 2020-01-15
2020-01-15 176
176Инициализация памяти
| Имя функции | Операция | Инструкция |
| _mm_load_ss | загрузить младшее значение и очистить остальные три значения | MOVSS |
| _mm_load1_ps | загрузить одно значение во все четыре позиции | MOVSS + Shuffling |
| _mm_load_ps | Загрузить четыре значения по выровненному адресу | MOVAPS |
| _mm_loadu_ps | Загрузить четыре значения по невыровненному адресу | MOVUPS |
| _mm_loadr_ps | Загрузить четыре значения в обратном порядке | MOVAPS + Shuffling |
Инициализация значений
| Имя функции | Операция | Инструкция |
| _mm_set_ss | устанавливает самое младшее значение и обнуляет три остальных | составная |
| _mm_set1_ps | устанавливает четыре позиции в одно значение | составная |
| _mm_set_ps | устанавливает четыре значения, выровненные по адресу | составная |
| _mm_setr_ps | устанавливает четыре значения в обратном порядке | составная |
| _mm_setzero_ps | Обнуляет все четыре значения | составная |
Операции записи
| Имя функции | Операция | Инструкция |
| _mm_store_ss | записать младшее значение | MOVSS |
| _mm_store1_ps | записать младшее значение во все четыре позиции | MOVSS + Shuffling |
| _mm_store_ps | записать четыре значения по выровненному адресу | MOVAPS |
| _mm_storeu_ps | записать четыре значения по невыровненному адресу | MOVUPS |
| _mm_storer_ps | записать четыре значения в обратном порядке | MOVAPS + Shuffling |
| _mm_move_ss | записать младшее значение и оставить без изменения три остальных значения | MOVSS |
Поддержка кэш-памяти в SSE
| Имя функции | Операция | Инструкция |
| _mm_prefetch | Загружает одну кэш-строку по указанному адресу в кэш-память | PREFETCH |
| _mm_stream_pi | Записывает данные в память без записи в кэш | MOVNTQ |
| _mm_stream_ps | Записывает данные в память без записи в кэш по адресу, выровненному по 16 байт | MOVNTPS |
| _mm_sfence | Гарантирует, что все предшествующие записи в память завершатся до следующей записи. | SFENCE |
Использование встроенных функций SSE в программе на языке Си
// скалярное произведение векторов
#include <stdio.h>
#include <xmmintrin.h>
#define N 10000000
// «обычная» функция
float inner1(float *x,float *y,int n)
{
float s;
int i;
s=0;
for(i=0;i<n;i++)
s+=x[i]*y[i];
return s;
}
// функция с использованием SSE intrinsics
float inner2(float *x,float *y,int n)
{
float sum;
int i;
__m128 *xx,*yy;
__m128 p,s;
xx=(__m128 *)x;
yy=(__m128 *)y;
s=_mm_set_ps1(0);
for (i=0;i<n/4;i++)
{
p=_mm_mul_ps(xx[i], yy[i]); // векторное умножение четырех чисел
s=_mm_add_ps(s,p); // векторное сложение четырех чисел
}
p=_mm_movehl_ps(p,s); // перемещение двух старших значений s в младшие p
s=_mm_add_ps(s,p); // векторное сложение
p=_mm_shuffle_ps(s,s,1);//перемещение второго значения в s в младшую позицию в p
s=_mm_add_ss(s,p); // скалярное сложение
_mm_store_ss(&sum,s); // запись младшего значения в память
return sum;
}
int main()
{
float *x,*y, s;
long t;
int i;
// выделение памяти с выравниванием
x=(float *)_mm_malloc(N*sizeof(float),16);
y=(float *)_mm_malloc(N*sizeof(float),16);
for (i=0;i<N;i++)
{
x[i]=10*i/N;
y[i]=10*(N-i-1)/N;
}
// Using x87
s=inner1(x,y,N);
printf("Result: %f\n",s);
// Using SSE
s=inner2(x,y,N);
printf("Result: %f\n",s);
_mm_free(x);
_mm_free(y);
return 0;
}
Задание.
1. Реализовать процедуру умножения квадратных матриц (размером кратным четырём) без использования специальных расширений и с использованием расширений SSE, сравнить время выполнения этих реализаций (Обязательное задание – 10 баллов).
2. В соответствии с вариантом задания реализовать матрично-векторную (с одинаковым размером матриц и векторов кратным четырём) процедуру с использованием расширений SSE (Дополнительное задание – 7 баллов).
3. С использованием инструкции cpuid определить наличие расширения SSE (Дополнительное задание – 3 балла).
4. Крайний срок сдачи – 7 мая 2011 года.
Варианты.
В предложенных вариантах предполагается, что 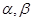 – скаляры,
– скаляры, 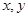 – векторы,
– векторы, 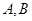 – матрицы:
– матрицы:
1. Операция 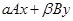 .
.
2. Операция 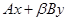 .
.
3. Операция 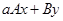 .
.
4. Операция 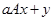 .
.
5. Операция 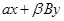 .
.
6. Операция 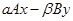 .
.
7. Операция 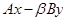 .
.
8. Операция 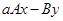 .
.
9. Операция 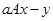 .
.
10. Операция 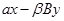 .
.








