 2020-01-15
2020-01-15 199
199Средствами операционной системы Windows можно узнать достаточно много информации об оборудовании, памяти (функция GlobalMemoryStatus), жёстких дисках (функция GetDiskFreeSpace), сети и мониторе (функция GetSystemMetrics при различных параметрах), программном окружении (функции GetComputerName и GetUserName) и о многом другом. Подробное описание функций и примеры их использования можно найти в справочной системе MSDN.
Для определения таких параметров процессора, как фирма производитель, наличие расширений, количества и параметров кэшей команд и данных, TLB и других параметров в случае архитектур x86 используется инструкция процессора cpuid, которая имеет интерфейс на языке С/С++ __cpuid. Так для определения идентификатора процессора имеет место следующий код:
#include <intrin.h> // подключение описания функции __cpuid
…
int CPUInfo[4];
char CPUString[32];
__cpuid(CPUInfo, 0);
memset(CPUString, 0, sizeof(CPUString));
*((int*)CPUString) = CPUInfo[1];
*((int*)(CPUString+4)) = CPUInfo[3];
*((int*)(CPUString+8)) = CPUInfo[2];
printf(" CPU vendor: %s\n",CPUString);
…
Первый параметр функции __cpuid – 4-х элементный целочисленный массив, который соответствует регистрам eax, ebx, ecx, edx после выполнения инструкции. Второй параметр функции – номер функции инструкции. Подробная информация о номерах функций инструкции cpuid и содержимом регистров приведена в документах [1,2] для процессоров Intel и AMD. Так например с помощью функций 0x80000002, 0x80000003, 0x80000004 можно узнать полное название процессора.
Задание.
1. В соответствии с вариантом задания записать представление целого числа в типе char и вещественного числа в типе float (Обязательное задание – 5 баллов).
2. С помощью функций WinAPI определить информацию об оперативной памяти (Дополнительное задание – 1 балл).
3. С помощью функций WinAPI определить информацию о памяти на одном из жёстких дисков (Дополнительное задание – 2 балла).
4. С помощью инструкции cpuid определить название процессора (Дополнительное задание – 2 балла).
5. Крайний срок сдачи – 1 апреля 2011 года.
Варианты.
1. Целое число –12, вещественное число 12.5.
2. Целое число –23, вещественное число 12.125.
3. Целое число –56, вещественное число 12.25.
4. Целое число –78, вещественное число 12.75.
5. Целое число –89, вещественное число 12.625.
6. Целое число –90, вещественное число 24.5.
7. Целое число –21, вещественное число 24.125.
8. Целое число –45, вещественное число 24.25.
9. Целое число –78, вещественное число 24.75.
10. Целое число –86, вещественное число 24.625.
Лабораторная работа № 2
Исследование кэш-памяти и обхода памяти
Цель работы. Сравнение различных способов обхода памяти, программное определение размера и степени ассоциативности кэш-памяти различных уровней.
Методические указания.
Кэш-память
Кэш-память является промежуточным хранилищем данных между процессором и оперативной памятью. Она содержит копии наиболее часто используемых блоков данных из оперативной памяти. Размер кэш-памяти составляет от нескольких килобайт до нескольких мегабайт, а скорость доступа к ней в несколько раз превосходит скорость доступа к оперативной памяти, но уступает скорости обращения к регистрам. Каждый раз, когда к ячейке оперативной памяти происходит обращение (чтение или запись), ее копия заносится в кэш-память, вытеснив при этом оттуда копию другой ячейки. Поэтому повторное обращение к той же ячейке произойдет быстрее. Значения переменных программы и небольшие массивы, для которых не нашлось места в регистрах, обычно располагаются в кэш-памяти. Большие массивы могут поместиться в кэш-память только частично. Допустим, некоторая программа производит многократную обработку элементов массива. Если построить график зависимости времени обработки массива от размера массива, то он должен иметь нелинейный характер. При превышении размера кэш-памяти время обращения к элементам массива несколько возрастет (на графике будет наблюдаться скачок). Данные из оперативной памяти в кэш-память (и обратно) считываются целыми строками. Размер кэш-строки в большинстве распространенных процессоров составляет 16, 32, 64, 128 байт. При последовательном обходе попытка чтения первого элемента кэш-строки вызывает копирование всей строки из медленной оперативной памяти в кэш. Чтение нескольких последующих элементов выполняется намного быстрее, т.к. они уже находятся в быстрой кэш-памяти. В большинстве современных микропроцессорах реализована аппаратная предвыборка данных. Ее суть состоит в том, что при последовательном обходе очередные кэш-строки копируются из оперативной памяти в кэш-память еще до того, как к ним произошло обращение. За счет этого скорость последовательного обхода данных еще возрастает.
