2014-01-25
2014-01-25 847
847Классификация онтологий по содержимому
Прикладные онтологии
Онтологии предметных областей
Назначение схоже с назначением онтологий верхнего уровня, но область
интереса ограничена предметной областью (авиация, медицина, культура).
Примеры: АвиаОнтология, CIDOC CRM, UMLS.
Назначение этих онтологий в том, чтобы описать концептуальную
модель конкретной задачи или приложения. Они содержат наиболее
специфичную информацию. Примеры проектов: TOVE, Plinius.
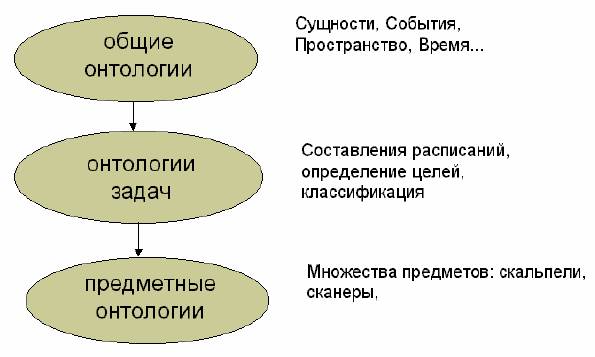
Рис. 5. Классификация онтологий содержимому.
Данная классификация очень похожа на предыдущую, но здесь упор
делается на реальное содержимое онтологии, а не на абстрактную цель,
преследуемую авторами.
Для того чтобы применить u1086 онтологию для автоматической обработки
текстов, в частности для решения задач информационного поиска,
необходимо понятиям онтологии сопоставить набор языковых выражений
(слов и словосочетаний), которыми понятия могут выражаться в тексте.
Процедура сопоставления понятий онтологий и языковых выражений
может быть осуществлена различными способами:
Во-первых, онтология может быть сделана заранее, путем логической
классификации, а затем к ее единицам могут быть приписаны языковые
единицы. Так, например, Doug Lenat, руководитель известного проекта в
области представления знаний CYC, в рамках которого предполагалось
формализовать знания здравого смысла (common sense) и использовать их, в
частности, для обработки текстов на естественном языке, считает, что учет
значений слов может только запутать ("words are often red herrings"), что
значения слов делят мир неоднозначно, а линии деления происходят из самых
различных причин: исторических, физиологических и т.п.
Предлагается создавать онтологию путем логического анализа, «сверху-
вниз». При этом, имена вводимых понятий (желательно) должны отражать те
признаки, которые заложены в основу деления. В результате получаются
имена понятий достаточно громоздкие, неестественные, с ними трудно
оперировать как разработчикам, так и возможным пользователям.
Другой проблемой такого подхода является то, что при приписывании
языковых выражений к логически обоснованной системе понятий получается,
что одно и то же слово может соответствовать слишком большому
количеству таких «правильных» понятий в зависимости от контекста,
возникает излишняя многозначность лексической единицы.
Кроме того, тогда как небольшие онтологии могут быть построены
методом сверху-вниз, разработка подробных онтологий для реальных
приложений – нетривиальная задача. Более того, во многих предметных
областях, знание, нужное для распространения и интеграции, содержится в
основном в текстах. Из-за внутренних свойств человеческого языка,
непростой задачей является связать знания, содержащиеся в текстах, с
онтологиями, даже если бы была построена подробная онтология предметной
области.
Некоторые исследователи, такие как известный британский лингвист
Йорик Вилкс, считают, что «несмотря на то, что все авторы статей по
онтологиям подчеркивают, что понятия являются кирпичиками любой
онтологии, мы манипулируем понятиями посредством слов. Во всех
онтологиях, которые известны, слова используются, чтобы представлять
понятия. Следовательно, то множество явлений в мире, которые не
вербализованы, не могут быть смоделированы. Мы можем описать это
явление как Онтологическая гипотеза Сепира-Уорфа, то есть то, что не
описывается словами, не может быть отражено в онтологии…».
Второе направление, которое обычно обсуждается, это установление
соответствий между иерархическими лексическими ресурсами типа WordNet
и некоторой онтологией. WordNet-ресурсы описывают лексические
отношения между значениями слов, представленные в виде отдельных
единиц в иерархической сети – синсетов. Отношения между лексическими
единицами в значительной мере отражают отношения объектов внешнего
мира, поэтому такие ресурсы часто рассматриваются как особый вид
онтологий – лексические или лингвистические онтологий.
Главной характеристикой лингвистических онтологий является то, что
они связаны со значениями (“are bound to the semantics”) языковых
выражений (слов, именных групп и т.п.).
Лингвистические онтологии охватывают большинство слов языка, и
одновременно имеют онтологическую структуру, проявляющуюся в
отношениях между понятиями. Лингвистические онтологии могут поэтому
рассматриваться как особый вид лексической базы данных и особый тип
онтологии.
Лингвистические онтологии отличаются от формальных онтологии по
степени формализации. Поэтому предполагается, что разработчики такого
рода ресурсов разрабатывают иерархию лексических значений естественного
языка, а для более строгого описания знаний о мире необходимо сопоставить
такие ресурсы с какими-либо формальными онтологиями.
Так, содержанием одного из проектов является установление отношений
между WordNet и EuroWordNet, c одной стороны, и формальной
онтологией SUMO - Standartized Upper Merged Ontology, с другой
стороны. Проект состоит в том, чтобы установить соответствие между
синсетами WordNet и понятиями онтологии, при котором каждый
синсет WordNet либо напрямую сопоставляется с понятием
онтологии, либо является гипонимом для некоторого понятия, либо
примером понятия онтологии.
Участники другого проекта OntoWordNet считают, что недостаточно
провести формальную склейку ресурса типа WordNet и формальной
онтологии, необходима значительная реструктуризация исходного
лексического ресурса.
Третий путь – попытаться разработать единый ресурс, в котором были
бы сбалансированы обе части: система понятий – и система лексических
значений, что заключается в разумном разделении этих единиц в создаваемом
ресурсе и аккуратном описании их взаимосвязей. Попытка такого подхода
реализуется в онтологиях MikroKosmos и OntoSem.
_
ОНТОЛОГИИ ВЕРХНЕГО УРОВНЯ: ОТЛИЧИТЕЛЬНЫЕ ЧЕРТЫ,
РЕШАЕМЫЕ ЗАДАЧИ (ПРИМЕРЫ ПРОЕКТОВ – OPENCYC, SUMO,
DOLCE, SOWA’S ONTOLOGY)