 2020-01-15
2020-01-15 167
167Применение критериев, основанных на статистиках, имеющих при нулевой гипотезе  -распределение Фишера (F-критерии), отнюдь не ограничивается только что рассмотренным анализом статистической значимости регрессии. Такие критерии широко применяются в процессе подбора модели.
-распределение Фишера (F-критерии), отнюдь не ограничивается только что рассмотренным анализом статистической значимости регрессии. Такие критерии широко применяются в процессе подбора модели.
Пусть мы находимся в рамках множественной линейной модели регрессии

c  объясняющими переменными, и гипотеза
объясняющими переменными, и гипотеза  состоит в том, что в модели
состоит в том, что в модели  последние
последние 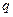 коэффициентов равны нулю, т. е.
коэффициентов равны нулю, т. е.

Тогда при гипотезе (т. е. в случае, когда она верна) мы имеем редуцированную модель

уже с  объясняющими переменными.
объясняющими переменными.
Пусть  - остаточная сумма квадратов в полной модели , а
- остаточная сумма квадратов в полной модели , а  — остаточная сумма квадратов в редуцированной модели
— остаточная сумма квадратов в редуцированной модели  . Если гипотеза верна и выполнены стандартные предположения о модели (в частности,
. Если гипотеза верна и выполнены стандартные предположения о модели (в частности,  ~ i. i. d.
~ i. i. d.  ), то тогда F- статистика
), то тогда F- статистика

рассматриваемая как случайная величина, имеет при гипотезе H 0 (т. е. когда действительно q p = q p- 1 = ¼= q p-q+ 1 = 0) F-распределение Фишера F (q, n-p) с q и (n-p) степенями свободы.
В рассмотренном ранее случае проверки значимости регрессии в целом мы имели  , и при этом там имело равенство
, и при этом там имело равенство  которое не выполняется в общем случае.
которое не выполняется в общем случае.
Пусть
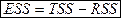 — сумма квадратов, объясняемая полной моделью ,
— сумма квадратов, объясняемая полной моделью ,
 — сумма квадратов, объясняемая редуцированной моделью .
— сумма квадратов, объясняемая редуцированной моделью .
Тогда

так что - статистику можно записать в виде

из которого следует,что F-статистика измеряет, в соответствующем масштабе, возрастание объясненной суммы квадратов вследствие включения в модель дополнительного количества объясняющих переменных.
Естественно считать, что включение дополнительных переменных существенно, если указанное возрастание объясненной суммы квадратов достаточно велико. Это приводит нас к критерию проверки гипотезы
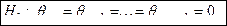
основанному на F-статистике

и отвергающему гипотезу , когда наблюдаемое значение этой статистики удовлетворяет неравенству

где  — выбранный уровень значимости критерия (вероятность ошибки 1-го рода).
— выбранный уровень значимости критерия (вероятность ошибки 1-го рода).
Пример. В следующей таблице приведены данные по США о следующих макроэкономических показателях:
 — годовой совокупный располагаемый личный доход;
— годовой совокупный располагаемый личный доход;
 — годовые совокупные потребительские расходы;
— годовые совокупные потребительские расходы;
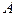 — финансовые активы населения на начало календарного года
— финансовые активы населения на начало календарного года
(все показатели указаны в млрд. долларов, в ценах 1982 г.).
| obs | C82 | DPI82 | A82 | 1971 | 1540.3 | 1730.1 | 1902.8 |
| 1966 | 1300.5 | 1433.0 | 1641.6 | 1972 | 1622.3 | 1797.9 | 2011.4 |
| 1967 | 1339.4 | 1494.9 | 1675.2 | 1973 | 1687.9 | 1914.9 | 2190.6 |
| 1968 | 1405.9 | 1551.1 | 1772.6 | 1974 | 1672.4 | 1894.9 | 2301.8 |
| 1969 | 1458.3 | 1601.7 | 1854.7 | 1975 | 1710.8 | 1930.4 | 2279.6 |
| 1970 | 1491.8 | 1668.1 | 1862.2 | 1976 | 1804.0 | 2001.0 | 2308.4 |
Рассмотрим модель наблюдений

