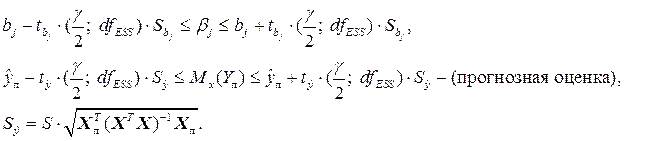2014-02-01
2014-02-01 1437
14374.1. Матричная форма регрессионной модели
Экономическое явление определяется большим числом одновременно и совокупно действующих факторов. Модель множественной регрессии запишется так:
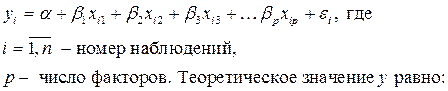
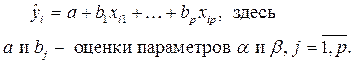
Модель линейной множественной регрессии можно записать в матричной форме, имея в виду, что коэффициенты α и β заменены их оценками.
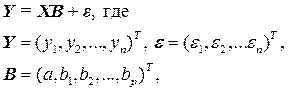
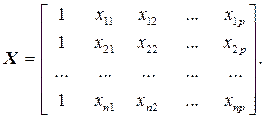
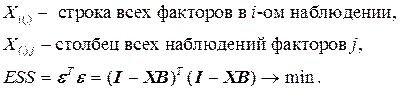
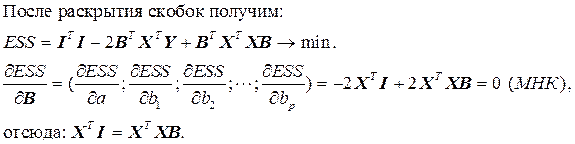
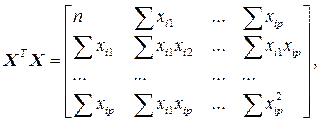
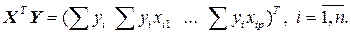
Матрица X T X – неособенная и её ранг равен её размеру, то есть (р +1).
4.2. Отбор факторов для моделей множественной регрессии
Факторы, включаемые в модель, должны существенным образом объяснить вариацию результативной переменной.
Существует ряд способов отбора факторов, наибольшее распространение из которых имеют метод короткой регрессии и метод длинной регрессии.
При использовании метода короткой регрессии в начале в модель включают только наиболее важные факторы с экономически содержательной точки зрения.
С этим набором факторов строится модель и для неё определяются показатели качества ESS, R 2, F, ta, tbj. Затем в модель добавляется следующий фактор и вновь строится модель. Проводится анализ, улучшилась или ухудшилась модель по совокупности критериев. При этом возможно появление парето – оптимальных альтернатив.
Метод длинной регрессии предполагает первоначальное включение в модель всех подозрительных на существенность факторов. Затем какой-либо фактор исключают из модели и анализируют изменение её качества. Если качество улучшится, фактор удаляют и наоборот. При отборе факторов следует обращать внимание на наличие интеркорреляции и мультиколлинеарности.
Сильная корреляция между двумя факторами (интеркорреляция) не позволяет выявить изолированное влияние каждого из них на результативную переменную, то есть затрудняется интерпретация параметров регрессии и они утрачивают истинный экономический смысл. Оценки значений этих параметров становятся ненадёжными и будут иметь большие стандартные ошибки. При изменении объёма наблюдений они могут сильно изменяться, причём не только по величине, но даже и по знаку.
Мультиколлинеарность – явление, когда сильной линейной зависимостью связаны более двух переменных; она приводит к тем же негативным последствиям, о которых только что было сказано. Поэтому, при отборе факторов следует избегать наличия интеркорреляции и, тем более, мультиколлинеарности.
Для обнаружения интеркорреляции и мультиколлинеарности можно использовать анализ матрицы парных коэффициентов корреляции [ r (п)], матрицы межфакторной корреляции [ r (11)] и матрицы частных коэффициентов корреляции [ r (ч)].
