 2020-01-14
2020-01-14 188
188Инициализация: Положить x0 = 0, и i = 0.
Шаг 1: Выбрать y в некоторой окрестности xi.
Шаг 2: Если ¦(y) < ¦(xi) установить xi+1 = y, перейти к шагу 4.
Шаг 3: Если (равномерно распределенное случайное число)< 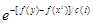 , установить xi+1 = y.
, установить xi+1 = y.
Шаг 4: Увеличить i на 1 и перейти к шагу 1.

здесь c(i) есть температура в момент времени i, и ¦ минимизируемая функция. В общем случае ожидается, что c(i) убывает до некоторого c¥ ¹ 0 при i ® ¥.
Для дискретного случая разработка этого алгоритма достаточно ясна. Достаточно только определить окрестность xi и функцию остывания c(i). Когда SA применяется к непрерывной задаче, идея окрестности даже более не ясна. Для непрерывного SA можно вначале определить направление поиска. Это делается путем случайного выбора точки на единичной гиперсфере с центром в xi, которая и дает нам нужное направление. После этого алгоритм выбирает случайную длину шага в этом направлении. Очевидным недостатком этой процедуры является то, что она не использует какую-либо локальную информацию (такую как дифференцируемость). Для учета этой проблемы предлагается случайным образом сочетать следующих два метода. Либо xi выбирается случайно, либо xi выбирается путем применения нескольких шагов поиска локального минимума для xi-1.
Методы кластеризации
Методы кластеризации (clustering methods) относятся к стохастическим методам. Метод кластеризации стартует с некоторой точки, случайно выбранной из области W, и затем создает группы или кластеры ближайших точек, соответствующих основной области притяжения. Кластер C есть множество точек, которое соответствуют области притяжения и имеет следующие свойства:
· C содержит ровно один локальный минимум x*.
· Любой алгоритм спуска, стартующий из точки x Î C, сходится к точке x*.
· Первые два свойства подразумевают, что C может содержать только одну стационарную точку.
Например, рассмотрим функцию (x 2 – 1)2, которая имеет глобальный минимум в точках x = ±1. Для нее существует два кластера. Первый кластер это { x | - 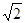 < x < 0}, и второй кластер это { x | 0< x < } (см. рис. 1). Любой метод спуска, стартующий в кластере 1, гарантированно сходится к точке x = -1. Аналогично, метод спуска, стартующий в кластере 2, гарантированно сходится к точке x = 1.
< x < 0}, и второй кластер это { x | 0< x < } (см. рис. 1). Любой метод спуска, стартующий в кластере 1, гарантированно сходится к точке x = -1. Аналогично, метод спуска, стартующий в кластере 2, гарантированно сходится к точке x = 1.


|
|

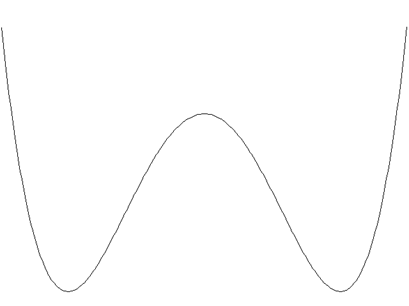
Методы кластеризации имеют несколько способов идентификации этих кластеров, но основной алгоритм один и тот же. Первоначально выбранная точка часто является точкой с минимальным значением функции, полученным до этого или локальным минимумом. Точки добавляются в этот кластер при помощи применения кластеризующего правила или пока не будет удовлетворен некоторый завершающий критерий. Методы различаются по кластеризующему правилу и по критерию завершения.
После проведения кластеризации из всех полученных локальных минимумов выбирается точка с наименьшим значением функции.








