 2018-02-14
2018-02-14 3667
3667Введение
Измерительная информация в силу дискретности процесса измерения является дискретной. Дискретными являются различимые состояния объекта информации: дискретизированные (квантованные) значения физических величин, слова, буквы текста и т.д. Для обеспечения возможности передачи информации об этих дискретных состояниях (т.е. сообщению) каждому из них нужно поставить в соответствие некоторую синтаксическую конструкцию – кодировать сообщение. В лекции рассматриваются вопросы оптимального и помехоустойчивого кодирования.
Вопрос 1. Основные положения, термины и определения. Классификация кодов
Формально-математическое определение кодирования:
Пусть даны конечные множества Х, Y. Будем интерпретировать Х как множество исходных дискретных сообщений, Y как множество кодовых слов.
Тогда: отображение Т: Х → Y называется кодированием, если для ∀ y ∈ Y
∃ Т -1 (у) = х.
Правило, сопоставляющее каждому дискретному сообщению - букве или последовательности букв - кодовое слово называется правилом кодирования.
Сама операция сопоставления называемся кодированием сообщения.
Совокупность кодовых слов, обозначающих дискретные сообщения, называется кодом.
Множество кодовых букв (символов) называется кодовым алфавитом, а их количество - объемом алфавита или основанием кода. Количество букв в кодовом слове называется длиной кодового слова или значностью кода.
1. По наличию избыточности:
- неизбыточные;
- избыточные (корректирующие);
2. По значности (длине кодового слова):
- равномерные;
- неравномерные;
3. По типу оператора кодирования:
- линейные;
- нелинейные.
Классификация избыточных кодов:
1. По возможностям коррекции ошибок:
- обнаруживающие ошибки;
- исправляющие ошибки;
2. По количеству кодируемых символов:
- непрерывные (древовидные, рекуррентные сверточные, цепные);
- блочные;
2. По возможности разделения информационных и проверочных символов:
- разделимые;
- неразделимые.
Вопрос 2. Оптимальное кодирование
Поскольку кодирование есть процедура, требующая расхода ресурсов вычислительной системы, при кодировании сообщений дискретного источника возникает задача выбора правила оптимального кодирования (критерия).
Естественно полагать оптимальным такое правило кодирования (критерий), при котором:
–во-первых, кодовые слова могут быть декодированы в исходную последовательность букв источника;
–во-вторых, число кодовых букв, затрачиваемых на одну букву источника, в среднем минимально.
Первое требование определяет обратимость операции кодирования – однозначность декодирования, а второе - экономность кодирования или быстродействие кодера.
Очевидно, что «экономнее» будет кодер, в котором более вероятным буквам источника сопоставляются более короткие кодовые слова, т.е. в общем случае оптимальный код должен быть неравномерным.
Среднее число кодовых букв на одну букву источника можно определить по формуле
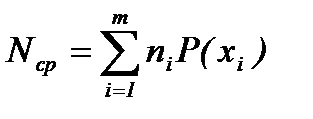 , (2.1)
, (2.1)
где ni – число кодовых букв, кодирующих слово xi источника,
P(xi) – вероятность появления буквы xi на выходе дискретного источника.
Нижним теоретическим пределом для Nср является энтропия Шеннона
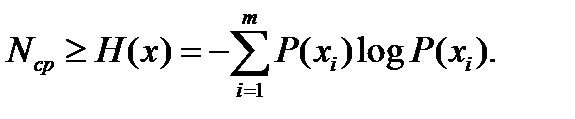
В оптимальном коде избыточность, связанная с неравномерностью появления символов полностью исключается.
Данные коды являются оптимальными с точки зрения «экономичности», в них минимизируется избыточность, однако они применимы для передачи информации только в каналах без искажений. Искажение любого бита кода ведет к искажению закодированного слова.

