с соответствующими полномочиями.
Этапы проектирования базы данных с учётом рассмотренных выше аспектов представлены на рис.2.
В результате анализа поставленной заказчиком задачи и обработки требований конечных пользователей составляется концептуальная модель.
При разработке логической модели базы данных, прежде всего, необходимо решить, какая модель данных наиболее подходит для отображения конкретной концептуальной модели предметной области. В настоящее время коммерческие автоматизированные системы управления предприятиями используют в основном одну из рассмотренных выше моделей организации данных или их комбинацию.
Переход от концептуальной к логической модели данных производится следующим образом: каждый объект концептуальной модели в логической модели представляется таблицей, содержащей его атрибуты, которые в удобной для пользователя форме отображается визуальными средствами ПК, например, на экране дисплея.
Ниже представлены этапы проектирования БД, которые должны обеспечить необходимую независимость данных и оптимальное выполнение эксплуатационных требований пользователей.

Рис. 2. Этапы проектирования БД
Физическое описание модели
На этапе физического проектирования БД осуществляется ввод конкретных информационных данных всех конечных пользователей в соответствующие таблицы, форма которых была создана на этапе проектирования логической модели. При этом необходимо обеспечить безошибочность и точность занесения, хранения и выборки информационных данных из БД. Это называется обеспечением целостности базы данных.
Система мер, направленных на поддержание правильности данных в базе в любой момент времени.
Правильность информационных данных вводимых в БД для хранения может быть нарушена, например, из-за программных ошибок, сбоях и неправильном вводе данных оператора. При этом ошибки в данных остаются незамеченными до тех пор, пока не приведут к тяжелым последствиям, поэтому необходимо принимать меры для наиболее раннего обнаружения их. Такие меры лучше всего принять на стадии вводе данных в БД.
Для контроля достоверности ввода данных часто практикуют параллельный ввод одних и тех же данных несколькими операторами. Вероятность совершения одной и той же ошибки в этом случае крайне мала и при простом сравнении результатов ввода различных операторов можно получить безошибочные данные, например, методом голосования.
В СУБД целостность данных обеспечивается целым рядом специальных мер, называемых ограничениями целостности.
Ограничения целостности - это набор определённых правил, которые устанавливают пределы допустимых значений данных и связей между ними.
Ограничения целостности в большинстве случаев определяются особенностями предметной области.
Ограничения целостности могут относиться к разным объектам БД: атрибутам (полям), записям, таблицам, связям между ними и т.п.
Пределы допустимых значений данных для полей таблицы могут быть заданы следующим образом:
1. Типом и форматом поля можно автоматически ограничить длину записываемого в него слова, так как все буквы алфавита представляются цифровым кодом одной и той же длины.
2. Длиной поля можно автоматически задать диапазон значений чисел, которые могут быть занесены в данное поле. Причём дополнительными числовыми ограничениями сверху, снизу или с обеих сторон можно дополнительно ограничить этот диапазон.
3. Недопустимостью пустого поля в БД, «ничейных» записей, в которых пропущены какие-либо атрибуты.
4. Заданием списка допустимых значений атрибута можно избежать излишнего разнообразия данных. Например, для указания типа кузова мы можем ограничить фантазию пользователя только общепринятыми названиями: седан, кабриолет и т.д.
5. Проверка на уникальность значения поля позволяет избежать записей – дубликатов.
ЛЕКЦИЯ 10
Функциональные возможности СУБД. Характеристики СУБД, их обзор.
Обзор СУБД
Системой управления базами данных называют программную систему, предназначенную для создания на ЭВМ общей базы данных, используемой для решения множества задач. Подобные системы служат для поддержания базы данных в актуальном состоянии и обеспечивают эффективный доступ пользователей к содержащимся в ней данным в рамках предоставленных пользователям полномочий.
СУБД предназначена для централизованного управления базой данных в интересах всех работающих в этой системе.
По степени универсальности различают два класса СУБД:
· системы общего назначения;
· специализированные системы.
СУБД общего назначения не ориентированы на какую-либо предметную область или на информационные потребности какой-либо группы пользователей. Каждая система такого рода реализуется как программный продукт, способный функционировать на некоторой модели ЭВМ в определенной операционной системе и поставляется многим пользователям как коммерческое изделие. Такие СУБД обладают средствами настройки на работу с конкретной базой данных. Использование СУБД общего назначения в качестве инструментального средства для создания автоматизированных информационных систем, основанных на технологии баз данных, позволяет существенно сокращать сроки разработки, экономить трудовые ресурсы. Этим СУБД присущи развитые функциональные возможности и даже определенная функциональная избыточность.
Специализированные СУБД создаются в редких случаях при невозможности или нецелесообразности использования СУБД общего назначения.
СУБД общего назначения — это сложные программные комплексы, предназначенные для выполнения всей совокупности функций, связанных с созданием и эксплуатацией базы данных информационной системы.
Рынок программного обеспечения ПК

