2020-01-14
2020-01-14 127
127
В некоторых протоколах портов нет, поэтому порты и протоколы в нашей системе реализованы в одном классе PortRule (больше подошло бы название ProtocolAndPortRule, но PortRule сложилось исторически). Проверка порта осуществляется только для порта назначения. В протоколе TCP порт отправления (порт на клиенте) задается случайным образом. Для UDP правила его задания оговариваются в спецификации протоколов прикладного уровня. В некоторых из них он также случаен. В других определяется, что клиент должен ждать ответа на том же порту, что и сервер, либо предлагаются более изощренные решения (например, системный сервис resolver протокола DNS или специальный сервис отображения портов в Sun RPC [10]). Общепринятого соглашения не существует, поэтому в текущей версии нашей системы UDP-порт на клиенте считается случайным (как и TCP-порт).
Случайные порты не должны фигурировать в наборе правил. Поэтому нельзя было реализовывать систему на уровне простых пакетов, а необходим уровень соединений. Для отдельно взятого пакета невозможно определить, какой из его портов случайный, а какой — фиксированный. Если этот пакет шел от клиента к серверу, то случайным будет порт отправителя, а если это был ответ сервера клиенту — то получателя.
Работа метода PortRule::compute заключается в следующем. Устанавливается, скольким различным протоколам принадлежат переданные соединения. Если протоколов несколько, то деление проходит по ним. Для каждого протокола подсчитывается, каков суммарный вес соединений, соответствующих ему. В качестве ЭВ выступает выражение 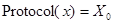 , а пороговым значением
, а пороговым значением 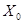 выбирается протокол с наибольшим весом. На этом работа прекращается.
выбирается протокол с наибольшим весом. На этом работа прекращается.
Если протокол один, и он поддерживает порты (TCP или UDP), то деление происходит по портам. ЭВ тогда имеет вид 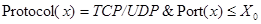 . Это не каноническая форма ЭВ, т.к. есть конъюнкция. Но она необходима, потому что в правиле iptables нельзя задать значение порта, не задав перед этим значение протокола (что логично). Для сокращения перебора в качестве кандидатов на
. Это не каноническая форма ЭВ, т.к. есть конъюнкция. Но она необходима, потому что в правиле iptables нельзя задать значение порта, не задав перед этим значение протокола (что логично). Для сокращения перебора в качестве кандидатов на 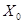 выступают только те номера портов, которые встречаются во множестве. Это дает существенное ускорение работы, ведь пространство значений параметра велико (в худшем случае 216 вариантов), в то же время почти всегда используется гораздо меньше различных портов. Для каждого кандидата запоминается, каков суммарный вес соединений, имеющих порты, меньше или равные ему. Наилучшее деление будет обеспечивать тот порт, у которого этот параметр максимален (иногда это — не единственное возможное решение, но всегда один из равноценных вариантов).
выступают только те номера портов, которые встречаются во множестве. Это дает существенное ускорение работы, ведь пространство значений параметра велико (в худшем случае 216 вариантов), в то же время почти всегда используется гораздо меньше различных портов. Для каждого кандидата запоминается, каков суммарный вес соединений, имеющих порты, меньше или равные ему. Наилучшее деление будет обеспечивать тот порт, у которого этот параметр максимален (иногда это — не единственное возможное решение, но всегда один из равноценных вариантов).
Вместе с подсчетом веса портов подсчитывается и так называемый «строгий вес», то есть вес соединений, имеющих порты строго меньше данного. Если после выбора 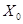 оказывается, что этот параметр для него равен нулю, то ЭВ преобразуется к форме
оказывается, что этот параметр для него равен нулю, то ЭВ преобразуется к форме 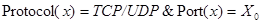 . Это корректно, т.к. выбирался из используемых во множестве портов, и сам он удовлетворяет условию
. Это корректно, т.к. выбирался из используемых во множестве портов, и сам он удовлетворяет условию 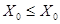 , а значит, весь его вес состоит из соединений со значением порта, в точности равным .
, а значит, весь его вес состоит из соединений со значением порта, в точности равным .
Сложность метода PortRule::compute может быть оценена как 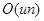 , где u — количество уникальных портов в данном множестве, а n — его мощность. В худшем случае это
, где u — количество уникальных портов в данном множестве, а n — его мощность. В худшем случае это 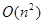 . Но такая сложность достигается, только если каждое соединение во множестве имеет уникальный порт. Это редкая ситуация. Поэтому в большинстве случаев метод выполняется гораздо быстрее.
. Но такая сложность достигается, только если каждое соединение во множестве имеет уникальный порт. Это редкая ситуация. Поэтому в большинстве случаев метод выполняется гораздо быстрее.
Правило масок.
Правило масок (класс MaskRule) описывает свойство принадлежности IP-адреса соединения определенному диапазону (поэтому правильнее было бы назвать его правилом адресов; еще одно не слишком удачное, но прочно закрепившееся название). В зависимости от настройки оно может обрабатывать как адрес отправителя, так и адрес получателя, представляя собой, фактически, два правила. Но нет никакой разницы в алгоритме работы, поэтому в дальнейшем мы будем ссылаться просто на адреса. Адрес соединения является свойством протокола IP, и поскольку выход за рамки семейства протоколов TCP/IP [10] не планируется (во всяком случае, в обозримом будущем), то считается, что IP-адрес есть у любого соединения.
Правило масок может проводить деление соединений, только опираясь на заданные вручную диапазоны адресов. Генерация новых диапазонов не предусмотрена. Это решение требует пояснения. Нет сомнений, что правило масок должно уметь отличать внутренний трафик от внешнего, а значит, информация о диапазонах адресов внутри локальной сети в любом случае необходима. Однако почему бы в дополнение к этим диапазонам не генерировать новые? Возможны два варианта их создания: они либо будут никак не связаны с заданными вручную, либо будут их конкретизировать (сужать). Первый вариант означает попытку эвристически разделить внешнюю сеть на сегменты. Это представляется неразрешимой задачей. Глобальная сеть функционирует по сложным законам, и IP-адреса ее элементов с точки зрения пользователей локальной сети можно считать случайными, не имеющими никакой структуры. Деление их на сегменты приведет к появлению множества бесполезных ветвлений в дереве правил. Внешние IP-адреса могут меняться, что приведет к появлению ложных сообщений об аномальном трафике. К тому же, мощность перебора, необходимого для решения этой задачи, очень велика. Никакой выгоды извлечь не удастся, зато мы получим существенный проигрыш по основным параметрам наборов правил — их количеству и скорости обработки соединений. Поэтому было принято решение никак не обрабатывать адреса, не лежащие ни в одном из заданных вручную диапазонов. Правило масок отключается в вершинах, которым приписаны только соединения с внешними адресами (ниже этот момент будет рассмотрен подробнее). Внешний трафик разбирается только по портам и протоколам.
Попытка конкретизировать диапазоны, заданные администратором, также не кажется хорошей идеей. Если внутри какого-то диапазона нет структуры, то незачем ее искать — это опять же приведет к разбуханию набора правил из-за бесполезных ветвлений и генерации ложных сообщений об аномальном трафике. Если же структура внутри диапазона имеется, то администратор должен сам ее задать. Он может это сделать, ведь структура адресов в локальных сетях почти всегда привязана к их физическому устройству и хорошо известна.
Однако если правило масок встречает множество, у всех соединений которого одинаковый адрес (например, А), и А лежит в одном из заданных диапазонов, то делается естественная конкретизация — вместо этого диапазона используется непосредственно адрес А. Вот откуда появился точный адрес 193.124.208.85 в примере, рассмотренном в главе об общей архитектуре генератора.