 2020-01-14
2020-01-14 106
106
Требование к скорости анализа трафика исключает наивные алгоритмы, типа выписывания параметров каждого соединения из статистики в виде отдельного правила. В таком случае сложность принятия решения по каждому соединению оценивалась бы как 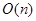 , где n — количество уникальных соединений (обычно это десятки или сотни тысяч объектов).
, где n — количество уникальных соединений (обычно это десятки или сотни тысяч объектов).
Нашу задачу нельзя отнести к классу задач распознавания образов, т.к. прогнозирования не требуется, а необходимо лишь описать на языке правил имеющуюся статистику. Однако некоторые методы решения задач распознавания образов могут послужить основой для решения нашей задачи. Из всего спектра этих методов в нашем случае наиболее эффективными представляются алгоритмы, основанные на построении так называемых логических решающих правил (ЛРП, [4]). Представим себе объекты с разными свойствами в виде точек в многомерном пространстве, каждое измерение которого соответствует определенному свойству. Тогда различные образы объектов будут в этом пространстве являться несовпадающими множествами точек. Если бы одномерные проекции этих множеств не перекрывались, задача распознавания была бы тривиальной. Обычно это требование в чистом виде не выполняется. Проекции точек разных образов на координатные оси образуют перекрывающиеся области. Но области перекрытия на разных координатах выглядят по-разному, что позволяет строить эффективные решающие правила с помощью комбинаций несовпадающих перекрытий на нескольких осях. Правила, описывающие такие комбинации, и называются логическими решающими правилами. Формат ЛРП («если такие-то свойства объекта удовлетворяют таким-то значениям, то принять такое-то решение») похож на формат, в котором обычно записываются инструкции для межсетевых экранов (причем, не только для netfilter, но и для большинства других представителей данного класса ПО). Однако это не единственная причина, почему ЛРП хорошо подходят для нашей задачи. Еще более важными являются следующие соображения:
1. У сетевых соединений имеется большое количество разнотипных признаков. Порты — это целые числа со стандартно заданным отношением порядка, диапазоны IP-адресов — это множества особой структуры со своими правилами принадлежности и вложенности, протоколы — это числовые значения, не подразумевающие какого-либо порядка, и т.д. Но при использовании ЛРП подобное разнообразие типов признаков не вызывает проблем.
2. Как уже говорилось выше, необходимо обеспечить максимально возможное быстродействие готовых анализаторов трафика, при этом скорость построения анализатора не является критичной. ЛРП удовлетворяют этому требованию. Принимать по ним решения просто и быстро.
Метод построения правил, выбранный для реализации в нашей системе, представляет собой модификацию алгоритма DW [5]. Этот алгоритм предполагает, что имеется два образа, и строит дерево правил, позволяющее отделить один образ от другого. Он оперирует понятием элементарного высказывания (ЭВ), под которым подразумевается выражение вида 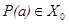 , где Р обозначает некое свойство объекта a, а Х0 — фиксированное множество, называемое пороговым значением. Во многих случаях это представление можно упростить до вида
, где Р обозначает некое свойство объекта a, а Х0 — фиксированное множество, называемое пороговым значением. Во многих случаях это представление можно упростить до вида 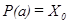 , либо
, либо 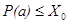 (под Х0 в этом случае понимается уже не множество, а конкретное значение). Будем обозначать элементарные высказывания символом J. Дополнение к J представляет собой обычное логическое отрицание — J. Из ЭВ и их дополнений можно строить конъюнкции разной длины. Набор таких конъюнкций представим в виде дихотомического дерева, в котором каждой ветви соответствует одна конъюнкция. Конечные вершины дерева содержат объекты обучающей выборки, пришедшие в них из корня. Лист признается принадлежащим тому образу, объектов которого в нем скопилось больше.