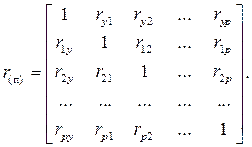
Для исключения одного из двух сильно коррелирующих между собой факторов можно руководствоваться таким соображением: из модели бывает целесообразно убрать не тот фактор, который слабее связан с y, а тот, который сильнее связан с другими факторами. Это приемлемо, если связь с y для обоих факторов приблизительно одинакова. При этом возможно наличие парето – оптимальных альтернатив и тогда следует рассмотреть иные аргументы в пользу того или иного фактора.
Матрица [ r (11)] – получается путём вычёркивания первого столбца и первой строки из матрицы [ r (п)].
Матрица [ r (11)] – квадратная и неособенная, ее элементы вычисляются так:
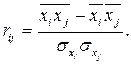
Представляется интересным исследовать определитель det [ r (11)].
Если есть сильная мультиколлинеарность, то почти все элементы этой матрицы близки к единице и det → 0. Если все факторы практически независимы, то в главной диагонали будут стоять величины, близкие к единице, а прочие элементы будут близки к нулю, тогда det→1.
Таким образом, численное значение det [ r (11)] позволяет установить наличие или отсутствие мультиколлинеарности. Мультиколлинеарность может иметь место вследствие того, что какой-либо фактор является линейной (или близкой к ней) комбинацией других факторов.
Для выявления этого обстоятельства можно построить регрессии каждой объясняющей переменной на все остальные. Далее вычисляются соответствующие коэффициенты детерминации
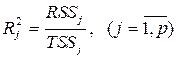
и рассчитывается статистическая значимость каждой такой регрессии по F –статистике:
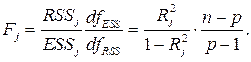
Критическое значение F определяется по таблице для назначенного уровня значимости γ (вероятности отвергнуть верную гипотезу Н 0 о незначимости R 2 ), и числа степеней свободы df 1= p –1, df 2 = n –1.
Оценку значимости мультиколлинеарности можно также произвести путём проверки гипотезы об её отсутствии: Н 0 : det [ r (11)] =1. Доказано, что величина: 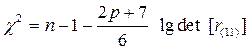 приближённо имеет распределение Пирсона:
приближённо имеет распределение Пирсона: 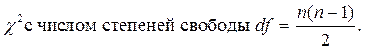 Если вычисленное значение χ 2 превышает табличное значение для назначенного γ и df = n (n –1)/2, то гипотеза Н 0 отклоняется и мультиколлинеарность считается установленной.
Если вычисленное значение χ 2 превышает табличное значение для назначенного γ и df = n (n –1)/2, то гипотеза Н 0 отклоняется и мультиколлинеарность считается установленной.
Парные коэффициенты корреляции не всегда объективно показывают действительную связь между факторами. Например, факторы могут по существу явления не быть связаны между собой, но смещаться в одну сторону под влиянием некоторого стороннего фактора, не включенного в модель. Довольно часто таким фактором выступает время. Поэтому включение (если это возможно) в модель переменной t иногда снижает степень интеркорреляции и мультиколлинеарности. Более адекватными показателями межфакторной корреляции являются частные коэффициенты корреляции. Они отражают тесноту статистической связи между двумя переменными при элиминировании влияния других факторов.
Частные коэффициенты корреляции вычисляются по следующим формулам:
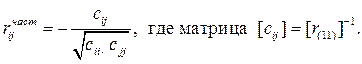
Таким образом, 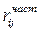 показывает корреляционную связь между хi и x j, при элимировании влияния прочих факторов и он более правдив, чем rij (парный коэффициент корреляции).
показывает корреляционную связь между хi и x j, при элимировании влияния прочих факторов и он более правдив, чем rij (парный коэффициент корреляции).
4.3. Влияние на качество модели множественной регрессии избыточных переменных и отсутствия существенных переменных
Пусть истинная модель представляется в виде:
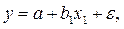
а мы считаем, что моделью является регрессионное уравнение
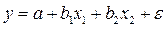
и рассчитываем оценку величины b 1 по формуле
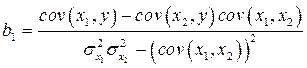 вместо формулы
вместо формулы 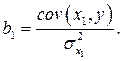
В целом проблемы смещения оценки здесь нет, но в общем случае оценка будет неэффективной в смысле наличия большей дисперсии, чем при правильной спецификации. Это легко понять интуитивно. Истинная модель может быть записана в виде 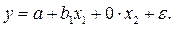
Здесь b 1 будет являться несмещенной оценкой параметра β 1, а b 2 будет несмещенной оценкой нуля (при выполнении условий Гаусса-Маркова).
