2018-02-13
2018-02-13 656
656Процедура в Прологе - это совокупность предложений с головами, представленными одинаковыми термами.
Для обработки списков используются типовые процедуры.
Например, процедура member(X, L) проверяет принадлежность элемента списку.
Если X принадлежит L, то ответ - истина и ложь в противном случае.
С точки зрения декларативного смысла:
1. X принадлежит списку, если X совпадает с головой списка.
2. X принадлежит списку, если X принадлежит хвосту списка.
Можно записать:
member(X, [X|T]).
member(X, [H|T]):-member(X, T).
С точки зрения процедурного смысла - это рекурсивная процедура.
Первое предложение есть терминальное условие.
Когда хвост будет равен [ ] проверка остановится.
Сокращение списка происходит за счет взятия хвоста (cdr-рекурсия).
| ?-member(a, [a, b, с]). Yes?-member(X, [a, b, с]). Yes X = a X = b X = c | ||
?-member(a, X).
Ответ:
Yes
X=a
Процедура append (L1, L2, L3) используется для соединения двух списков.
L1 и L2 - списки, а L3 - их соединение.
| ?-append ([a, b], [c], [a,b,c]). Yes | ||
Для определения процедуры append используем два предложения:
1. Если присоединить пустой список [ ] к списку L, то получим список L.
append([], L, L).
2. Если присоединить не пустой список [X|L1] к списку L2, то результатом будет список [X|L3], где L3 получаeтся соединением L1 и L2.
С точки зрения процедурной семантики первое предложение - терминальное условие, второе - рекурсивное с хвостовой рекурсией.
Рассмотрим примеры:
?-append([a], [b, c], L).
L=[a, b, c]
?-append([a], L, [a, b, c]).
L=[b, c]
?-append(L, [b, c], [a, b, c]).
L=[a]
Эту процедуру можно использовать для разбиения списка на элементы.
Процедуру арреnd можно использовать для поиска комбинаций элементов.
Например, можно выделять списки слева и справа от элемента
| ?-append(L, [3|R], [1, 2, 3, 4, 5]). L=[1, 2] R=[4, 5] | ||
Можно удалить все, что следует за данным элементом и этот элемент тоже:
| ?-L1=[a, b, c, d, e], append(L2, [c|_], L1). L1=[a, b, c, d, e] L2=[a, b] | ||
Процедура reverse обращает список.
1. Пустой список после обращения - пустой.
reverse([ ], [ ]).
2. Обратить список [X|L1] и получить список L2 можно, если обратить список L1 в L3 и в хвост ему добавить X.
reverse([X|L1], L2):-reverse(L1, L3),
append(L3, [X], L2).
Можно подсчитать длину списка, используя процедуру length:
?-length([a, b, c], N).
N=3
4.3. Встроенные предикаты. Ввод\ вывод.
До сих пор мы получали ответы в форме предлагаемой Прологом:
1. Печатались значения переменных, присутствующих в вопросе;
2. Вопросы полностью записывались после запроса " ?- ".
Однако можно задавать вопросы и получать ответы в произвольной форме.
Для этого достаточно использовать встроенные предикаты.
Встроенные предикаты – предикаты, определенные в Прологе, для которых не существует процедур в базе данных.
Когда интерпретатор встречает цель, которая сравнивается с встроенным предикатом, он вызывает встроенную процедуру.
Встроенные предикаты обычно выполняют функции, не связанные с логическим выводом.
Встроенные предикаты обеспечивают возможности ввода-вывода информации:
1. write/1 - этот предикат всегда успешен. Когда он вызывается, побочным эффектом будет вывод значения аргумента на экран.
2. nl/0 - этот предикат всегда успешен. Когда он вызывается, то побочным эффектом будет перевод на следующую строку.
3. tab/1 - этот предикат всегда успешен. Когда он вызывается, то побочным эффектом будет печать количества пробелов, заданное аргументом. Аргумент должен быть целым.
4. read/1 - этот предикат читает терм, который вводится с клавиатуры и заканчивается точкой. Этот терм сопоставляется с аргументом.
Например,
pr1:- read(X),nl,write('X='),tab(2),write(X).