Большинство современных микропроцессоров имеют множественно-ассоциативную (наборно-ассоциативную) организацию кэш-памяти. При множественно-ассоциативной организации кэш-память разделена на несколько банков, и каждый блок данных из оперативной памяти может быть помещен в одну из определенного множества (набора) строк кэш-памяти. Число строк в множестве определяется числом банков. Схема кэш-памяти данных первого уровня на Pentium III (16 Кб):
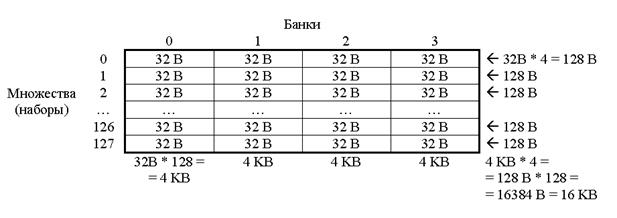
Рисунок 5.
В какой конкретный элемент множества строка будет записана, определяется алгоритмом замещения (циклический, случайный, LRU, псевдо-LRU, …). Таким образом, блоки, отстоящие на определенное расстояние в памяти (в примере: на 212 B = 4096 B = 4 KB), помещаются в одно и то же множество строк. Число элементов в каждом множестве (число банков) называется степенью ассоциативности кэш-памяти. Например, кэш данных L1 в Pentium III имеет объем 16 KB, степень ассоциативности 4 (4-way set-associative), размер строки 32B:
16KB = 4-way * 4 KB = 4-way * 128 множеств * 32B
Данные, расположенные в памяти с шагом на расстоянии 4KB приходятся на одно множество. На все эти данные приходится всего 4 кэш-строки, т.е. 4 * 32 = 128 B. Если выполнять обход данных с шагом 4 KB, то из всех 16 KB кэша L1 будет использоваться всего 128 B, которые будут постоянно перезаписываться (эффект «буксования» кэша). Производительность при этом будет такая же, как при отсутствии кэш-памяти. Если вычислительная система имеет несколько уровней кэш-памяти, то у каждого уровня может быть своя степень ассоциативности. Определить степени ассоциативности кэш-памяти можно следующим способом. Выполняется обход N блоков данных суммарным объемом BlockSize, отстоящих друг от друга на величину Offset:

Рисунок 6.
BlockSize должен быть не больше объема исследуемого уровня кэш-памяти. Offset должно быть кратно величине «размер кэша» / «ассоциативность», т.е. кратно размеру банка ассоциативности. Как правило, это степени двоек, так что можно взять заведомо кратное такому значению расстояние (например, 1MB). Изменяя число частей N, мы увидим, как меняется время обхода. Когда N превысит число банков, время обхода сильно возрастет.
Обход элементов следует производить в таком порядке:
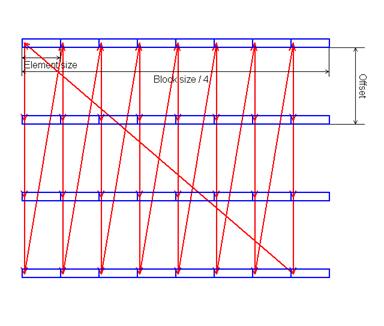
Рисунок 7.