Утрата эффективности в связи с включением x 2 в случае, когда она не должна быть включена, зависит от корреляции между x 1 и x 2.
Сравним (см. табл. 4.1):
таблица 4.1
Парная регрессия 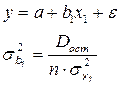 | Множественная регрессия 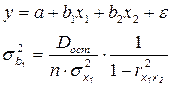 |
Дисперсия окажется большей при множественной регрессии, и разница будет тем больше, чем коэффициент парной корреляции 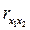 будет ближе по модулю к единице.
будет ближе по модулю к единице.
Теперь, пусть переменная y зависит от двух факторов x 1 и x 2:
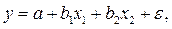 однако мы не уверены в значимости фактора x 2, и
однако мы не уверены в значимости фактора x 2, и
поэтому мы запишем уравнение регрессии так:
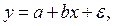 или
или 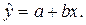
Если выбросить x 2 из регрессионной модели, то x 1 будет играть двойную роль – отражать свое прямое влияние на объясняемую переменную y и заменять фактор x 2 в описании его влияния. Это опосредованное влияние величины x 1 на y будет зависеть от двух обстоятельств: от видимой способности переменной x 1 имитировать поведение x 2 и от прямого влияния x 2 на y. Способность переменной x 1 объяснять поведение переменной x 2 определяется коэффициентом наклона h линии псевдорегрессии:
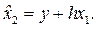
Величина коэффициента h рассчитывается при помощи обычной формулы для парной регрессии
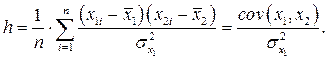
Влияние х 2 на у определяется в адекватном уравнении регрессии коэффициентом b 2, и таким образом, эффект имитации посредством величины b 2 может быть записан как 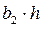 (прямое влияния величины х 1 на у описывается с помощью b 1).
(прямое влияния величины х 1 на у описывается с помощью b 1).
При оценивании регрессионной зависимости у от х 1 (без включения в нее переменной х 2) коэффициент при х 1 определяется формулой:
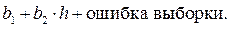
При условии, что величина х 1 не является стохастической, ожидаемым значением коэффициента при х 1 будет сумма первых двух членов последней формулы. Присутствие 2-го слагаемого предполагает, что математическое ожидание коэффициента при х 1 будет отличаться от истинной величины b 1, то есть, другими словами, оценка будет смещенной. Величина смещения определится выражением:
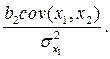
Направление смещения определяется знаками b 2 и cov (x 1 ,x 2); иногда смещение бывает настолько сильным, чтобы заставить коэффициент регрессии сменить знак.
Если 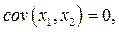 то смещение исчезает.
то смещение исчезает.
Другим серьезным следствием невключения переменной, которая на самом деле должна присутствовать в регрессии, является то, что формулы для стандартных ошибок коэффициентов и тестовые статистики, вообще говоря, становятся неприменимыми.
4.4. Оценка параметров модели множественной регрессии
Параметры модели в классическом варианте оценивают с помощью МНК. Предпосылки для МНК в множественной регрессии:
1. математическое ожидание остатков во всех наблюдениях равняется нулю 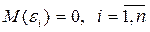 ;
;
2. отсутствие гетероскедастичности остатков
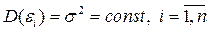 ;
;
3. отсутствие автокорреляции в остатках
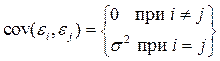 ;
;
4. объясняющие переменные детерминированы, а у – объясняемая переменная, случайна и остатки не коррелируют с объясняющими переменными.