При вызове
?-pr1.
последовательность термов следующая:
· читается значение X;
· переводится строка;
· печатается 'X=';
· пропускается два пробела;
· печатается значение X.
Ввод-вывод списков
Для ввода-вывода списков возможны следующие два способа.
При этом способе список рассматривается как один терм.
Например, процедура:
pr:-write('Введите список L:'),nl, read(L),nl, write('Список L='),
tab(2), write(L),nl.
при вызове цели ?-pr. будет выполнять следующие действия:
Введите список L:
[a,b,c,d].
Список L= [a,b,c,d]
Данный способ может быть организован с помощью рекурсивно определенных процедур. Нужно знать, что end - терм, означающий конец списка.
read_list([X|T]):-write('Введите элемент: '), read(X), X\=end, read_list(T).
write_list([H|T]):-write(H), tab(2), write_list(T).
Тогда после вызова цели:
| ?-read_list(L),nl,write('Список='), write_list(L). | ||
Возникает следующий диалог:
| Печать на экране | Ввод с клавиатуры |
| Введите элемент: | a. |
| Введите элемент: | b. |
| Введите элемент: | c. |
| Введите элемент: | d. |
| Введите элемент: | end. |
Далее напечатается Список= a b c d
Отсечение
В процессе вычисления цели пролог проводит перебор вариантов, в соответствии с установленным порядком. Цели выполняются последовательно, одна за другой, а в случае неудачи происходит откат
к предыдущей цели (backtracing).
Однако для повышения эффективности выполнения программы, часто требуется вмешаться в перебор, ограничить его, исключить некоторые цели.
Для этого в Пролог введена специальная конструкция cut - "отсечение", обозначаемая как "!".
Cut подсказывает прологу "закрепить" все решения предшествующие появлению его в предложении. Это означает, что если требуется бэктрекинг, то он приведет к неудаче (fail) без попытки поиска альтернатив.
Пусть база данных выглядит следующим образом:
| data(one). data(two). data(three). |
Правило имеют вид:
| cut_test_a(X):- data(X). Дополнительный факт имеет вид: cut_test_a('last clouse'). |
Цель:
| ?- cut_test_a(X),nl,write(X). one; two; three; last_clouse; no | ||
Теперь поставим ! в правило:
| cut_test_b(X):- data(X),!, cut_test_b('last clouse'). |
Цель:
| ?-cut_test_b(X),nl,write(X). one; no | ||
Происходит остановка бэктрекинга для левого data и родительского cut_test_b(X).
Теперь поместим! между двумя целями.
| cut_test_с(X,Y):- data(X),!,data(Y). cut_test_с('last clouse'). |
Теперь бэктрекинг не будет выполняться для левого data и родительского cut_test_b(X),но будет выполняться для правого data, стоящего после!.
| ?-cut_test_с(X,Y),nl,write(X-Y). one-one; one-two; one-tree; no | ||
Рассмотрим функцию Y(X):
| ⌠ 0, X < 3 ⌠ Y= 2, 3 = < X < 6 ⌠ ⌠ 4, X >= 6 | 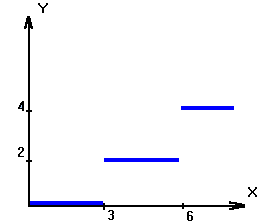
| |
На Прологе это запишется через бинарное отношение f(X, Y).
Математически процедура выглядит следующим образом:
| f(X, 0):- X < 3. f(X, 2):- 3 =< X, X < 6. f(X, 4):- 6 =< X. |
Зададим вопрос:
| ?-f(1,Y),Y>2. | ||
Таким образом, последовательно проверяются все три предложения, хотя сразу ясно, что выполняется только одно.
Как убрать неэффективность? Надо использовать отсечение cut.
Запишем процедуру математически следующим образом:
| f(X, 0):-X<3,!. f(X, 2):- 3=<X, X<6,!. f(X, 4):-6 =<X,!. |
! указывает, что возврат из этой точки проводить не надо.
Что произойдет теперь для цели
| ?-f(1, Y), Y>2. no | ||
После выполнения цели X< 3 цель Y > 2, не достигается, но откат не может произойти, так как стоит cut.
Таким образом, сокращается перебор.
Введение cut повышает эффективность программы, сокращая время перебора и объем памяти, не влияет на декларативное чтение программы.
После изъятия! декларативный смысл не изменится.
Такое применение cut называют "зеленым отсечением".
"Зеленые отсечения" лишь отбрасывают те пути вычисления, которые не приводят к новым решениям.
Бывают и "красные отсечения", при изъятии которых меняется декларативный смысл программы.
Рассмотрим предложение Н:-B1, B2,..., Bm,!,..., Bn.
Это предложение активизируется, когда некоторая цель G, будет сопоставляться с H. Тогда G называют целью-родителем.
Если B1, B2,..., Bm выполнены, а после!, например в Bi, i>m, произошла неудача и требуется выбрать альтернативные варианты, то для B1, B2,..., Bm такие альтернативы больше не рассматриваются и все выполнение окончится неудачей. Кроме этого G будет связана с головой H, и другие предложения процедуры во внимание не принимаются.
Формально действие отсечения описывается так:
Пусть цель -родитель сопоставляется с головой предложения, в теле которого содержится отсечение. Когда при просмотре целей тела предложения встречается в качестве цели отсечение, то такая цель считается успешной и все альтернативы принятым решениям до отсечения отбрасываются и любая попытка найти новые альтернативы на промежутке между целью-родителем и сut оканчиваются неудачей.
Процесс поиска возвращается к последнему выбору, сделанному перед сопоставлением цели родителя.
Решим задачу на основе ранее сказанного - найти минимальный элемент из двух.
minimum(X, Y, X):- X=<Y,!.
?-minimum(2, 5, Y).
Y=2
Чтобы добавить элемент в голову списка достаточно использовать
add(X, L, [X|L]).
Но если возникает необходимость добавлять только, если элемент отсутствует, то нужно использовать правило:
add(X, L, L):-member(X, L),!, add(X, L, [X|L]).
?-add(a, [b, c], L).
L=[a, b, c]
?-add(b, [b, c], L).
L=[b, c]
Если сечение убрать, то
| ?-add(b, [b, c], L) L=[b, c]; L=[b, b, c] | ||
Таким образом, при изъятии отсечения, изменился декларативный смысл программы - отсечение "красное".
Используя отсечение, легко произвести классификацию объектов. Например, стоит задача классифицировать числа, решим ее следующим путем:
class(X, plus):-X>0,!.
class(X, minus):-X<0,!.
class(X, zero):-X=0,!.
?-class(4, Y).
Y=plus
Применение отсечения в рекурсии позволяет значительно сократить использование памяти. Определим функцию факториал N! следующим образом:
| factorial(0, 1):-!. factorial(N, RES):- M is N-1, factorial(M, Mfak), RES is N*Mfak. |
Применение сечения за счет сокращения перебора позволяет повысить эффективность программы. Кроме этого отсечение упрощает программирование выбора вариантов.
Вместе с тем, часто, при использовании красных отсечений может измениться декларативный смысл программы.
Поэтому отсечение требует осторожности в использовании.
Следует избегать двух ошибок:
- отсечения путей вычисления, которые нельзя отбрасывать
- нельзя отсекать те решения, которые должны были быть отброшены.
Сортировка списков
До сих пор средства пролога использовались при записи простых процедур и примеров. Рассмотрим более сложные примеры написания программ на прологе для различных методов сортировки.
Метод наивной сортировки
В этом методе элементы в списке переставляются (перемешиваются permutation/2),и проверяется отсортирован этот список или нет: sorted/1.
Правило имеет вид:
| sortn(L1, L2):- permutation(L1, L2), sorted(L2),!. | ||
| permutation(L, [H|T]):- append(V, [H|U], L), append(V, U, W), sorted([X,Y|T]):- order(X,Y), sorted([Y|T]). – рекурсия, в конце ответ истина или ложь, т.е.отсортирован массив или нет. | ||
Проверка того, что элементы списка расположены в возрастающем порядке выражается через два предложения. Факт означает, что список из одного элемента всегда упорядочен. Правило утверждает, что список упорядочен, если первые два элемента расположены по порядку и остаток, начинающийся со второго элемента тоже упорядочен:
Метод пузырька
Декларативное описание:
1. Найти в списке L два смежных элемента X и Y, таких, что X > Y, поменять их местами и получить новый список, M, затем отсортировать M. Для поиска таких элементов и перестановки используется процедура swap/2.
2. Если в списке нет ни одной пары смежных элемента X и Y, таких, что X > Y, считать что список отсортирован.
| busort(L, S):- swap(L, M),!, busort(M, S). -рекурсия busort(L, L):-!. swap([X, Y|R], [Y, X|R]):- order(X, Y). swap([X|R], [X|R1]):- swap(R, R1). - рекурсия order(X, Y):- X > Y, T is X, X is Y, Y is T. – перестановка по возрастанию. Последовательность всех действий, отвечающих на вопрос ?-busort((3,7,8,2), S). следующая: 1. Обращение к busort((3,7,8,2), S):-swap((3,7,8,2),M),!, busort(M, S). 2.Обращение к swap([X=3,Y=7 |R=8,2],[Y,X|R]):- order(X=3, Y=7). 3.Обращение к order(X=3, Y=7):- 3< 7 - перестановка не нужна. 4. Обращение к swap([X|R], [X|R1]):- swap(R, R1), т.е. swap([X=3|R=(7,8,2)], [X|R1]):- swap((7,8,2),R1). 5.Обращение к swap([X=7,Y=8 |R=2],[Y,X|R]):- order(X=7, Y=8). 6. Обращение к order(X=7, Y=8):- 7< 8 - перестановка не нужна. 7. Обращение к swap([X|R], [X|R1]):- swap(R, R1), т.е. swap([X=7|R=(8,2)], [X|R1]):- swap((8,2),R1). 8. Обращение к order(X=8, Y=2):- 8>2 - X=2,Y=8– перестановка. 9. Обращение к swap([X|R], [X|R1]):- swap(R, R1), т.е. swap([X=2|R=8], [X|R1]):- swap(8,R1). 10. Обращение к swap([X=8,Y=[] | R[]],[Y,X|R]):- order(X=8, []). возникла неопределенность и операция не может быть выполнена. 11. Поскольку мы не достигли результата busort(L, L):-! процесс начинается с начала, но уже для массива(3,7,2,8). |
Mетод вставки
Декларативное описание:
Для того чтобы упорядочить непустой список L=[X|T] необходимо:
1. Упорядочить хвост Т списка L.
2. Вставить голову X списка L в упорядоченный хвост, поместив ее таким образом, чтобы получившийся список остался упорядоченным.
insort([], []).insort([X|L], M):- insort(L, N), insortx(X, N, M).
insortx(X, [A|L], [A|M]):- order(A, X),!, insortx(X, L, M).
insortx(X, L, [X|L]).
order(X, Y):- X =< Y.
Быстрая сортировка quick
Описание метода. Убираем первый элемент:
5 3 7 8 1 4 7 6 получаем: X =5.и оставшийся список: 3 7 8 1 4 7 6
Разбиваем новый список на два, помещая в первый элементы меньше X, а во второй - больше X:
(X: 3 1 4) X: 7 8 7 6Сортируем оба списка:
1 3 4 6 7 7 8Соединим первый список, X, второй список.
1 3 4 5 6 7 7 8
Декларативное описание:
1. Удалить из списка голову Х и разбить оставшийся список на два списка Small и Big следующим образом: все элементы большие чем Х помещаются в Big и меньшие X - в Small.
2. Отсортировать список Small в Small1.
3. Отсортировать список Big в Big1.
4. Соединить списки Small1 Х и Big1.
| qsort([], []).qsort([H|Tail], S):- split(H, Tail, Small, Big), qsort(Small, Small1), qsort(Big, Big1), append(Small1, [H|Big1], S). order(X, Y):- X =< Y.split(H, [A|Tail], [A|Small], Big):- order(A, H),!, split(H, Tail, Small, Big).split(H, [A|Tail], Small, [A|Big]):- split(H, Tail, Small, Big).split(_, [], [], []). |