 2018-02-14
2018-02-14 325
325
При научных и практических исследованиях часто приходится сталкиваться с типичной ситуацией – в одном из наблюдений результаты получены не совсем те, которые ожидались, проблема: наблюдаемые отклонения есть случайность или проявление некоторой новой закономерности (возможно, просто ошибка эксперимента, которая тоже есть проявление «новой закономерности», вроде немытых рук у лаборанта).
Разберем типичные примеры.
а) В результате наблюдений получена таблица значений некоторой случайной величины. Но на взгляд исследователя одно из значений подозрительно сильно отличается от всех остальных. Учитывать такой результат (результаты) или считать его ошибкой эксперимента? В первом случае мы предполагаем, что отклонение возникло в силу причин случайных, во втором – что имело место вмешательство некоего неизвестного стороннего фактора. Эта проблема обычно называется «проблемой принадлежности варианты к совокупности».
б) В результате теоретических исследований мы установили, что между некими двумя факторами А и В существует прямая пропорциональность с коэффициентом с, равным 2,3, т.е.: В = с×А Û В = 2,3×А. Но в реальности такая зависимость в точном виде никогда наблюдаться не будет, всегда будут присутствовать некие случайные ошибки, общий вклад которых мы обозначим через ε, таким образом, результат наблюдений всегда будет иметь вид:
В = 2,3×А +ε
Однако мы ведь не можем в опыте отделить вклад закономерный от вклада случайного, для нас результат всегда примет вид 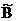 =
= 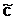 ×А, причем коэффициент при величине А мы всегда находим просто делением:
×А, причем коэффициент при величине А мы всегда находим просто делением: 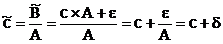 .
.
Здесь всюду значком «~»помечены величины, несущие в себе случайные искажения; при этом предполагается, что величину А мы знаем точно или, что то же самое, что ее ошибки достаточно малы.
Теперь представим себе, что очередная серия опытов дала нам такой результат:
= 2,7×А, т.е. = 2,7. А ведь теоретически мы ожидали результат, близкий к 2,3.
Какой вывод мы должны сделать? Возможны такие варианты:
- все идет нормально, а полученное отклонение от ожидаемого результата носит случайный характер
- наша теория о том, что коэффициент с должен быть близким к 2,3 ошибочна, возможно и само представление о наличии прямой пропорциональности между величинами А и В ошибочно
- наша теория вообще верна, но отклонение слишком велико и произошло оно из-за некоей ошибки при получении именно этой серии данных, повторные эксперименты/вычисления дают более близкие к ожидаемому значению 2,3 результаты.
Такая проблема называется «проблемойадекватности линейной модели».
в) Мы получили данные о распределении некоей случайной величины, есть серьезные основания полагать, что эта случайная величина распределена по известному теоретическому закону (нормальному, биномиальному, экспоненциальному). Мы построили кривую распределения. Однако полученные данные демонстрируют ощутимые отклонения от теории, вопрос: эти отклонения случайны, или предположение об известном теоретическом законе распределения данной случайной величины ошибочно?
Это проблема соответствия эмпирического распределения теоретическому закону.
При заметных различиях рассмотренных случаев а), б) и в) легко заметить и принципиальное сходство между ними. Во всех этих случаях мы должны найти объективный метод ответа на такой вопрос: как оценить расхождения между ожидаемым и наблюдаемым результатом? Т.е. выяснить – наш результат укладывается в модель случайных отклонений или свидетельствует о наличии некоего неучтенного фактора, возможно и просто о наличии грубой ошибки.
Это типичные случаи, которые решаются в рамках модели о нулевой гипотезе. Обычно всегда нулевая гипотеза состоит в том, что все расхождения между наблюдаемыми и ожидаемыми результатами носят случайный характер. Разберем, как работает такая модель на самом простом примере: на примере проблемы принадлежности варианты к совокупности.
Итак, пусть у нас есть некая таблица значений случайной величины х, причем известно, что эта случайная величина распределена по нормальному закону и некоторые значения хi кажутся нам выпадающими из общего ряда. Мы должны выполнить следующую последовательность операций.
1. Вычислим основные характеристики нашей совокупности данных: 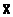 и σ, среднее значение и стандартное отклонение (ВНИМАНИЕ!! тут мы располагаем ВСЕЙ генеральной совокупностью, потому используем не s, а σ).
и σ, среднее значение и стандартное отклонение (ВНИМАНИЕ!! тут мы располагаем ВСЕЙ генеральной совокупностью, потому используем не s, а σ).
2. Задаемся некоторым уровнем значимости, скажем, 5% и выбираем коэффициент с, отвечающий этому уровню значимости, равным 1,96
3. Строим соответствующий доверительный интервал: ( − сσ, + сσ)
Те величины, которые попали в доверительный интервал, являются «правильными», т.е. их не отвергает нулевая гипотеза. Отклонения в пределах доверительного интервала следует признать таковыми, которые порождены случайными причинами.
Такова первая грубая схема.