где индексу  соответствует
соответствует  год. Это модель с 4 объясняющими переменными:
год. Это модель с 4 объясняющими переменными:
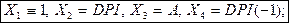
символ  обозначает переменную, значения которой запаздывают на одну единицу времени относительно значений переменной,
обозначает переменную, значения которой запаздывают на одну единицу времени относительно значений переменной, 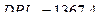 . Оценивание этой модели дает следующие результаты:
. Оценивание этой модели дает следующие результаты:




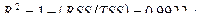
— статистика критерия проверки значимости регрессии в целом

Регрессия имеет очень высокую статистическую значимость. Вместе с тем, каждый из коэффициентов при двух последних переменных статистически незначим, так что, в частности, не следует придавать особого значения отрицательности оценок этих коэффициентов.
Используя — критерий, мы могли бы попробовать удалить из модели какую-нибудь одну из двух последних переменных, и если оставшиеся переменные окажутся значимыми, то остановиться на модели с 3 объясняющими переменными; если же и в новой модели окажутся статистически незначимые переменные, то произвести еще одну редукцию модели.
Рассмотрим, в этой связи, модель

с удаленной переменной . Для нее получаем:




F- статистика критерия проверки значимости регрессии в этой модели

Поскольку эдесь остается статистически незначимым коэффициент при переменной , можно произвести дальнейшую редукцию, переходя к модели

Для этой модели
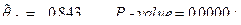


- статистика критерия проверки значимости регрессии в этой модели

и эту модель в данном контексте можно принять за окончательную.
С другой стороны, обнаружив при анализе модели 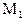 (посредством применения t-критериев) статистическую незначимость коэффициентов при двух последних переменных, мы можем попробовать выяснить возможность одновременного исключения из этой модели указанных объясняющих переменных, опираясь на использование соответствующего F-критерия.
(посредством применения t-критериев) статистическую незначимость коэффициентов при двух последних переменных, мы можем попробовать выяснить возможность одновременного исключения из этой модели указанных объясняющих переменных, опираясь на использование соответствующего F-критерия.
Исключение двух последних переменных из модели соответствует гипотезе
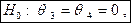
при которой модель редуцируется сразу к модели  . Критерий проверки гипотезы
. Критерий проверки гипотезы  основывается на статистике
основывается на статистике

где — остаточная сумма квадратов в модели , — остаточная сумма квадратов в модели , 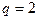 — количество зануляемых параметров,
— количество зануляемых параметров,  .
.
Для наших данных получаем значение

которое следует сравнить с критическим значением  Поскольку
Поскольку  , мы не отвергаем гипотезу
, мы не отвергаем гипотезу 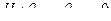 и можем сразу перейти от модели к модели
и можем сразу перейти от модели к модели  .
.
Замечание. В рассмотренном примере мы действовали двумя способами:
Дважды использовали - критерии, сначала приняв (не отвергнув) гипотезу  в рамках модели , а затем приняв гипотезу
в рамках модели , а затем приняв гипотезу  в рамках модели .
в рамках модели .
Однократно использовали F- критерий, приняв гипотезу  в рамках модели .
в рамках модели .
Выводы при этих двух альтернативных подходах оказались одинаковыми. Однако, из выбора модели в подобной последовательной процедуре, вообще говоря, не следует что такой же выбор будет обязательно сделан и при применении - критерия, сравнивающего первую и последнюю модели.
2.9. ПРОВЕРКА ЗНАЧИМОСТИ И ПОДБОР МОДЕЛИ С ИСПОЛЬЗОВАНИЕМ КОЭФФИЦИЕНТОВ
ДЕТЕРМИНАЦИИ. ИНФОРМАЦИОННЫЕ КРИТЕРИИ
Ранее мы неоднократно задавались вопросом о том, как следует интерпретировать значения коэффициента детерминации  с точки зрения их близости к нулю или, напротив, их близости к единице.
с точки зрения их близости к нулю или, напротив, их близости к единице.
Естественным было бы построение статистической процедуры проверки значимости линейной связи между переменными, основанной на значениях коэффициента детерминации — ведь является статистикой, поскольку значения этой случайной величины вычисляются по данным наблюдений. Теперь мы в состоянии построить такую статистическую процедуру.
Представим - статистику критерия проверки значимости регрессии в целом в виде