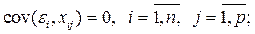
5. остатки должны быть распределены нормально: ε i ~ N (0; σ);
ε i ~ N (0; σ);
6. регрессионная модель должна быть линейна относительно параметров;
7. отсутствие интеркорреляции и мультиколлинеарности
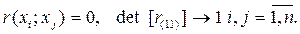
Уравнение множественной регрессии выглядит следующим образом:
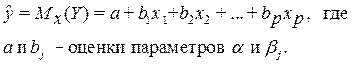
Обратившись к матричной форме записи можно увидеть, что система нормальных управлений (СНУ), для такой множественной линейной модели будет иметь такой вид:
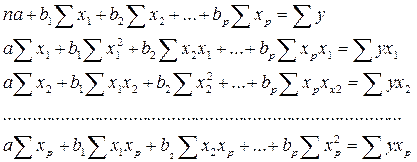
В матричной форме вектор оценки параметров запишется:
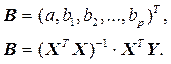
Дисперсия остатков отыскивается так:
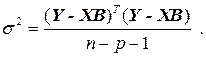
Эти формулы справедливы для классического МНК при гомоскедастичности остатков и отсутствии автокорреляции в остатках.
Модель, где все факторы, присутствуют в масштабах своих единиц измерения, не позволяет сравнить (оценить) степень вклада каждого фактора в результат, поэтому для исключения этого недостатка строят уравнения с использованием стандартизованных переменных и коэффициентов.
Коэффициенты регрессии 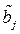 такой модели имеют тот же смысл, что и в парной регрессии, только каждый коэффициент отвечает за свой фактор. Они показывают на сколько своих СКО
такой модели имеют тот же смысл, что и в парной регрессии, только каждый коэффициент отвечает за свой фактор. Они показывают на сколько своих СКО 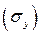 изменится в среднем результат y, если соответствующий фактор
изменится в среднем результат y, если соответствующий фактор 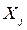 изменится на одно свое СКО
изменится на одно свое СКО 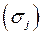 при неизменном среднем уровне остальных факторов.
при неизменном среднем уровне остальных факторов.
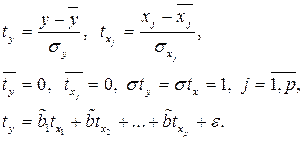
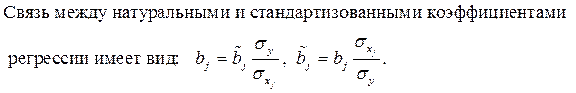
Долю влияния j –го фактора в суммарном влиянии всех факторов можно оценить по величине дельта–коэффициентов 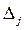 :
:
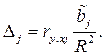
Качество уравнения множественной регрессии можно оценить с помощью коэффициента множественной корреляции или его квадрата - коэффициента детерминации:
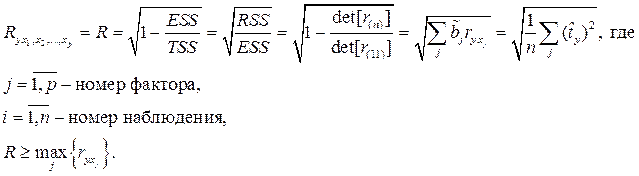
Если число наблюдений n недостаточно велико по сравнению с количеством факторов p, то величина R 2 считается завышенной и в таких случаях вычисляют исправленное значение R 2.
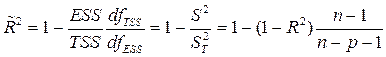 .
.
4.5. Оценка надёжности результатов множественной регрессии.
Вычислим F – статистику:
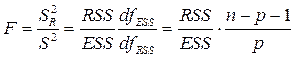 .
.
Значимость уравнения в целом можно оценить с помощью статистики Фишера, а значимость каждого фактора оценивают с помощью t -статистик Стьюдента:
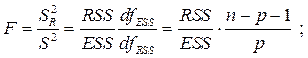
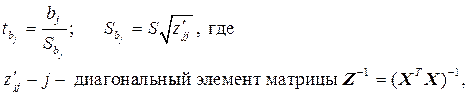
Интервальные оценки коэффициентов множественной регрессии и среднего значения прогноза будут иметь вид: