2018-02-20
2018-02-20 1001
1001· COM (Component Object Model)
· OLE (Object Linking and Embedding)
Говоря об обмене данными между различными CAD/CAM/CAE-системами, мы обычно подразумеваем широко используемый механизм экспорта/импорта из формата хранения данных одной системы в формат хранения данных другой. Все это выполняется на файловом уровне и нередко приводит к частичной потере данных из-за их некорректной интерпретации. Связано это с тем, что разработчики программ преобразования данных из одного формата в другой зачастую лишены возможности взаимодействия с создателями данного формата и не имеют полной информации по его структуре.
В качестве альтернативы ряд компаний предлагает так называемый прямой интерфейс между приложениями, при котором данные опять же передаются из одного формата в другой. По сути, это то же самое, только реализовано совместными усилиями разработчиков соответствующих форматов и позволяет практически полностью устранить потерю конвертируемых данных. В то же время системы постоянно развиваются, их форматы хранения данных претерпевают различные модификации, требуя внесения соответствующих изменений и в интерфейсы обмена данными. Это приводит к необходимости постоянного привлечения специалистов для поддержки обмена данными между приложениями.
Пользователи программного обеспечения Microsoft Office с технологией Object Embedding and Linking (OLE) — внедрение и связывание объектов — работают уже давно. Первоначально она обозначала возможность внедрения документа, созданного в одном приложении, в документ, созданный в другом приложении. Хорошим примером этому могут послужить таблицы Excel в документах Word. Изначальная концепция OLE изменялась со временем и в итоге была заменена идеей модели объектных компонентов (Component Object Model — COM). COM представляет собой глобальный интерфейс для создания программных компонентов, которые можно совместить с другими компонентами в любом сочетании.
Особенностью COM-объектов является то, что они существуют в пределах одного компьютера. Следующим шагом стало появление Distributed Common Object Model (DCOM), которые, по сути своей, практически ничем не отличаются от COM-объектов, за исключением того, что существуют и взаимодействуют друг с другом они не только в пределах одного компьютера, но и в компьютерной сети. Здесь мы уже имеем распределенную объектную модель, когда множество взаимодействующих друг с другом объектов находятся на разных рабочих местах, объединенных сетью.
OLE for D&M (в литературе можно встретить обозначение OLE4DM) — это один из аспектов распределенной модели, когда предлагается набор стандартных интерфейсов для обмена и управления данными между трехмерными CAD-, CAM- и CAE-систем. Эта технология нацелена на предоставление прямого доступа одной системы к данным математической модели другой системы, минуя файловый обмен. OLE for D&M поддерживает клиент-серверную технологию и выступает одним из эффективных средств интеграции отдельных Windows-приложений в единый комплекс. Если приложение поддерживает этот интерфейс, оно легко интегрируется с другой системой.
a. Общие сведения
Одним из условий успешного функционирования САПР является наличие необходимой информации.
Под информационным обеспечением САПР понимаются документы, содержащие описания стандартных проектных процедур, типовых проектных решений, типовых элементов, комплектующих изделий, материалов и другие данные, а также файлы и блоки данных на машинных носителях с записью указанных документов.
Основной задачей информационного обеспечения процессов проектирования является своевременная выдача источнику запроса полной и достоверной информации, приводящей к выполнению определенной части процесса проектирования.
Исходя из этого к информационному обеспечению САПР предъявляются следующие требования:
• обеспечение информацией как автоматизированных, так и ручных процессов проектирования;
• хранение и поиск информации, представляющей результат ручных и автоматизированных процессов проектирования;
• достаточный объем хранилищ информации. Структура системы должна допускать возможность наращивания емкости памяти вместе с ростом объема информации, подлежащей хранению, одновременно должны обеспечиваться компактность хранимой информации и минимальный износ носителей информации;
• быстродействие системы информационного обеспечения, благодаря которой время получения информации проектировщиками гораздо меньше времени, необходимого для получения этой же информации традиционными средствами;
• возможность быстрого внесения изменений и корректировки информации, доведения этих изменений до потребителя и получения твердой копии документа.
При создании информационного обеспечения основная проблема заключается в преобразовании информации, необходимой для выполнения проектно-конструкторских работ над данным классом объектов, в приемлемую и наиболее рациональную для машинной обработки форму.
Основу информационного обеспечения САПР составляет совокупность всевозможных данных, которые используются в процессе проектирования. При проектировании сложного объекта, в котором участвует более одного проектировщика, данные, необходимые каждому из них, должны быть легко доступны одновременно.
Данные — это сведения о некоторых фактах, позволяющие делать определенные выводы. Взаимосвязанные данные часто называют системой данных, а хранимые данные — информационным фондом. Основное назначение информационного обеспечения — предоставлять пользователям САПР достоверную информацию в необходимом им виде.
На заре развития вычислительной техники данные хранились на перфоленте или перфокартах, которые могли считываться электронным оборудованием. Для обработки данных существовали специальные прикладные программы, представлявшие собой независимые программные единицы и не являвшиеся частью более сложной системы, которую в современных условиях представляет САПР.
Со временем оборудование и используемые для эксплуатации системы электронной обработки данных процедуры существенно усложнились. В качестве информационных носителей в настоящее время преимущественно используются магнитные и оптические носители, отличающиеся большей на несколько порядков плотностью записи. Стало возможным использовать как независимые информационные системы, так и являющиеся подсистемами более сложных систем.
Главная цель информационного обеспечения осталась прежней — предоставление по запросу заинтересованного пользователя достоверной информации в определенное время.
Чтобы понять процесс электронной обработки данных, необходимо знать ряд терминов, которые применяются при описании и представлении данных.
Предметная область может относиться к любому типу организации (банк, университет, больница или завод) или автоматизированной системы. Для предметной области САПР может потребоваться информация, характерная для данной области проектирования.
Объектом может быть любой предмет, событие, понятие и т.п., о котором приводятся данные.
Каждый объект характеризуется рядом основных атрибутов. Например, конструкционный материал характеризуется плотностью, прочностными параметрами, тепло- и электропроводностью и т. п., автомобиль можно характеризовать такими атрибутами, как максимальная скорость, динамика разгона, расход топлива, масса, габариты и др.
Атрибут называют также элементом данных, полем данных или просто полем.
Сведения, содержащиеся в каждом атрибуте, называют значениями данных. Значения данных представляют действительные данные, содержащиеся в каждом элементе данных; ими могут быть конкретные величины упомянутых выше характеристик конструкционного материала.
Среди атрибутов имеются такие, по значениям которых возможна идентификация объекта. Атрибуты, по значениям которых определяют значения других атрибутов, называют идентификаторами объекта, или ключевыми элементами данных. Отметим, что один и тот же объект могут идентифицировать несколько элементов данных. Их тогда считают кандидатами в идентификаторы. Проблему выбора идентификатора из нескольких кандидатов решает пользователь САПР. Например, зная какую-либо из характеристик конструкционного материала, можно определить вид этого материала, его свойства.
Совокупность значений связанных элементов данных образует запись данных. В приведенном выше примере с конструкционным материалом такими элементами данных являются конкретное его обозначение и численные значения его свойств.
Упорядоченную совокупность записей данных называют файлом данных, или набором данных.
Наиболее высокой формой организации информационного обеспечения для больших систем являются банки данных, представляющие собой совокупность средств для централизованного накопления и коллективного использования данных в САПР. Банк данных является проблемно-ориентированной информационно-справочной системой, которая обеспечивает ввод необходимой информации, автономное от конкретных задач ведение и сохранение информационных массивов и выдачу необходимой информации по запросу пользователя или программы. Банк данных может быть определен как система программных, языковых, организационных и технических средств, предназначенных для хранения и многоцелевого использования информации.
Банки данных должны обеспечивать:
сокращение времени поиска данных;
многократность использования данных;
простоту и удобство обращения к данным пользователей;
достоверность хранения данных.
Основными частями банка данных является база данных (БД), Представляющая собой систематизированные взаимосвязанные совокупности данных, и система управления базами данных (СУБД), обеспечивающая необходимые манипуляции с информационными массивами.
Множество данных, которые потенциально могут использоваться при функционировании САПР или являются запоминаемым результатом ее работы, образует БД системы.
База данных — сами данные, находящиеся в запоминающих устройствах ЭВМ и структурированные в соответствии с принятыми в данном банке данных правилами.
Система управления базами данных — совокупность программных средств, обеспечивающих функционирование банка данных. С помощью СУБД производятся запись данных в БД, их выборка по запросам пользователей и прикладных программ, обеспечивается защита данных от искажений и несанкционированного доступа и т. п.
Файлы данных чаще всего специально создаются для использования конкретными программами (подпрограммами), которые реализуют ввод данных из файла в строго определенной последовательности.
К недостаткам размещения данных, необходимых предметной САПР, в файлах данных можно отнести следующие.
Избыточность данных. Некоторые элементы данных, необходимых САПР, неизбежно используются во многих прикладных программах. Поскольку данные требуются нескольким прикладным программам, они часто записываются в несколько файлов, при этом одни и те же данные хранятся в разных местах. Такое положение называют избыточностью данных. Оно делает проблематичным обеспечение непротиворечивости данных и обусловливает еще один недостаток — сложность в управлении.
Проблемы непротиворечивости данных. Одной из причин нарушения непротиворечивости данных является их избыточность, что связано с хранением одной и той же информации в нескольких местах. При необходимости обновления информации ее нужно изменить во всех файлах, что бывает затруднительно. В результате об одном и том же объекте предметной области в разных местах хранится различная информация.
Ограничения по доступности данных. В современных условиях лицо
с соответствующими правами доступа должно иметь возможность
получить данные за приемлемый отрезок времени. Если же данные содержатся в разных файлах, доступность данных, комбинируемых из этих файлов, ограничена. —
Для решения вышеуказанных проблем были разработаны системы с базами данных, представляющими собой совокупность специально организованных данных, рассчитанных на применение в большом количестве прикладных программ конкретной предметной области, работа с которыми обеспечивается специальным пакетами
прикладных программ — системой управления базой данных с целью создания массивов данных, их обновления и получения справок. Основное отличие БД от файла данных состоит в том, что файл данных может иметь несколько назначений, но соответствует одному представлению о хранимых данных; БД также имеет несколько назначений, но соответствует различным представлениям о хранимых данных.
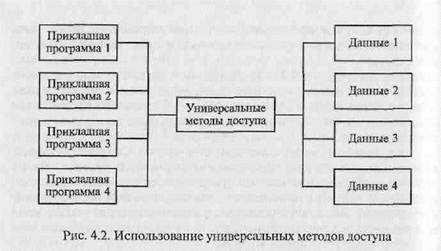
Программный модуль, входящий в состав САПР, при своей работе обращается за необходимой информацией не к какому-то массиву информации, как это имело место в автономных программах, а к СУБД. Последняя организует поиск необходимой информации в сложной информационной структуре — БД, упорядочивание и представление этой информации в необходимом объеме соответствующему модулю.
Различие в методах использования файлов данных и БД проиллюстрировано на рис. 4.1 и 4.2.
|
| |
| |

Основные требования к БД следующие:
• целостность данных — их непротиворечивость и достоверность;
• универсальность, т. е. наличие в БД всех необходимых данных и возможность доступа к ним в процессе решения проектной задачи;
• открытость БД для внесения в нее новой информации;
• наличие языков высокого уровня взаимодействия пользователей с БД;
• секретность, т. е. невозможность несанкционированного доступа к информации и ее изменений;
• оптимизация организации БД — минимизация избыточности
данных.
Одним из принципов построения САПР является информационная согласованность частей ее программного обеспечения, т. е. пригодность результатов выполнения одной проектной процедуры для использования другой проектной процедурой без их трудоемкого ручного преобразования пользователем. Отсюда вытекают следующие условия информационной согласованности:
• использование программами одной и той же подсистемы САПР единой БД;
• использование единого внутреннего языка для представления данных.
Комплексная автоматизация процесса проектирования объекта предполагает информационную согласованность не только отдельных программ подсистем САПР, но и самих подсистем между собой. Способом достижения этой согласованности является единство информационного обеспечения.
Основные способы информационного согласования подсистем САПР достигаются либо созданием единой БД, либо сопряжением нескольких БД с помощью специальных программ, которые перекодируют информацию, приводя ее к требуемому виду.
Сложность разработки БД определяется тем, что формирование структуры БД возможно только после разработки алгоритмов, реализуемых при проектировании. При этом необходимо, чтобы степень разработки алгоритмов была доведена до машинной реализации, так как структура БД должна учитывать специфику автоматизированного преобразования информации при решении проектных задач с целью эффективного использования вычислительной техники. Однако для разработки программ необходимы сведения о структуре БД. Следовательно, информационное обеспечение САПР и специальное программное обеспечение должны создаваться параллельно.
|
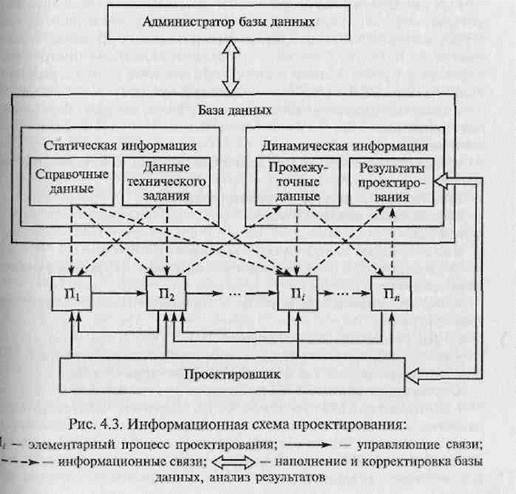
Информация, имеющая место при проектировании, может быть разделена на статическую и динамическую (рис. 4.3).
Статическая информация характеризуется сравнительно редкими изменениями и используется только в режиме чтения. К этой информации следует отнести данные технического задания на проектирование и справочные данные, которые характеризуются большим объемом. Формирование, загрузка и корректировка справочных данных осуществляются исключительно администратором базы данных, т. е. программистом системного профиля, формирующим БД. Объем данных технического задания на проектируемый объект значительно меньше объема справочных данных. Круг лиц, имеющих право вносить изменения в данные технического задания, более ограничен, чем круг лиц, имеющих право производить корректировку справочных данных.
Динамическая информация состоит из данных, накапливаемых для выполнения определенных процессов проектирования (промежуточные данные), и данных, представляющих собой результат проектирования при выполнении этих процессов. Промежуточные данные меняются при функционировании САПР. Вносить же коррективы в проектные результаты имеет право только главный конструктор проекта при соответствующем обосновании.
Широко используется в САПР фактографическая информация, составляющая основу БД. Эта информация представляет собой числовые и буквенные справочные данные о материалах, ценах, комплектующих изделиях, спроектированных в САПР объектах, их зарубежных и отечественных аналогах и т. п. Сюда же относятся данные, необходимые для выполнения расчетов: коэффициенты, таблицы, аппроксимированные графические зависимости и т.д.
При формировании БД в первую очередь надлежит исследовать информацию, необходимую для решения проектно-конструкторских задач. К этому исследованию следует подходить с двух позиций: с точки зрения полезности информации и с позиции эффективности обработки информации и пропускной способности вычислительной техники и человека.
Как уже отмечалось выше, части программного обеспечения и методы, осуществляющие управление базой данных, составляют СУБД, которая допускает множество различных представлений о хранимых данных, а также позволяет прикладным программам работать с БД без знания конкретного способа размещения данных в памяти ЭВМ. СУБД выступает как совокупность программных средств, предназначенных для создания, ведения и совместного использования БД многими пользователями и должна обеспечивать:
эффективное выполнение различных функций предметной области;
простоту физической реализации БД;
возможность централизованного и децентрализованного управления БД;
минимизацию избыточности хранимых данных;
предоставление пользователю по запросам непротиворечивой информации;
простоту разработки, ведение и совершенствование прикладных программ.
СУБД реализует два интерфейса:
• между логическими структурами данных в программах и БД;
• между логической и физической структурами БД.

|
Структурная схема СУБД приведена на рис. 4.4.
Манипулятор является ядром СУБД. В его функции входит управление компонентами системы, организация их взаимодействия и осуществление связи с операционной системой ЭВМ и администратором банка данных, выполнение основных операций над БД, контроль и защита целостности и секретности данных, редактирование вывода, кодирование (декодирование) и сжатие (расширение) данных, сбор статистики и ведение протокола.
Администратор банка данных осуществляет внешнюю координацию всей работы банка данных и выполняет действия, пока не поддающиеся формализации. Прежде всего он отвечает за разработку концептуальной модели предметной области, описывающей все представляющие интерес объекты и взаимосвязи. Концептуальная модель должна быть трансформирована в модель данных, поддерживаемую конкретной СУБД. Следовательно, администратору необходимо спроектировать логическую модель. Наконец, исходя из логической модели, он должен спроектировать физическую (внутреннюю) модель, которая будет обеспечивать требуемые операционные характеристики. Таким образом, в его функции входит создание БД, согласование требований пользователей, управление загрузкой баз, распределение паролей; общее управление работой банка данных (наблюдение за ходом работы, подключение новых пользователей, управление восстановлением при сбоях, принятие решений в случае нарушений секретности, анализ статистики, оценка и обеспечение эффективности работы БД); реорганизация БД (изменение схем, реорганизация баз); генерация и развитие СУБД.
Администратор и манипулятор выполняют свои функции, взаимодействуя с сервисными программами. Ряд сервисных программ допускает двойной запуск: автоматически со стороны манипулятора БД и вручную со стороны администратора, другие запускаются только администратором БД (например, программы моделирования БД). Администратор БД может пополнять набор новыми сервисными программами (контроля данных, измерения производительности и т.д.).
Сервисные программы осуществляют основные операции над БД, в частности сортировку, выборку данных, слияние, дополнение и изменение БД, редактирование ответов.
При функционировании банка данных различают следующие основные виды запросов к банку со стороны пользователей: на выдачу справок в виде показателей и документов для пользователей системы;
формирование и выдачу рабочих массивов для прикладных программ САПР;
выдачу рабочих массивов со стороны других банков данных;
пополнение или изменение БД;
ввод входных массивов.
Поступивший в банк данных запрос проходит этап предварительной обработки, на котором осуществляется синтаксический и логический контроль, включающий проверку пароля абонентов, недопустимых сочетаний признаков и т.д. При обнаружении ошибок запрос к дальнейшей обработке не принимается, а на печать выдается информация об ошибках.
Следующий этап — интерпретация запроса — состоит в распознавании вида запроса: на выдачу показателя и документов, на формирование рабочих массивов, на изменение или пополнение БД. На этом этапе запрос с языка запросов переводится на язык манипулирования данными.
В соответствии с поисковым предписанием происходят обращение к рабочей области в памяти и выборка искомых данных или корректировка данных в базе. Найденные в БД данные тщательно контролируются и анализируются, затем редактируются, а на печать выдается информация об ошибках.
Разработка банков данных и его основного инвариантного компонента, т. е. СУБД, представляет собой сложную задачу, требующую значительных затрат времени и предполагающую высокую квалификацию разработчиков в области системного программирования. В связи с этим при построении информационного обеспечения САПР конкретных технических объектов на основе банков данных необходимо сделать анализ существующих банков данных и принять для САПР один из уже разработанных. Однако и в этом случае необходимость использования такого сложного компонента, каким является банк данных, должна быть всесторонне обоснована. Следует иметь в виду, что информационное обеспечение САПР может быть организовано и на основе более простой, но специально разработанной информационной структуры, учитывающей специфику проектируемых технических объектов. Подобные ориентированные информационные структуры при относительной простоте и невысоких требованиях к конфигурации технических средств могут реализовать набор необходимых функций по обработке данных, для чего должно быть разработано необходимое программное обеспечение.
Такая альтернатива к использованию банков данных объясняется тем, что универсальные информационные системы в виде банков данных рассчитаны на решение задач с большей номенклатурой различных параметров и характеристик объектов, поэтому применение их при создании САПР с относительно небольшой номенклатурой данных иногда оказывается просто нецелесообразным, а порой и невозможным.
Одной из важнейших характеристик СУБД является модель данных, которая поддерживается СУБД. Как отмечалось, существуют три модели данных: иерархическая, сетевая и реляционная. Выбор той или иной модели данных для построения информационного обеспечения САПР зависит от требований, которые предъявляются к информационной базе, создаваемой САПР.
Большое значение при выборе СУБД имеют средства взаимодействия пользователей с БД. Непрограммисты, а ими являются большинство пользователей САПР, взаимодействуют с БД с помощью языков манипулирования данными с использованием средств телеобработки. Тогда СУБД САПР должна включать в себя язык манипулирования данными, доступный непрограммисту, и средства доступа к данным через терминал.
Кроме того, при выборе для САПР той или иной СУБД следует учитывать следующие требования:
• возможность обеспечения мультипрограммного режима;
• независимость данных от конкретных пакетов программ;
• наличие средств, позволяющих сократить дублирование данных в информационной базе; возможность восстановления БД;
• совместимость СУБД с операционной системой ЭВМ и т.д.
Рациональная организация и функционирование банка данных возможны лишь при максимальном учете специфики информации, заносимой в БД. Если специфические особенности такой информации не учитываются, это приводит к значительному перерасходу машинной памяти и увеличивает затраты времени на обработку данных.
База данных организуется на основе принципов системного подхода. При этом предполагаются:
неизбыточность, данных;
независимость данных от программ решения задач;
выбор структур данных, ориентированных на все задачи, решаемые системой;
возможность дополнения, развития и обновления данных;
типизация алгоритмов обработки данных.
Организация, структура и состав БД зависят от информационных моделей проектируемых объектов, от методов получения проектных решений и от используемых в САПР технических и программных средств. С другой стороны, все перечисленные факторы зависят от структуры БД. Основной особенностью БД по сравнению с массивами записей является наличие связей между структурными единицами данных.
Базы данных иногда определяют, как неизбыточную совокупность элементов данных. Однако в действительности для уменьшения времени доступа к данным во многих БД избыточность в незначительной степени присутствует. Некоторые записи повторяются для того, чтобы обеспечить возможность восстановления данных при их случайной потере. В этом случае говорят о минимальной избыточности БД.
Таким образом, БД можно определить, как совокупность взаимосвязанных, совместно хранящихся данных при наличии такой минимальной избыточности, при которой допускается их использование оптимальным образом для одного или нескольких приложений. Для этого данные запоминаются так, чтобы они были независимы от прикладных программ, использующих эти данные. Для добавления новых или модификации существующих данных и для поиска данных в БД применяется стандартный набор управляющих алгоритмов.
База данных представляет собой постоянно развивающийся объект (к ней добавляются новые записи, а в существующие включаются новые элементы данных). С целью повышения эффективности функционирования БД изменяется и ее структура. Используемые на практике способы построения БД реализуются в виде иерархических (древовидных), сетевых или реляционных моделей (моделей отношений) данных.
b. Банки данных
Модель- совокупность структур данных и операций их обработки.
Выбор той или другой модели происходит после получения всей информации о предметной области, ее описаний и детализации. Перед началом моделирования в собранной информации выделяются объекты, их характеристики и связи между ними. Для выбора конкретной модели первоначально предметную область желательно оценить с т.з. прямого моделирования понятий, т.е. оценивается возможность определения выделенных объектов в терминах и структурах выбранной модели данных.
Кроме возможности прямого моделирования оцениваются следующие свойства модели данных:
1. сложность модели для изучения пользователем;
2. наглядность;
3. сложность и трудоемкость написания программ для манипулирования структурами данных;
4. соблюдение правил композиции;
5. оптимальное число базисных структур и т.д.
Сетевая модель
Основные термины СМ:
1. Элемент данных – наименьшая поименованная единица данных, в которой содержится минимальный набор информации. С помощью элемента данных выполняется построение всех остальных структур (аналог поля).
2. Агрегат данных – совокупность элементов данных внутри записи, имеющая имя, причем эта совокупность рассматривается как единое целое. Агрегаты бывают простые и сложные.
3. Запись – поименованная совокупность элементов и агрегатов.
4. Набор – поименованная совокупность записей, образующих двухуровневую иерархическую структуру. Каждый тип набора представляет собой отношение (связь) между двумя или несколькими типами записи. Для каждого типа набора один тип записи м.б. объявлен владельцем набора, тогда остальные записи м.б. объявлены членами этого набора.
5. База данных – поименованная совокупность записей различного типа, содержащая ссылки между записями, представленная экземплярами наборов.
СМ строятся на основании следующих композиционных правил:
1. БД может содержать любое количество типов записей и типов наборов.
2. между двумя типами записей может быть определено любое количество типов наборов.
3. тип записи может быть одновременно и владельцем и членом различных типов наборов.СМ позволяет реализовать связи такие как «1:1», «1:М», «М:1».
СМ м.б. представлена в форме графов (структурная диаграмма данных) или с помощью таблиц (расширенная структурная диаграмма).
СМ относится к типу симметричных моделей, однако, в ней самые сложные алгоритмы по поиску информации. В сетевых моделях предусмотрены 4 основные оператора: добавить (insert), удалить (delete), найти (find), обновить (update).
При выполнении данных операций следует учитывать важность связей между объектами, особенно это касается операции «удаление», при которой может произойти удаление связующей записи. Операция «обновление» выполняется легко, т.к. каждая запись в единственном экземпляре.
Иерархическая модель
Примерами иерархических структур могут служить: справочники, классификаторы, организационные структуры.
Структура ИМ описывается в терминах:
1. Элемент данных – наименьшая поименованная единица данных, в которой содержится минимальной набор информации. С помощью элемента данных выполняется построение всех остальных структур (аналог поля).
2. Агрегат данных – совокупность данных внутри записи, имеющая имя, причем эта совокупность рассматривается как единое целое. Агрегаты бывают простые и сложные.
3. Запись – поименованная совокупность элементов и агрегатов.
4. Групповое отношение.
5. База данных – поименованная совокупность записей различного типа, содержащая ссылки между записями, представленные экземплярами наборов.
Основные ограничения ИМ:
1. возможны связи 1:М и 1:1;
2. создаваемая структура д.б. древовидной.
Исходя из этих ограничений, ИМ должна удовлетворять условия:
1. на первом уровне иерархии м.б. только один узел называемый корневым;
2. вершины (узлы) на нижних уровнях называются порожденными или зависимыми;
3. каждый порожденный узел, находящийся на i-ом уровне связан только с одним исходным узлом, находящимся на (i –1)-ом уровне;
4. каждый исходный узел может иметь 1 или несколько порожденных узлов называемых подобными;
5. существует единственный путь доступа к узлу начиная от корня дерева.
6. иерархия всегда начинается от корня.
Применение ИМ не вызовет трудностей только в том случае если данные имеют естественную древовидную структуру. В принципе каждая сетевая модель м.б. представлена средствами ИМ, при этом сеть разбивается на несколько деревьев, а каждая сетевая запись разбивается на несколько иерархических записей. ИМ наряду со своими преимуществами может вызывать затруднения при выполнении основных операций, например,:
1. невозможно добавить информацию на самый нижний уровень без введения фиктивных верхних уровней;
2. удаление средних уровней или их редактирование может привести к потере связей;
3. при поиске информации сложность вызывает асимметрия модели.
+: простота, независимость данных, min расходы памяти; -: не универсальность, избыточность.
Реляционная модель
В основе РМ использовано понятие «отношение».
Отношение – дана совокупность множеств D1…Dn, отношение R определенное на n-множествах, есть множество упорядоченных строк (картежей) d1…dn, таких что:
Dn., D1, Dn – домены отношений, n – степень отношений.
Домен – множество значений, из которых извлекаются фактические значения, используемые в столбце (поле это не домен в чистом виде, это маленькая его часть).
В РМ сущность представлена отношением, атрибут – элементом домена, связь – самостоятельным отношением либо доменом внутри отношения.
Реляционная модель ориентирована на организацию данных в виде двумерных таблиц. Каждая реляционная таблица представляет собой двумерный массив и обладает следующими свойствами: каждый элемент таблицы – один элемент данных; все столбцы в таблице однородные, т.е. все элементы в столбце имеют одинаковый тип и длину; каждый столбец имеет уникальное имя; одинаковые строки в таблице отсутствуют; порядок следования строк и столбцов м.б. произвольным.
Отношения представлены в виде таблиц, строки которых соответствуют кортежам или записям, столбцы – атрибутам отношений, доменам, полям.
Ограничения модели:
1. модель позволяет реализовать связи «1:1» и «1: M»;
2. значение каждого атрибута в каждой строке является неделимым, т.е. оно должно состоять из одного значения, а не из множеств. Если это выполняется, то отношение называется нормализованным.
РМ БД – есть представление пользователя этой БД в виде совокупности изменяемых во времени нормализованных отношений различных степеней.
Реляционная БД задается реляционной схемой, состоящей из одной или нескольких схем отношений. Схема отношения задается именем отношения и именами соответствующих доменов. При создании реляционной БД каждая схема отношений представляется в виде таблицы, каждый столбец таблицы называется атрибутом. Отношения в БД обладают свойствами множеств. В табличном представлении отношений есть ограничение: дублирование строк не допускается. Это ограничение приводит к введению понятия ключа. Ключ подмножество атрибутов, совокупность значений которых уникально идентифицирует картеж. Отношение может иметь несколько ключей, называемых возможными ключами. Для выбора ключа отношения используют два свойства:
1) значения ключа уникально идентифицируют картеж отношения, т.е. не $ двух строк, которые имели бы равные значения атрибутов, входящих в ключ и рассматриваемых как единое целое;
2) никакое подмножество атрибутов ключа, которое образуется при удалении из ключа любого атрибута, не обладает свойством 1).
После выбора ключевого атрибута необходимо помнить, что первичный ключ отличается от возможных ключей по операциям, которые над ним допустимы: первичный ключ нельзя обновлять; ни один из атрибутов первичного ключа не может принимать значение «не определено».
В реляционных моделях $ внутренние ограничения, накладываемые на атрибуты и на картежи:
1. специфицируется область значений атрибутов, определяющая допустимый тип значений;
2. $ возможность задания домена сравнимости, применяемого для указания осмысленности сравниваемых значений, если два атрибута не имеют общего домена сравнимости, их нельзя сравнивать или использовать в операции сравнения;
3. общие ограничения, которые м.б. заданы посредством утверждений (условий, которым должна удовлетворять БД).
Атрибут отношения R является внешним ключом, если этот атрибут не является первичным ключом отношения R, но его значения являются значениями первичного ключа отношения R1 (другого отношения).
+: простота, независимость данных от программы их реализации, теоретическое обоснование (нормализация отношений); -: низкое быстродействие, большой расход памяти.
Расширенная (посреляционная модель)
Важным аспектом традиционной реляционной модели данных является тот факт, что элементы данных, которые хранятся на пересечении строк и столбцов таблицы, должны быть неделимы и единственны. Это значит, что данные не могут быть развернуты в процессе дальнейшей обработки. Такое правило было заложено в основу реляционной алгебры при ее разработке как математической модели данных. Дальнейшие исследования показали, что существует ряд случаев, когда ограничения классической реляционной модели существенно мешают эффективной реализации приложений.
При том, что таблицы, строки и колонки так удобно отражают наше мышление, почему же они стали самоограничивающими для более крупных приложений? В основе проблемы лежат три вопроса:
1. работа с полями переменной длины и группами записей;
2. управление отношениями между таблицами и полями;
3. и отражение подлинно семантического содержания реальных структур, которые будут моделированы базой данных.
Основной принцип реляционной модели - устранять повторяющиеся поля и группы с помощью процесса, который называется нормализацией. Так как нормализация - это простой процесс, результат часто заключается в отображении единичных файлов в реляционных таблицах. Результат как непрост в понимании, так и неэффективен в обработке.
Опыт разработки прикладных информационных систем показал, что отказ от этой установки ведет к качественно полезному расширению модели данных. Если допустить, что значение данных может само состоять из подзначений, то в результате возникает понятие многозначного поля. Проще всего рассматривать набор многозначных полей в таблице как самостоятельную вложенную (nested) таблицу.
При условии, что вложенная таблица удовлетворяет общим критериям (например, имеет уникальный ключ), естественным образом происходит расширение операторов реляционной алгебры. Такая модель данных была названа постреляционной. Многие методологии проектирования данных позволяют определять многозначные поля и затем удалять в процессе нормализации. При этом таблицы преобразуются в первую нормальную форму или 1NF. Однако удаление многозначных полей не всегда способствует улучшению прикладных программ. В случаях, когда обычная форма доступа к полю подразумевает обращение ко всем его значениям, базе данных 1NF придется проделать операцию соединения (Join) каждый раз, когда нужно получить соответствующие значения, хранящиеся в другой таблице. Совершенно очевидно, что в подобной ситуации хранение значений физически в многозначных полях может обеспечить более эффективный доступ к информации.
На рис. 2 наглядно продемонстрированы преимущества хранения данных в базах uniVerse, относящихся к непервой нормальной форме, перед более громоздким хранением в базах данных первой нормальной формы. Пример представляет хранение части данных такого типичного документа, как накладная.

Рис. 2a. Представление данных в 1-й нормальной форме (1NF)
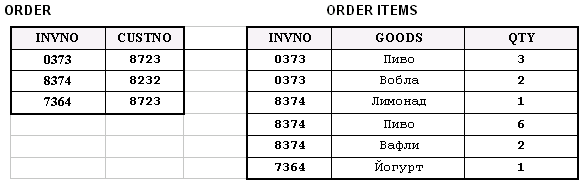
Рис. 2в. Структура хранения данных в uniVerse NFNF (NF2)

Рисунок 2. Структуры хранения данных с многозначными полями в uniVerse и в традиционных системах.
О таблицах, содержащих многозначные поля, говорят, что они находятся в непервой нормальной форме, или NF2 (Non First Normal Form). Как было замечено ранее, при условии, что используемые поля подчиняются определенным правилам, позволяющим обращаться с ними, как с таблицами, встроенными в другие таблицы, форма NF2 не нарушает принципы реляционной алгебры. Более того, такая информация полностью доступна, так как расширенные операторы, которые работают с таблицами NF2, позволяют извлекать встроенные таблицы и рассматривать данные как информацию, поступившую из таблиц 1NF. И все же во многих случаях форма 1NF будет скорее исключением, а не правилом. В большинстве случаев гораздо более эффективно осуществлять доступ к многозначным полям одновременно с остальными данными, зная, что их всегда можно извлечь и рассматривать как отдельную таблицу в тех случаях, когда это может понадобиться.
Многомерная модель
Достаточно очевидно, что даже при небольших объемах данных отчет, представленный в виде двухмерной таблицы (Модели автомобиля по оси Y и Время по оси X), нагляднее и информативнее отчета с реляционной построчной формой организации (рис. 1).
Реляционная модель
| Модель | Месяц | Объем |
| "Жигули" | Июнь | 12 |
| "Жигули" | Август | 5 |
| "Москвич | Июнь | 2 |
| "Москвич" | Июль | 18 |
| "Волга" | Июль | 19 |
Многомерная модель td>
| Июнь | Июль | Август | |
| "Жигули" | 12 | 5 | |
| "Москвич" | 2 | 18 | |
| "Волга" | 19 |
Рисунок 1. (Реляционная и многомерная модели представления данных).
А теперь представим, что у нас не три модели, а 30 и не три, а 12 различных месяцев. В случае построчного (реляционного) представления мы получим отчет в 360 строк (30х12), который займет не менее 5-6 страниц. В случае же многомерного (в нашем случае двухмерного) представления мы получим достаточно компактную таблицу 12 на 30, которая вполне уместится на одной странице и которую, даже при таком объеме данных, можно реально оценивать и анализировать
Основными понятиями, с которыми оперирует пользователь и проектировщик в многомерной модели данных, являются:
• измерение (Dimension);
• ячейка (Cell).
Иногда вместо термина "Ячейка" используется термин "Показатель" (Measure).
Измерение - это множество однотипных данных, образующих одну из граней гиперкуба. Например - Дни, Месяцы, Кварталы, Годы - это наиболее часто используемые в анализе временные Измерения. Примерами географических измерений являются: Города, Районы, Регионы, Страны и т.д.
В многомерной модели данных Измерения играют роль индексов, используемых для идентификации конкретных значений (Показателей), находящихся в Ячейках гиперкуба.
В свою очередь, Показатель - это поле (обычно цифровое), значения которого однозначно определяются фиксированным набором Измерений. В зависимости от того, как формируются его значения, Показатель может быть определен, как:
Переменная (Variable) - значения таких Показателей один раз вводятся из какого-либо внешнего источника или формируются программно и затем в явном виде хранятся в многомерной базе данных (МБД)
Формула (Formula) - значения таких Показателей вычисляются по некоторой заранее специфицированной формуле.
То есть для Показателя, имеющего тип Формула, в БД хранится не его значения, а формула, по которой эти значения могут быть вычислены.
Заметим, что это различие существует только на этапе проектирования и полностью скрыто от конечных пользователей. В примере на рис. 1 каждое значение поля Объем продаж однозначно определяется комбинацией полей:
Модель автомобиля;
Месяц продаж.
Но в реальной ситуации для однозначной идентификации значения Показателя, скорее всего, потребуется большее число измерений, например:
Модель автомобиля;
Менеджер;
Время (например Год).
Измерения:
Время (Год) - 1994, 1995, 1995
Менеджер - Петров, Смирнов, Яковлев
Показатель:
Объем Продаж
И в терминах многомерной модели речь будет идти уже не о двухмерной таблице, а о трехмерном гиперкубе:
первое Измерение - Модель автомобиля;
второе Измерение - Менеджер, продавший автомобиль;
третье Измерение - Время (Год);
на пересечении граней которого находятся значения Показателя Объем продаж.
Заметим, что, в отличие от Измерений, не все значения Показателей должны иметь и имеют реальные значения. Например, Менеджер Петров в 1994 г. мог еще не работать в фирме, и в этом случае все значения Показателя Объем продаж за этот год будут иметь неопределенные значения.
Гиперкубические и поликубические модели данных
В различных МСУБД используются два основных варианта организации данных:
• Гиперкубическая модель;
• Поликубическая модель.
В чем состоит разница? Системы, поддерживающие Поликубическую модель (примером является Oracle Express Server), предполагают, что в МБД может быть определено несколько гиперкубов с различной размерностью и с различными Измерениями в качестве их граней. Например, значение Показателя Рабочее Время Менеджера, скорее всего, не зависит от Измерения Модель Автомобиля и однозначно определяется двумя Измерениями: День и Менеджер. В Поликубической модели в этом случае может быть объявлено два различных гиперкуба:
Двухмерный - для Показателя Рабочее Время Менеджера;
Трехмерный - для Показателя Объем Продаж.
В случае же Гиперкубической модели предполагается, что все Показатели должны определяться одним и тем же набором Измерений. То есть только из-за того, что Объем Продаж определяется тремя Измерениями, при описании Показателя Рабочее Время Менеджера придется также использовать три Измерения и вводить избыточное для этого Показателя Измерение Модель Автомобиля.
Операции манипулирования Измерениями
Формирование "Среза". Пользователя редко интересуют все потенциально возможные комбинации значений Измерений. Более того, он практически никогда не работает одновременно сразу со всем гиперкубом данных. Подмножество гиперкуба, получившееся в результате фиксации значения одного или более Измерений, называется Срезом (Slice). Например, если мы ограничим значение Измерения Модель Автомобиля = "ВАЗ2108", то получим подмножество гиперкуба (в нашем случае - двухмерную таблицу), содержащее информацию об истории продаж этой модели различными менеджерами в различные годы.
Операция "Вращение". Изменение порядка представления (визуализации) Измерений (обычно применяется при двухмерном представлении данных) называется Вращением (Rotate). Эта операция обеспечивает возможность визуализации данных в форме, наиболее комфортной для их восприятия. Например, если менеджер первоначально вывел отчет, в котором Модели автомобилей были перечислены по оси X, а Менеджеры по оси Y, он может решить, что такое представление мало наглядно, и поменять местами координаты (выполнить Вращение на 90 градусов).
Отношения и Иерархические Отношения.
В нашем примере значения Показателей определяются только тремя измерениями. На самом деле их может быть гораздо больше и между их значениями обычно существуют множество различных Отношений (Relation) типа "один ко многим". Например, каждый Менеджер может работать только в одном подразделении, а каждой модели автомобиля однозначно соответствует фирма, которая ее выпускает:
Менеджер ->Подразделение;
Модель Автомобиля ->Фирма-Производитель.
Заметим, что для Измерений, имеющих тип Время (таких как День, Месяц, Квартал, Год), все Отношения устанавливаются автоматически, и их не требуется описывать. В свою очередь, множество Отношений может иметь иерархическую структуру - Иерархические Отношения (Hierarchical Relationships). Вот только несколько примеров таких Иерархических Отношений:
День -> Месяц -> Квартал -> Год;
Менеджер -> Подразделение -> Регион -> Фирма -> Страна;
Модель Автомобиля -> Завод-Производитель -> Страна.
И часто более удобно не объявлять новые Измерения и затем устанавливать между ними множество Отношений, а использовать механизм Иерархических Отношений. В этом случае все потенциально возможные значения из различных Измерений объединяются в одно множество. Например, мы можем добавить к множеству значений Измерения Менеджер ("Петров", "Сидоров", "Иванов", "Смирнов"), значения Измерения Подразделение ("Филиал 1", "Филиал 2", "Филиал 3") и Измерения Регион ("Восток", "Запад") и затем определить между этими значениями Отношение Иерархии.
Операция Агрегации.
С точки зрения пользователя, Подразделение, Регион, Фирма, Страна являются точно такими же Измерениями, как и Менеджер. Но каждое из них соответствует новому, более высокому уровню агрегации значений Показателя Объем продаж. В процессе анализа пользователь не только работает с различными Срезами данных и выполняет их Вращение, но и переходит от детализированных данных к агрегированным, т.е. производит операцию Агрегации (Drill Up). Например, посмотрев, насколько успешно в 1995 г. Петров продавал модели "Жигули" и "Волга", управляющий может захотеть узнать, как выглядит соотношение продаж этих моделей на уровне Подразделения, где Петров работает. А затем получить аналогичную справку по Региону или Фирме. Операция Детализации.
Переход от более агрегированных к более детализированным данным называется операцией Детализации (Drill Down). Например, начав анализ на уровне Региона, пользователь может захотеть получить более точную информацию о работе конкретного Подразделения или Менеджера.
Объектная модель
Сразу же необходимо заметить, что общепринятого определения "объектно-ориентированной модели данных" не существует. Сейчас можно говорить лишь о неком "объектном" подходе к логическому представлению данных и о различных объектно-ориентированных способах его реализации.
Мы знаем, что любая модель данных должна включать три аспекта: структурный, целостный и манипуляционный. Посмотрим, как они реализуются на основе объектно-ориентированная парадигмы программирования:
Структура: Структура объектной модели описываются с помощью трех ключевых понятий:
инкапсуляция - каждый объект обладает некоторым внутренним состоянием (хранит внутри себя запись данных), а также набором методов - процедур, с помощью которых (и только таким образом) можно получить доступ к данным, определяющим внутреннее состояние объекта, или изменить их. Таким образом, объекты можно рассматривать как самостоятельные сущности, отделенные от внешнего мира.
наследование - подразумевает возможность создавать из классов объектов новые классы объекты, которые наследуют структуру и методы своих предков, добавляя к ним черты, отражающие их собственную индивидуальность. Наследование может быть простым (один предок) и множественным (несколько предков).
полиморфизм - различные объекты могут по-разному реагировать на одинаковые внешние события в зависимости от того, как реализованы их методы. Пример:
Begin
Point A(100,100);
CircleB(200,200,50);
A.Draw(); // рисует точку
B.Draw(); // рисует окружность
End.
Целостность данных:
Для поддержания целостности объектно-ориентированный подход предлагает использовать следующие средства:
автоматическое поддержание отношений наследования
возможность объявить некоторые поля данных и методы объекта как "скрытые", не видимые для других объектов; такие поля и методы используются только методами самого объекта создание процедур контроля целостности внутри объекта
Средства манипулирования данными:
К сожалению, в объектно-ориентированном программировании отсутствуют общие средства манипулирования данными, такие как реляционная алгебра или реляционное счисление. Работа с данными ведется с помощью одного из объектно-ориентированных языков программирования общего назначения, обычно это SmallTalk, C++ или Java.