(под Х0 в этом случае понимается уже не множество, а конкретное значение). Будем обозначать элементарные высказывания символом J. Дополнение к J представляет собой обычное логическое отрицание — J. Из ЭВ и их дополнений можно строить конъюнкции разной длины. Набор таких конъюнкций представим в виде дихотомического дерева, в котором каждой ветви соответствует одна конъюнкция. Конечные вершины дерева содержат объекты обучающей выборки, пришедшие в них из корня. Лист признается принадлежащим тому образу, объектов которого в нем скопилось больше.
При выборе конкретных ЭВ и пороговых значений к ним возникает большой перебор, сокращение которого основано на методе наращивания «от лучшего к лучшему» [6]. Согласно этому методу, дерево ЭВ строится следующим образом. На первом шаге мы имеем одну вершину дерева (корень), которой приписана вся обучающая выборка целиком. Строится наилучшее в смысле некоторого критерия G (см. ниже) элементарное высказывание J(11) и его дополнение J(12). С помощью них выборка делится на две группы: U(11), удовлетворяющая J(11), и U(12), удовлетворяющая J(12). Строится два потомка корневой вершины, «левому» приписано множество U(11), а «правому» — U(12). Соответственно, можно считать, что «левому» ребру приписано ЭВ J(11), а «правому» ребру — J(12). Процесс повторяется для новых вершин.
Это канонический вариант метода. Для нашего случая (описание свойств имеющейся статистики) алгоритм был существенно изменен.
В нашей задаче требуется точное отделение нормальных объектов от аномальных. Множества возможных значений всех свойств (т.е. множества значений разных параметров сетевых соединений) — дискретные и ограниченные, непрерывных параметров нет. Также в статистике нет аномальных объектов. Теоретически, общее количество всевозможных комбинаций параметров соединений конечно, и мы могли бы методом исключения сгенерировать множество аномальных объектов. Однако мощность перебора, который возникает при этом, сводила бы на нет практическую ценность программы. Поэтому, чтобы обеспечить точное отделение нормальных объектов от аномальных, пороговые значения для ЭВ не могут быть произвольными, а должны выбираться только из тех значений, которые встречались в статистике (т.е. нормальные). Тогда мы можем быть уверены, что если в лист дерева попал хотя бы один нормальный объект из статистики, то аномальные объекты (которых мы не знаем) в этот лист попасть не могут. И наоборот, если в лист не попало ни одного нормального объекта, то туда могут попасть только аномальные объекты. Также благодаря выбору только используемых в статистике значений существенно сокращается перебор, т.к. пространство значений некоторых параметров достаточно велико (например, 216 портов), в то же время число реально используемых в обучающей выборке значений обычно гораздо меньше.
Необходимо описать критерий G выбора определенных пороговых значений. В оригинальном DW этот критерий носит статистический характер, в нашем же алгоритме он призван обеспечивать основное свойство дерева: минимизация средневзвешенного времени прохождения соединений через него. Под весом соединения здесь и далее понимается частота его встречаемости в сети. Чтобы удовлетворить этому требованию, при построении очередной вершины мы выбираем такую связку ЭВ и порогового значения для него, которая обеспечивает наиболее равномерное деление текущего подмножества объектов обучающей выборки. Иными словами, две части, получаемые в результате деления, должны как можно меньше отличаться друг от друга по весу. То есть, минимальной должна быть величина 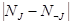 , где
, где 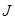 и
и 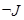 — ЭВ и дополнение к нему, а
— ЭВ и дополнение к нему, а 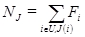 , где U — это текущее подмножество,
, где U — это текущее подмножество, 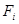 — это количество появлений объекта
— это количество появлений объекта 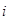 во время сбора статистики, а запись
во время сбора статистики, а запись 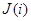 означает, что объект i удовлетворяет J (
означает, что объект i удовлетворяет J (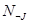 — аналогично). Это гарантирует, что чем чаще пакет появляется в сети, тем быстрее он пройдет через дерево правил.
— аналогично). Это гарантирует, что чем чаще пакет появляется в сети, тем быстрее он пройдет через дерево правил.
Таковы общие теоретические основы работы. В следующих частях будут освещены конкретные технические решения и сопутствующие алгоритмы, использованные для реализации генератора правил, а также других модулей.