Отсюда находим:


Большим значениям статистики соответствуют и большие значения статистики , так что гипотеза  , отвергаемая при
, отвергаемая при  =
=  , должна отвергаться при выполнении неравенства
, должна отвергаться при выполнении неравенства  , где
, где

При этом, вероятность ошибочного отклонения гипотезы по-прежнему равна .
Интересно вычислить критические значения  при
при  для различного количества наблюдений.
для различного количества наблюдений.
Ограничимся здесь простой линейной регрессией 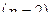 , так что
, так что

В зависимости от количества наблюдений  , получаем следующие критические значения :
, получаем следующие критические значения :
| n | 3 | 4 | 10 | 20 | 30 | 40 | 60 | 120 | 500 |
| R2crit | 0.910 | 0.720 | 0.383 | 0.200 | 0.130 | 0.097 | 0.065 | 0.032 | 0.008 |
Иначе говоря, при большом количестве наблюдений даже весьма малые отклонения наблюдаемого значения от нуля оказываются достаточными для того, чтобы признать значимость регрессии, т. е. статистическую значимость коэффициента при содержательной объясняющей переменной.
Поскольку же значение равно при  квадрату выборочного коэффициента корреляции между объясняемой и (нетривиальной) объясняющей переменными, то аналогичный вывод справедлив и в отношении величины этого коэффициента корреляции, только получаемые результаты еще более впечатляющи:
квадрату выборочного коэффициента корреляции между объясняемой и (нетривиальной) объясняющей переменными, то аналогичный вывод справедлив и в отношении величины этого коэффициента корреляции, только получаемые результаты еще более впечатляющи:
| n | 3 | 4 | 10 | 20 | 30 | 40 | 60 | 120 | 500 |
| | rxy | crit | 0.953 | 0.848 | 0.618 | 0.447 | 0.360 | 0.311 | 0.254 | 0.179 | 0.089 |
Если сравнивать модели по величине коэффициента детерминации R2, то с этой точки зрения полная модель всегда лучше (точнее, не хуже) редуцированной — значение R2 в полной модели всегда не меньше, чем в редуцированной, просто потому, что в полной модели остаточная сумма квадратов не может быть больше, чем в редуцированной.
Действительно, в полной модели с  объясняющими переменными минимизируется сумма
объясняющими переменными минимизируется сумма

по всем возможным значениям коэффициентов  . Если мы рассмотрим редуцированную модель, например, без -ой объясняющей переменной, то в этом случае минимизируется сумма
. Если мы рассмотрим редуцированную модель, например, без -ой объясняющей переменной, то в этом случае минимизируется сумма

