 2020-01-14
2020-01-14 130
130
Основным компонентом созданной в рамках проекта системы является генератор — программа, которая по данной статистике строит дерево правил и переводит его в формат iptables. В этом же разделе будет представлена общая архитектура программы. Особенности строения отдельных правил будут разобраны в следующих главах.
В математическом описании алгоритма каждому узлу приписано определенное подмножество статистики, а каждому ребру — ЭВ или его дополнение. В генераторе правил ребер как таковых нет. Дерево представлено набором узлов, каждый из которых имеет указатели на своих потомков и своего предка. Каждому узлу приписан набор ключей соединений из статистики (массив целых чисел). Правило представляет собой описатель определенного свойства соединения (протокол, адрес, порт). Экземпляры классов правил содержат в себе пороговые значения, их можно считать представлением ЭВ в системе. Каждая вершина дерева содержит список правил, описывающих свойства множества соединений, приписанного ей. В корне дерева находятся правила, описывающие все возможные соединения. Для обеспечения расширяемости системы правила должны быть максимально отделены от остальной программы, но вместе с тем иметь полный доступ к соединениям, приписанным вершинам (но о самих вершинах они знать не должны).
Правила не должны иметь дело с контроллером статистик. Единственные данные, которыми они оперируют — это наборы соединений. Поэтому был определен интерфейс[1] Set, описывающий набор соединений и с произвольным доступом по локальным номерам и используемый правилами. DBVectorSet — класс, реализующий интерфейс Set. В методах этого класса локальный номер переводится в глобальный номер соединения в статистике, затем по этому номеру из базы данных извлекается описатель соединения. Правилам в качестве наборов соединений передаются указатели на экземпляры класса DBVectorSet. Интерфейс Set на языке С++ приведен в приложении А.
Само правило определяется как класс, реализующий интерфейс Rule. Основной его метод — compute. Он проводит поиск порогового значения, обеспечивающего наилучшее деление данного набора соединений данным правилом. Метод получает в качестве параметра множество соединений (указатель Set*), и возвращает числовое значение разности в весах двух частей, полученных при делении. Чем меньше разность — тем лучше. Полученные характеристики деления (пороговое значение, левое и правое подмножества, а также два дочерних правила, описывающие свойства левого и правого подмножеств) сохраняются в объекте правила и могут быть получены в дальнейшем с помощью специальных методов. Если не удалось найти такое пороговое значение, при котором хотя бы одно соединение из переданного множества удовлетворяет ЭВ, то будем говорить, что правило не прошло. Если для любого возможного порогового значения ЭВ удовлетворяют все соединения, то будем говорить, что правило прошло, но не дало деления (невырожденного). Для определения того, какое именно из правил вершины использовалось при делении, служит флаг активности правила. Также у правила есть метод, позволяющий получить его параметры в текстовом виде, пригодном для использования в командах iptables. В дополнение ко всему, определена процедура клонирования, позволяющая получить точную копию объекта правила. Интерфейс Rule на языке С++ приведен в приложении А.
Работа генератора состоит из двух основных частей: построение дерева и перевод дерева в формат iptables.
Построение дерева.
Первым этапом создается корень будущего дерева. Ему приписываются ключи всех соединений из статистики. Также создаются экземпляры правил с самыми широкими границами, возможными для каждого класса (все протоколы, все порты, все диапазоны адресов) и приписываются корню. После этого корень ставится в очередь обработки. Дальнейшие действия выполняются до тех пор, пока очередь не пуста.
Из очереди извлекается очередная вершина. У каждого из находящихся в ней правил вызывается метод compute, которому передается в качестве параметра множество соединений, приписанное вершине. Если хотя бы одно из правил не прошло, то работать с вершиной дальше нет смысла — она становится аномальным листом, и все ее правила помечаются как активные (смысл этого действия станет ясен позже). Если же все правила прошли успешно, то возможны два случая:
1. Ни одно правило не дало деления. Это означает, что мы имеем дело с нормальным листом, и все его правила также помечаются как активные.
2. Есть правила, дающие невырожденное деление. Тогда выбирается то из них, метод compute которого вернул наименьшее значение. Обозначим его через AR. Это правило помечается как активное. Создается два новых узла — левый и правый потомки текущего. Все неактивные правила клонируются в них без изменений. Активное правило не клонируется. Вместо этого левому потомку приписывается его левое дочернее правило, а правому потомку — его правое дочернее правило. Также левому потомку приписывается подмножество соединений, удовлетворяющее левому дочернему правилу AR (левое подмножество AR), а правому потомку приписываются все остальные соединения (правое подмножество AR). Так в программе реализуется деление множества соединений при помощи конкретного ЭВ. Две новые вершины добавляются в очередь.
Как видно, активным является то правило, по которому происходит деление. Нужно пояснить, зачем все правила листьев помечаются активными, если деления не происходит. Необходимость этого действия вытекает из того, что в статистике нет аномальных пакетов, и все листья должны быть однозначно идентифицированы либо как нормальные, либо как аномальные (см. алгоритм). Опишем ситуацию на примере. Пусть множество состоит из двух соединений — Conn1 и Conn2, и их параметры различаются только адресом отправителя: для Conn1 это A1, а для Conn2 — A2. Очевидно, что деление произойдет именно по этому полю. Мы получим две вершины, по одному соединению в каждой. И будет известно, какой адрес отправителя у обоих соединений (т.к. именно по этому правилу произошло деление). Но все остальные правила просто клонируются, поэтому нет пока никаких данных, например, о портах соединений. У правил портов этих вершин будет вызван метод compute, который не найдет деления, но обнаружит, что порт всего один. Если не определить правило портов как активное, эта информация будет утеряна, и в левый лист в дальнейшем будут попадать соединения с любым значением порта, имеющие адрес отправителя A1 (аналогично для правого листа). Что неверно, т.к. допускает попадание в нормальные листья аномальных соединений. Если же сделать правило портов активным, мы будем иметь информацию, что в этих двух листьях должны находиться соединения только с данным значением порта.
Как было задано в требованиях к системе, сложность построения должна быть полиномиальной. Без учета сложности правил сложность алгоритма можно оценить в лучшем случае как 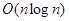 , а в худшем — как
, а в худшем — как 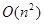 , где n — размер статистики. В первом случае всегда происходит равномерное деление, и получается
, где n — размер статистики. В первом случае всегда происходит равномерное деление, и получается 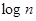 уровней по n соединений в каждом, во втором — всегда отделяется ровно одно соединение, и получается n уровней. Из разделов, посвященных конкретным правилам, станет ясно, что сложность метода compute любого из них не может превышать
уровней по n соединений в каждом, во втором — всегда отделяется ровно одно соединение, и получается n уровней. Из разделов, посвященных конкретным правилам, станет ясно, что сложность метода compute любого из них не может превышать 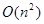 (на самом деле, в большинстве случаев она гораздо меньше и приближается к
(на самом деле, в большинстве случаев она гораздо меньше и приближается к 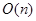 ). Таким образом, общая сложность алгоритма построения дерева правил оценивается в худшем случае как
). Таким образом, общая сложность алгоритма построения дерева правил оценивается в худшем случае как 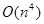 , что нам кажется вполне приемлемым результатом.
, что нам кажется вполне приемлемым результатом.








