 2020-01-14
2020-01-14 178
178
До недавнего времени графы, введенные как научный объект Леонардом Эйлером (1707-1783), Кёнигсбергские мосты, связь элементов многогранника, – в том числе в результате 20 лет проведенных в Пруссии, были чисто математическим объектом с чисто математическими или инженерными задачами вокруг них. В настоящее время они становятся инструментом анализа социальных сетей в глобальном масштабе.
В применении к социальным явлениям, нормальное распределение не является очень распространенным. Степенное распределение (power law) значительно чаще. Например, степени инциденций вершин в социальных сетях (интернет – число ссылок на интернет-страницу, число страниц на веб-сайте, количество посещений, а также такие характеристики как цитируемость или количество телефонных звонков) распределены степенным образом. Если бы были случайны – то должны бы по Пуассону.
Степенной закон впервые возник в работе Лозаннского экономиста итальянского инженера Вильфредо Парето, который построил функцию распределения итальянских семей по доходу (1897). Закон Парето утверждает, что доля семей с доходом, превышающим x. обратно пропорциональна степени x:
P[X > x] ~ x--k.
Он еще формулировал это как закон 80-20: 20% населения обладают 80% богатства. Или торговцы говорят – 80% дохода идет от 20% покупателей. Мне больше всего нравится формулировка польского математика Стефана Банаха, подчеркивающая системный характер этого распределения: «В математике, 5% математиков производят 95% всей математики, но они не произвели бы и 5% математики, если бы не было остальных 95% математиков».
| 
|
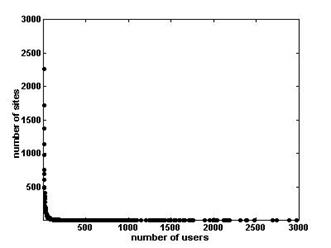
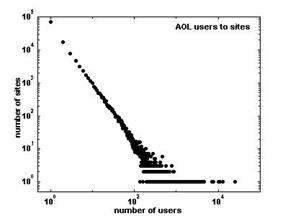
| Fig. 1a Linear scale plot of the distribution of users among web sites | Fig. 1b Log-log scale plot of the distribution of users among web sites |
На Фигуре 1 изображен пример из работы http://www.hpl.hp.com/research/idl/papers/ranking/ranking.html,
показывающий распределение чисел пользователей сети АОЛ в декабре 1997 относительно ранга сайтов по популярности.
Другой способ выразить степенной закон был предложен в работе Гарвардского профессора Джорджа Зипфа, который упорядочил 100 наиболее частых слов по убыванию частоты встречаемости, которую он называл размером (size). Оказалось, что «размер» y обратно пропорционален его рангу r в последовательности: y ~ r -b, где b примерно равно единице (1951). В результате математического анализа обнаружилось, что эта и предыдущая формулировки связаны напрямую. Ключ к доказательству эквивалентности: высказывание «В городе с номером r в упорядочении городов по убыванию населения живет n человек» эквивалентно высказыванию " r городов имеют не менее n жителей".
Фигура 2 изображает график рангов популярности сайтов (ось абсцисс), сопоставленных с количествами посетителей – Зипф работает! Правда, с отклонениями, которые еще нужно объяснить.

|
| Fig. 2Sites rank ordered by their popularity |
Наиболее популярный механизм порождения степенного распределения – предпочтительное присоединение (preferential attachment – “rich gets richer” effect), впервые рассмотренный в работе Удны Юла (Yule 1925) для объяснения распределения числа видов в таксонах растений. Следующие имена: Simon 1955, разработавший модель для объяснения размеров городов, Price 1976, для объяснения распределений цитируемости (в частности ввел понятие scale-free network) и Barabási and Albert 1999, для анализа интернет сети (они-то и ввели термин "preferential attachment").
Социолог Роберт Мертон (1976) предложил называть это явление эффектом Матфея: "Ибо кто имеет, тому дано будет и приумножится; а кто не имеет, у того отнимется и то, что имеет." (Матфей, 13:12). Предпочтительное присоединение не включает часть, относящуюся к изъятию. Урновый процесс, включающий оба механизма, скорее ведет к логнормальному распределению.
При ближайшем рассмотрении оказывается, что реальные социальные сети характеризуются двумя особенностями: (а) короткое в среднем кратчайшее расстояние между вершинами (феномен степеней Эрдеша или Кевина Бекона) и (б) высокая степень кластерности (для данной вершины – отношение числа связей между ее соседями к масимально возможному) - small world phenomenon.
Watts and Strogatz 1998 предложили простую модель для этого явления – сеть вершин окружности, соединенных со всеми своими соседями до r, в которой малая часть соединений случайно произвольно пересоединена, но эта модель слишком упрощена. Ждите новостей!
Возможны и другие модели порождения графов, например, модель организационного управления с линейной и функциональной компонентами.
Визуализация графов.
Граф – сам по себе визуализация, но – когда вершин больше, чем пикселей – проблема! Очень недавнего времени, в пределах 10 последних лет. Различают следующие стратегии:
· Минимизация энергии – сила принимается пропорциональной квадрату связей, и пр.
· Спектральный макет – использование собственных векторов матриц, связанных с графом, в качестве координат.
· Ортогональный макет: представление вершинами целочисленной решетки с минимизацией занятой площади и пересечений между ребрами.
· Симметрический макет – основан на группах симметрии данного графа.
· Древовидный макет: обычно для иерархий или онтологий с малым числом перекрестных ссылок.
· Ациклический макет, основанный на представлении графа как потока связей от источника к стоку.
Вопрос в том, чего хотеть от визуализации – ясно, быстрого и понятного обозрения графа. «Понятный» здесь – еще много работы по уточнению.
История:
Сначала – многоуровневый подход (зуминг). Основные подходы связаны с представлением на плоскости – многомерное шкалирование и собственные вектора. В последнее время – модификации, связанные с учетом локальной структуру связностей. Я бы предложил вернуться к графам и зумингу, но осмысленно, так чтобы подграфы действительно соответствовали каким-то подструктурам в графе – мне кажется, что у меня есть определенный подход, с которым можно надеяться на успех. Этот подход состоит в том, чтобы представить граф с большим числом вершин через граф с малым числом вершин так, чтобы вершины малого графа отвечали множествам вершин большого графа, а наличие дуги в малом графе соответствовало бы очень большому количеству дуг большого графа и отсутствие дуги – очень малому. В отличие от классического кластер-анализа, где надо разбить множество вершин большого графа на сравнительно мало связанные куски, здесь надо так разбить, чтобы все или почти все дуги большого графа оказались соединяющими одни и те же группы (задача о выявлении подсистем и их связей).
 | |||
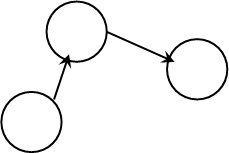 | |||
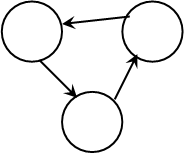
Фигура 3. Типичные структуры больших графов: линейная и циклическая.