по всем возможным значениям коэффициентов  , что равносильно минимизации первой суммы по всем возможным значениям при фиксированном значении
, что равносильно минимизации первой суммы по всем возможным значениям при фиксированном значении 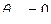 . Но получаемый при этом минимум не может быть больше чем минимум, получаемый при минимизации первой суммы по всем возможным значениям , включая и все возможные значения
. Но получаемый при этом минимум не может быть больше чем минимум, получаемый при минимизации первой суммы по всем возможным значениям , включая и все возможные значения  . Последнее означает, что в полной модели не может быть меньше, чем в редуцированной модели. Поскольку же полная сумма квадратов в обеих моделях одна и та же, отсюда и вытекает заявленное выше свойство коэффициента .
. Последнее означает, что в полной модели не может быть меньше, чем в редуцированной модели. Поскольку же полная сумма квадратов в обеих моделях одна и та же, отсюда и вытекает заявленное выше свойство коэффициента .
Чтобы сделать процедуру выбора модели с использованием более приемлемой, было предложено использовать вместо его скорректированный (adjusted) вариант
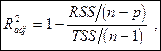
в который по-существу вводится штраф за увеличение количества объясняющих переменных. При этом,
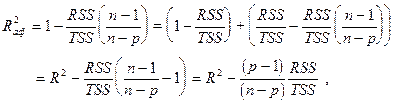
так что

при  и
и  .
.
При использовании коэффициента  для выбора между конкурирующими моделями, лучшей признается та, для которой этот коэффициент принимает максимальное значение.
для выбора между конкурирующими моделями, лучшей признается та, для которой этот коэффициент принимает максимальное значение.
Замечание. Если при сравнении полной и редуцированных моделей оценивание каждой из альтернативных моделей производится с использованием одного и того же количества наблюдений, то тогда, как следует из формулы, определяющей , сравнение моделей по величине равносильно сравнению этих моделей по величине  или по величине
или по величине  . Только в последних двух случаях выбирается модель с миниимальным значением
. Только в последних двух случаях выбирается модель с миниимальным значением  (или
(или  ).
).
Пример. Продолжая последний пример, находим значения коэффициента при подборе моделей , , :
для — 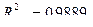
для — 
для — 
Таким образом, выбирая модель по максимуму , мы выберем из этих трех моделей именно модель , к которой мы уже пришли до этого, пользуясь - и -критериями.
В этом конкретном случае сравнение всех трех моделей по величине не равносильно сравнению их по величине  (или ), если модели , оцениваются по всем
(или ), если модели , оцениваются по всем  наблюдениям, представленным в таблице данных, тогда как модель оценивается только по
наблюдениям, представленным в таблице данных, тогда как модель оценивается только по  наблюдениям (одно наблюдение теряется из-за отсутствия в таблице запаздывающего значения
наблюдениям (одно наблюдение теряется из-за отсутствия в таблице запаздывающего значения  , соответствующего
, соответствующего  году).
году).
Наряду со скорректированным коэффициентом детерминации, для выбора между несколькими альтернативными моделями часто используют так называемые информационные критерии: критерий Акаике и критерий Шварца, также «штрафующие» за увеличение количества объясняющих переменных в модели, но несколько отличными способами.
Критерий Акаике (Akaike’s information criterion — AIC). При использовании этого критерия, линейной модели с объясняющими переменными, оцененной по  наблюдениям, сопоставляется значение
наблюдениям, сопоставляется значение
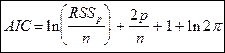
где  - остаточная сумма квадратов, полученная при оценивании коэффициентов модели методом наименьших квадратов. При увеличении количества объясняющих переменных первое слагаемое в правой части уменьшается, а второе увеличивается. Среди нескольких альтернативных моделей (полной и редуцированных) предпочтение отдается модели с наименьшим значением
- остаточная сумма квадратов, полученная при оценивании коэффициентов модели методом наименьших квадратов. При увеличении количества объясняющих переменных первое слагаемое в правой части уменьшается, а второе увеличивается. Среди нескольких альтернативных моделей (полной и редуцированных) предпочтение отдается модели с наименьшим значением  , в которой достигается определенный компромисс между величиной остаточной суммы квадратов и количеством объясняющих переменных.
, в которой достигается определенный компромисс между величиной остаточной суммы квадратов и количеством объясняющих переменных.
Критерий Шварца (Schwarz’s information criterion — SC, SIC). При использовании этого критерия, линейной модели с объясняющими переменными, оцененной по наблюдениям, сопоставляется значение








