2018-02-14
2018-02-14 316
316Пусть нам дана дискретная двумерная случайная величина Z(X,Y), геометрически каждое ее значение может быть представлено точкой на плоскости (X,Y). При этом каждая из ее координат также является дискретной случайной величиной.
Как мы знаем из теории вероятностей, полное описание такой случайной величины задается таблицей вероятностей pij. Т.е. мы предполагаем, что нам известен набор возможных значений дискретных случайных величин Х и Y: {xi} и {yj}, тогда pij есть вероятность сложного события, состоящего в том, что в одном опыте одновременно величина X примет значение xi, а величина Y примет значение yj [12].
При сделанных предположениях мы можем вычислить характеристики всех упомянутых случайных величин.
M[X] = µx = 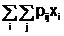 Dx =
Dx = 
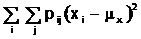 (1.6)
(1.6)
M[Y] = µy =  Dy =
Dy = 

Как известно, для двумерной случайной величины помимо двух дисперсий Dx и Dy существует еще один центральный момент второго порядка – корреляционный момент:

 (1.7)
(1.7)
Этот момент отражает наличие некоторой связи между случайными величинами X и Y, если они независимы, то σху равен нулю. Отметим, что обратное вообще говоря неверно: из того, что  = 0, не следует, что величины непременно независимы, они могут оказаться зависимыми; такие величины называют некоррелированными.
= 0, не следует, что величины непременно независимы, они могут оказаться зависимыми; такие величины называют некоррелированными.
В статистике мы не располагаем вероятностями, но мы предполагаем, что вероятности однозначно связаны с частотами для генеральной совокупности, а именно  ; здесь nij – количество случаев в генеральной совокупности, в которых случайная величина X = xi, а Y = yj. Таким образом, для характеристик генеральной совокупности получим выражения:
; здесь nij – количество случаев в генеральной совокупности, в которых случайная величина X = xi, а Y = yj. Таким образом, для характеристик генеральной совокупности получим выражения:

 (1.8)
(1.8)

Однако и данными о генеральной совокупности мы располагаем редко, потому приведенные формулы имеют скорее теоретическую ценность. Чаще всего мы располагаем только выборочными данными. Причем обычно в ходе получения этих выборочных данных мы проводим n испытаний, в каждом из которых определяется одно значение двумерной случайной величины zi = (xi,yi), т.е. тут i уже не номер одного из возможных значений дискретной случайной величины, а номер опыта, в ходе которого устанавливаются значения двумерной величины zi. Таким образом, мы располагаем одинаковым количеством одинаково нумерованных значений xi и yi, которые получены в ходе i-го измерения.
Для выборочных данных мы получим такие формулы:
 (1.9)
(1.9)
 (1.10)
(1.10)
Напомним, что здесь, как и в иных случаях, символами 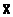 ,
,  мы будем обозначать выборочные средние, в отличие от генеральных средних µх и µу.
мы будем обозначать выборочные средние, в отличие от генеральных средних µх и µу.
Соответственно, Var(x), Var(y), Cov(x,y) мы будем называть центральные моменты второго порядка, рассчитанные для выборки. Напомним, что все они являются смещенными оценками[13] соответствующих моментов для генеральной совокупности:
M[Var(x)] =  M[Var(y)] =
M[Var(y)] =  M[Cov(x,y)] =
M[Cov(x,y)] =  [14]
[14]